🚩前言
- 🐳博客主页:😚睡晚不猿序程😚
- ⌚首发时间:2023.6.8
- ⏰最近更新时间:2023.6.8
- 🙆本文由 睡晚不猿序程 原创
- 🤡作者是蒻蒟本蒟,如果文章里有任何错误或者表述不清,请 tt 我,万分感谢!orz
- 🚩前言
- 1. 内容简介
- 2. 论文浏览
- 3. 图片、表格浏览
- 4. 引言浏览
-
5. 方法
- 5.1 模型结构
-
6. 实验
- 6.1 实验设置
- 6.2 实验结果
-
6.3 消融实验
- 4. Effect of the multi-scale restoration modulator
-
6. 总结、预告
- 6.1 总结
- 6.2 预告
1. 内容简介
论文标题:Uformer: A General U-Shaped Transformer for Image Restoration
发布于:CVPR 2021
自己认为的关键词:Transformer、Unet
是否开源?:https://github.com/ZhendongWang6/Uformer
2. 论文浏览
论文动机:
- 目前对于图像修复(image restoration) 的 SOTA 模型都是基于 ConvNet 的,其把握全局信息的能力不足
- 一些针对上面的问题的改进方式引入注意力层,但是由于其平方级别的复杂度导致只能使用较少层数
本文工作:
-
Uformer:搭建了分层级的 encoder-decoder 模型(类似 U-Net)
-
LeWin:基于 Swin Transformer 的滑动窗口自注意力上在 FFN 添加 DWConv
-
可学习的多尺度修复模块:用于调整 decoder 部分的特征,使其自适应不同噪声
一个和 Token 维度相同的可学习参数
完成效果:在去噪、去雨、去模糊等 low level 任务效果显著
3. 图片、表格浏览
图一
模型性能图,看起来在相同计算量下比 Unet 性能要好
奇怪的是怎么没有和 Swin Transformer 碰碰
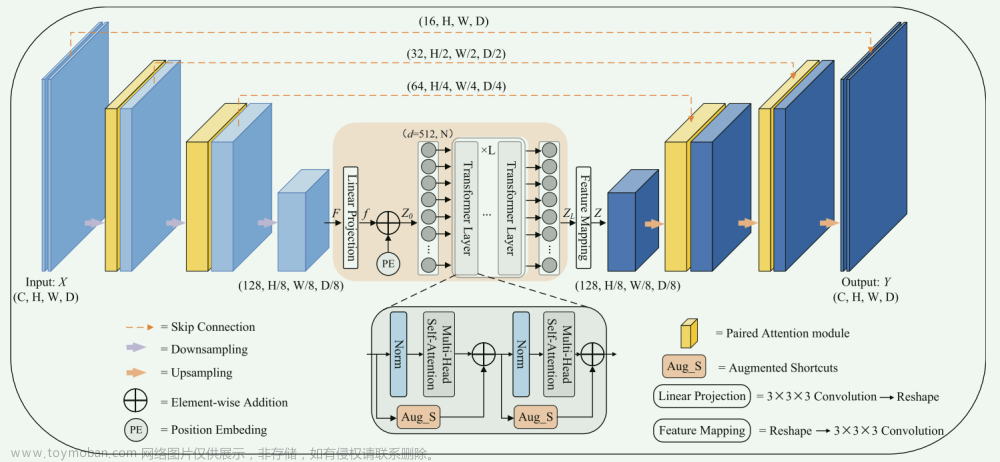
图二
模型架构图,可以看到组成了一个 Unet 架构,在 decoder 分支使用了 Modulators 调整特征的表示
图三
局部增强的 FFN,在 1x1 卷积中间引入了 DWConv
感觉可以像 ConvNeXt 一样挪到 1x1 卷积前面,可以进一步降低参数量
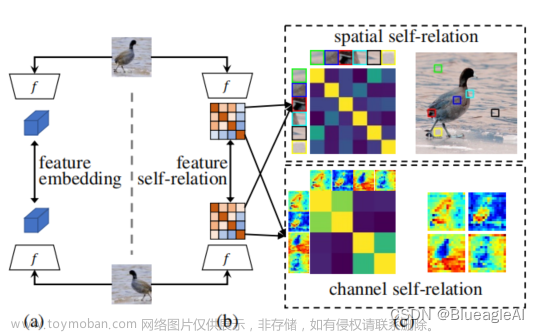
图四
Modulator 的效果,看起来确实不错
Token 的表示确实很轻松就可以引入某些信息
图五
模型去噪效果
4. 引言浏览
本文重心:在不同分辨率上使用自注意力,从而恢复图像信息——提出了 Uformer,基于 U-Net,但是保持了他的 味道 ,只是改变了 backbone(跳跃连接啥的没有变)
两个设计
-
Locally enhanced Window:字如其名
特征图分辨率改变,但是窗口大小不变
在 Transformer FFN 的两个全连接层之间添加 depth-wise 卷积层 -
learnable multi-scale restoration modulator:用于学习图像的 退化方式
作为一种多尺度的空间偏置,来在 decoder 中调整图像特征——可以可学习的,基于窗口的 tensor 将会直接加到特征中去,来调整这些特征,来为重建提供更多信息
自由阅读
5. 方法
5.1 模型结构
encoder:
-
使用 3x3 LeakyReLU 卷积对输入图像进行处理,得到(C,H,W)大小图像,通过此抽取底层特征
-
接着就是和 UNet 一样,要经过 K 个 encoder stages,每个 stage 由一个 LeWin block 和一个下采样层组成
具体而言,LeWin block 输入输出分辨率相同,下采样层先把图片转化为 2D 的(从 Token 中恢复图像)然后使用 4x4,stride=2 的卷积降低分辨率,翻倍特征通道数
-
在 encoder 的最后添加上一个 bottleneck stage,由一系列 LeWin Transformer block 堆叠而成
在这里可以使用全局自注意力,相比之前的窗口自注意力可以有更强的建模能力
decoder:
-
同样 K 个 stage,包含若干个 Transformer blcok 以及一个上采样层
具体而言,使用 2x2 stride=2 的转置卷积来做上采样,翻倍分辨率,减半特征通道数量 -
接着,和之前的部分做级联,然后一直计算下去
-
经过了 K 个 stage,将其重新转化为 2D 表示,并使用一个 3x3 卷积将其特征通道数重新变为 3,然后进行一个残差连接得到输出
这里的上下采样选择转为图像表示再使用卷积进行操作
LeWin Transformer Block
ViT 两个缺陷:
- 全局自注意力
- 难以把握 local dependencies
进行了改进,结构如下
两个核心设计:
- 不重叠的基于窗口的自注意力(W-MSA)
- 局部强化前向网络(LeFF)
LeFF
- 首先进行线性映射
- 转化为图像表示,进行 3x3 卷积
- 转为 token,然后映射为原本的维度,进行残差连接
Multi-Scale Restoration Modulator
这里说到,因为不同的图像退化方式会有不同的扰动模式,为了让 Uformer 可以解决这些不同的扰动,使用了一个轻量化的恢复模块,它可以标定输出的特征,鼓励模型使用更多的细节来恢复图像
在每一个块中,这个调制器是一个 tensor ,大小为(M,M,C),用法和偏置一样,在计算自注意力之前直接加到每一个窗口中就可以了。
在去模糊和图像去噪方面可以改善效果,尤其是在去运动模糊方面和噪声方面可以得到更好的结果
这里说,和 StyleGAN 中添加随机噪声的思路是一致的,所以这个 StyleGAN 之后也可以去看一下
6. 实验
6.1 实验设置
损失函数
这里是选择了一个 Charbonnier Loss 作为损失函数
优化器:Adam(0.9, 0.999), weight decay 0.02; lr 2e-4;使用余弦衰减
数据增强:水平翻转,旋转 90,180,270
模型架构
窗口大小 4x4
评价指标
- PSNR
- SSIM
使用 YUV 的 Y 通道进行计算
6.2 实验结果
Real Noise Removal
第一项任务,去噪
数据集:SIDD,DND
对比了 8 个模型,拿到了最佳成绩
Motion blur removal
任务二:去除动态模糊
数据集:GoPro(训练),HIDE(合成的数据集),GoPro(测试集),RealBlur-R/J
在 GoPro 上对之前的 SOTA 方法实现了全面的超越(PSNR 多了 0.3 个点,SSIM 多了 0.01)其他的数据集也都比之前的 SOTA 要好
defocus Blur Removal
任务三:去失焦
数据集:DPD
全面超越,PSNR 多了好几个点!直接按照一位数算的
Real Rain Removal
离谱啦,多了 3 个点
6.3 消融实验
1. Transformer vs convolution
将其中的 Tr 替换为 CNN(ResBlock),设计了三个不同大小的 UNet
效果不错,参数量更小的情况下能得到更好的效果,但是我觉得差距好像也不是很大?
哦但是那个 B 模型就差距比较大了,多了 0.1 个点
2. Hierarchical structure vs single scale
使用 ViT-based 架构,单一尺度,用于图像去噪,在开始和结束的时候使用两层卷积来提取特征以及还原图像,其中使用 12 层 Tr block,隐藏特征维度为 256,patch 大小 16x16,得到的效果不好
ViT 的单一尺度对这种任务效果肯定不好,ViT 似乎是一个 近视眼 ,16x16 的 patch 划分让他具有了这种特性,可以看成是低通滤波器
3. Where to enhance locality
对比了是否进行局部性强化的效果
可以看到,在自注意力中引入局部强化会导致效果变差,但是如果在 FFN 中引入局部强化会得到一个更好的效果
对 Token 做卷积可以看成是一个超大感受野的扩张卷积
4. Effect of the multi-scale restoration modulator
效果显著,如果看他的效果对比,可以看的更为明显
Is Window Shift Iportant?
附录内容
使用滑动窗口,带来了微小的提升
但是根据我自己跑代码的情况,我使用了滑动窗口带来的提升挺大的(2-3 个点 PSNR),约等于进行了一次感受野的扩大
6. 总结、预告
6.1 总结
使用 Transformer 作为 backbone 的 U-Net 网络,具有两个创新点
- 基于窗口的自注意力,自注意力和卷积联合使用,随着网络的加深模型可以获得更大的 感受野
- 可学习的 multi-scale restoration modulator,仅仅使用一个加法取得了一个不错的效果
- 卷积和 MLP 相结合,构成了一个 局部性强化 方法,更好的应用图像的局部信息
6.2 预告
打算之后更新一下关于 Transformer 的论文阅读了文章来源:https://www.toymoban.com/news/detail-476161.html
好久没有整理自己的笔记然后更新了iai,屯了一大堆的论文笔记文章来源地址https://www.toymoban.com/news/detail-476161.html
到了这里,关于【论文阅读】Uformer:A General U-Shaped Transformer for Image Restoration的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!