✨✨欢迎来到T_X_Parallel的博客!!
🛰️博客主页:T_X_Parallel
🛰️专栏 : 数据结构初阶
🛰️欢迎关注:👍点赞🙌收藏✍️留言
前言
这小猫真好看

言归正传,通过上篇有关顺序表和链表的博客,可以了解到线性表的一些大致特征,这篇博客主要就是来了解线性表中的栈和队列。(如果没有看过本博主上篇有关链表的博客,可以先去看看上篇博客,对学习本篇博客会有一定的帮助)
<数据结构初阶(用C语言实现简单数据结构)-- 手搓顺序表、链表>
💕链表与栈和队列的关系
栈和队列是一种数据结构,而链表是一种存储数据的方式。栈和队列都可以用链表来实现。
🎭栈使用后进先出(LIFO)的方式存储数据,即最后进入栈中的元素最先被取出。链表实现栈可以在链表头部插入元素和删除元素,这样最后进入的元素就位于链表头部,最先被取出。
🎭队列使用先进先出(FIFO)的方式存储数据,即最先进入队列的元素最先被取出。链表实现队列可以在链表尾部插入元素,在链表头部删除元素,这样最先进入的元素就位于链表头部,最先被取出。
因此,链表可以用于实现堆栈和队列,使其具有相应的特性。
下面将对两种数据结构进行详细剖析
1.栈
✨栈的概念及结构
栈(Stack)是一种基本的数据结构,它是一种只能在一端进行插入和删除操作的线性表。栈的特点是LIFO(Last In First Out)即后进先出,也就是最后压入栈的元素最先弹出。
栈有很多实际应用,包括函数调用、表达式求值、操作系统的进程调度、缓存等。
栈的两个基本操作是push(压栈)和pop(出栈)操作。
🐾push操作将元素压入栈中,即向栈顶端插入元素;
🐾pop操作将元素弹出栈外,即弹出栈顶端的元素。

下面的动图可以更直观的理解栈的出入栈

✨栈的实现
通常栈的实现有两种方式:数组和链表。数组实现栈需要指定栈的大小,当栈满了就不能再向栈中添加元素了。链表实现栈不需要事先指定栈的大小,可以动态地添加和移除节点。
在实现栈之前需要想想定义的结构体中需要哪些成员变量,再想想实现栈需要实现栈的哪些功能
首先是结构体的声明
从上面的声明来看,结构体中需要三个成员变量,其实和链表差不多。
接下来是栈的功能实现
栈的功能实现大致可以分为七个部分(初始化、入栈、出栈、判空、取栈顶元素、取有效元素个数、栈销毁)
上面是功能函数的声明,这样我们能在实现过程中清楚自己需要实现哪些功能函数
我相信只要C语言学的扎实(特别是结构体和指针部分)并且链表自己实现过,其实栈的实现都是小菜一碟,所以每个功能函数具体如何实现的我就不一一讲解,C语言学到这里我相信自己也有看懂代码的能力
下面是完整栈实现代码
//Stack.h
// 支持动态增长的栈
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top; // 栈顶
int capacity; // 容量
}Stack;
// 初始化栈
void StackInit(Stack* ps);
// 入栈
void StackPush(Stack* ps, STDataType data);
// 出栈
void StackPop(Stack* ps);
// 获取栈顶元素
STDataType StackTop(Stack* ps);
// 获取栈中有效元素个数
int StackSize(Stack* ps);
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
int StackEmpty(Stack* ps);
// 销毁栈
void StackDestroy(Stack* ps);
//Stack.c
#include "Stack.h"
// 初始化栈
void StackInit(Stack* ps)
{
assert(ps);
STDataType* tmp = (STDataType*)malloc(sizeof(STDataType) * 4);//动态开辟空间
if (!tmp)//必要的检查
{
perror("malloc failed");
return;
}
ps->a = tmp;
ps->top = -1;
ps->capacity = 4;
}
// 入栈
void StackPush(Stack* ps, STDataType data)
{
assert(ps);
if (ps->top + 1 == ps->capacity)//如果空间不够需要扩容
{
ps->a = (STDataType*)realloc(ps->a, sizeof(STDataType) * (ps->capacity + 2));
if (!ps->a)
{
perror("realloc failed");
return;
}
ps->capacity += 2;
}
ps->top++;
ps->a[ps->top] = data;
}
// 出栈
void StackPop(Stack* ps)
{
assert(ps);
assert(!StackEmpty(ps));
ps->top--;
}
// 获取栈顶元素
STDataType StackTop(Stack* ps)
{
assert(ps);
assert(!STIsempty(ps));
return ps->a[ps->top];
}
// 获取栈中有效元素个数
int StackSize(Stack* ps)
{
return ps->top;
}
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
int StackEmpty(Stack* ps)
{
if (ps->top == -1)
return 1;
return 0;
}
// 销毁栈
void StackDestroy(Stack* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->top = -1;
ps->capacity = 0;
ps = NULL;
}
注:上述代码没有引用必要头文件,如需使用请自行引用;上述代码采用声明与定义分离的方式实现的,且无main函数,如需使用请自行补充完整
接下来是一些关于实现中可能会遇到的问题
1️⃣在代码中,初始化时 top 变量的值可以被初始化为 0 或 -1,这两种方式都可以实现栈的初始化操作。但它们的细微差别仍然存在
✨当 top 被初始化为 0 时,栈中第一个元素实际上是存储在栈底下标为 0 的位置,此时栈的容量就是数组 stack 的长度。当一个元素被入栈时,top++ 表示栈顶指针向上移动一个位置,指向下一个可以存储元素的位置。当有元素被出栈时,top-- 表示栈顶指针向下移动一个位置,指向栈顶元素。
✨当 top 被初始化为 -1 时,栈中第一个元素实际上是存储在栈底下标为 0 的位置,且栈顶指针 top 的初始值为 -1。当一个元素被入栈时,由于 top++ 的作用,栈顶指针先向上移动一个位置变为 0,然后将元素存储在下标为 0 的位置上。当有元素被出栈时,首先将下标为 0 的元素弹出栈,然后将栈顶指针向下移动一个位置,变成 -1。
总的来说,这两种方式的主要区别在于栈底元素的位置不同,但它们的基本操作是一样的。
2️⃣在出栈操作中直接top–即可完成出栈操作
直接top–而不是先将top位置的元素置空再top–是因为要将top位置置空应该置为什么值(这是动态开辟的数组,不像链表,无法释放单个空间)
直接top–,是因为其他操作都是用top来访问元素,则top–就无法访问到原top位置的元素,间接的实现了出栈操作
2.队列
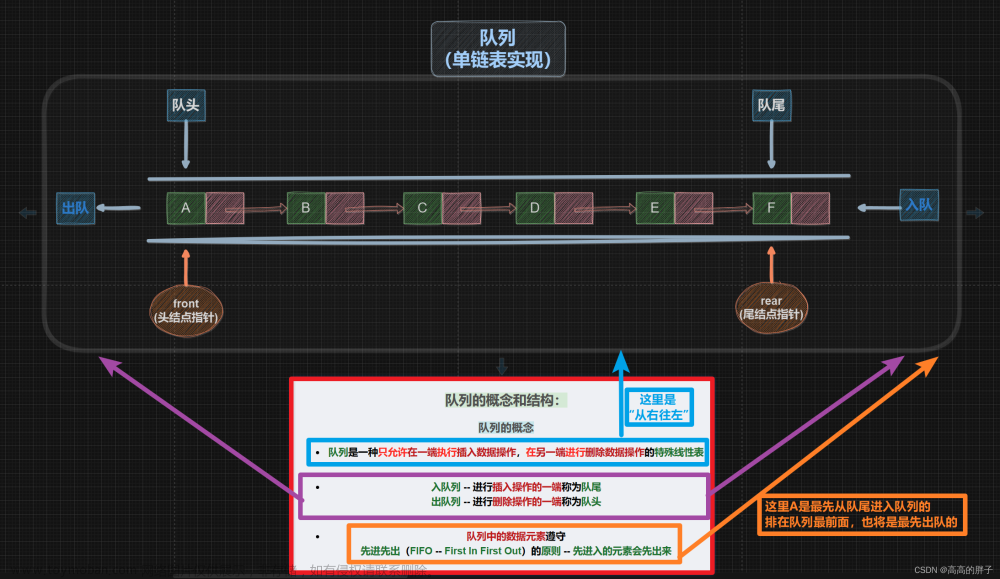
✨队列的概念及结构
队列是一种特殊的数据结构,它是一系列元素的有序集合,它的主要特点是新元素只能从一端(队尾)添加,已有元素只能从另一端(队头)删除。因此,队列是一种先进先出(FIFO)的数据结构。队列可以使用数组或链表实现。
队列可以用于多种场景,比如实现消息队列、任务队列、事件处理队列等。在计算机科学中,队列是非常重要的一种基础数据结构,它具有良好的性能和可扩展性,能够高效地处理大量数据。

从上面两张动图可直观地看出和了解队列的结构和先进先出的特点,为用C语言实现队列打下基础
✨队列的实现
队列也可以数组和链表的结构实现,使用链表的结构实现更优一些,因为如果使用数组的结构,出队列操作是在数组头上出数据,效率会比较低,所以实现一般使用链表结构。
队列常用的操作包括:
🖼️ 入队:将新元素插入到队尾。
🖼️ 出队:从队头删除一个元素。
🖼️ 取队头:获取队头元素,但不删除。
🖼️ 取队尾:获取队尾元素,但不删除。
🖼️ 判空:判断队列是否为空。
🖼️ 判满:判断队列是否已满。


上面是结构体和函数的声明,接下来是函数的定义
// 初始化队列
void QueueInit(Queue* q)
{
assert(q);
q->head = q->tail = NULL;
q->size = 0;
}
// 队尾入队列
void QueuePush(Queue* q, QDataType data)
{
assert(q);
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (!newnode)
{
perror("malloc failed");
return;
}
newnode->next = NULL;
newnode->val = data;
if (q->head == NULL)
{
q->head = q->tail = newnode;
}
else
{
q->tail->next = newnode;
q->tail = newnode;
}
q->size++;
}
// 队头出队列
void QueuePop(Queue* q)
{
assert(q);
assert(!QueueEmpty(q));
if (q->head->next == NULL)
{
free(q->head);
q->head = q->tail = NULL;
}
else
{
QNode* next = q->head->next;
free(q->head);
q->head = next;
}
q->size--;
}
// 获取队列头部元素
QDataType QueueFront(Queue* q)
{
assert(q);
assert(!QueueEmpty(q));
return q->head->val;
}
// 获取队列队尾元素
QDataType QueueBack(Queue* q)
{
assert(q);
assert(!QueueEmpty(q));
return q->tail->val;
}
// 获取队列中有效元素个数
int QueueSize(Queue* q)
{
assert(q);
return q->size;
}
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
int QueueEmpty(Queue* q)
{
assert(q);
return QueueSize(q) == 0;
}
// 销毁队列
void QueueDestroy(Queue* q)
{
assert(q);
QNode* cur = q->head;
while (cur)
{
QNode* next = cur->next;
free(cur);
cur = next;
}
q->head = q->tail = NULL;
q->size = 0;
}
回过头看,其实链表、栈和队列的实现差别不是很大,所以只要自己实现过链表,基本上栈和队列就都能实现出来
另外扩展了解一下,实际中我们有时还会使用一种队列叫循环队列。如操作系统课程讲解生产者消费者模型时可以就会使用循环队列。环形队列可以使用数组实现,也可以使用循环链表实现。下面会有循环队列实现的oj题
3.相关oj题
🎭括号匹配问题
<Leetcode-20.有效的括号>

根据题目描述及上方动图解析可知:
有效括号字符串的长度,一定是偶数!
右括号前面,必须是相对应的左括号,才能抵消!
右括号前面,不是对应的左括号,那么该字符串,一定不是有效的括号!
具体答案可参考题解<题解>(做题一定要先自己想一想做一做再参考题解!!!)
🎭设计循环队列
<Leetcode-622.设计循环队列>
实现循环队列有两种方法:数组和队列
方法一:数组
关于循环队列的概念可以参考:「循环队列」,我们可以通过一个数组进行模拟,通过操作数组的索引构建一个虚拟的首尾相连的环。在循环队列结构中,设置一个队尾rear与队首front,且大小固定,结构如下图所示:

时间复杂度:初始化和每项操作的时间复杂度均为 O(1)。
空间复杂度:O(k),其中 k 为给定的队列元素数目。
方法二:链表
我们同样可以用链表实现队列,用链表实现队列则较为简单,因为链表可以在 O(1) 时间复杂度完成插入与删除。入队列时,将新的元素插入到链表的尾部;出队列时,将链表的头节点返回,并将头节点指向下一个节点。
循环队列的属性如下:
🐾head:链表的头节点,队列的头节点。
🐾tail:链表的尾节点,队列的尾节点。
🐾capacity:队列的容量,即队列可以存储的最大元素数量。
🐾size:队列当前的元素的数量
时间复杂度:初始化和每项操作的时间复杂度均为 O(1)。
空间复杂度:O(k),其中 k 为给定的队列元素数目。
讲述了两种方法后,我们来看看两种方法的区别:
数据结构:循环队列用数组实现时,需要声明一个固定大小的数组来存储队列元素,而用链表实现时,则需要声明一个结构体来表示节点,并用指针来连接各个节点。
增删操作效率:在循环队列中,数组实现的增删操作效率较高,因为可以直接通过下标访问元素。而链表实现的增删操作效率较低,因为需要通过指针遍历整个链表来找到相应的节点。
具体答案可参考题解<题解>(做题一定要先自己想一想做一做再参考题解!!!)
✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨
如果还没自己动手实现过栈和队列,那么可以自己写一下下面两道oj题,写完即可更深地理解栈和队列的结构及关系
🎭用队列实现栈
<Leetcode-225.用队列实现栈>
🎭用栈实现队列
<Leetcode-232.用栈实现队列>
总结
这差不多是本篇博客的尾声了,我浅浅地总结一下栈和队列
栈的优点:
- 栈具有后进先出(LIFO)的特性,可以方便地实现一些递归、回溯等算法。
- 栈具有一定的保护作用,可以避免某些数据被误操作或意外更改。
- 栈的实现简单,可以用数组或链表等数据结构实现。
栈的缺点:
- 栈只能在一端进行插入和删除操作,不适合于一些需要频繁的随机访问操作。
队列的优点:
- 队列具有先进先出(FIFO)的特性,在实现广度优先搜索等算法时非常方便。
- 队列的实现简单,也可以用数组或链表等数据结构实现。
队列的缺点:
- 队列在处理数据时必须按照顺序,无法跳过某些数据进行操作,不适合于一些需要频繁的随机访问操作。
- 在队列应用中,往往需要进行超时或阻塞操作,这增加了队列的实现难度。
栈与队列的区别:
- 存储方式:栈使用线性结构(数组或链表)存储数据,而队列使用线性结构(数组或链表)或链式结构存储数据。
- 操作方式:栈只能在一端进行插入和删除操作,而队列只能在两端进行插入和删除操作。
- 特性:栈具有后进先出(LIFO)的特性,而队列具有先进先出(FIFO)的特性。
- 应用场景:栈适用于递归、回溯等算法,以及在需要反转操作的情况下。队列适用于广度优先搜索、缓存队列等情况。
学完栈和队列基本上对线性表有了一定的认识和了解,接下来将要学的是堆(二叉树),小小剧透一下
最后再来一张美图,放松一下疲惫的眼睛
是心动的感觉

 文章来源:https://www.toymoban.com/news/detail-476445.html
文章来源:https://www.toymoban.com/news/detail-476445.html
专栏:数据结构初阶
都看到这里了,留下你们的珍贵的👍点赞+⭐收藏+📋评论吧文章来源地址https://www.toymoban.com/news/detail-476445.html
到了这里,关于数据结构初阶(用C语言实现简单数据结构)--栈和队列的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!