0.前言
这里是limou3434的一篇个人博文,感兴趣可以看看我的其他内容。本次我给您带来的是树的相关只是,并且把堆这一数据结构做了实现,后面还有大量的oj题目。但是树重点也就在这十多道oj题目中,您可以尝试着自己做一下,或者看看力扣的其他题友的解法。(这里面有的公式推导过程转化到csdn比较麻烦,所以有的时候可能在公式推导的过程中,会显示出奇怪的结果……若是有,则留在评论区,我会及时进行更正)
1.树的基础概念和相关术语
1.1.一般树
树时一种非线性结构,由n(n>=0)个有限节点构成一个具有层次关系的集合,看起来就像一棵倒挂的树
- 有一个特殊的节点,称为根节点,根节点没有父亲节点
- 除根节点外的其余节点被分为M(M>0)个互不相交的集合T1、T2、…Tm,其中每一个集合T(1<=i<=m)又是一棵结构与树类似的子树,每个子树的根节点有且只有一个前驱,可以有0或多个后继
- 因此树是递归定义的
树的构成 = 父节 点 1 + N 1 棵子树 = 父节 点 1 + ( 父节 点 2 + N 2 棵子树 ) + ( 父节 点 3 + N 3 棵子树 ) + ( 父节 点 4 + N 4 棵子树 ) + … + ( 父节 点 N + 1 + N N + 1 棵子树 ) ) 树的构成 = 父节点_1 + N_1 棵子树= 父节点_1 + (父节点_2 + N_2 棵子树) + (父节点_3 + N_3 棵子树) + (父节点_4 + N_4 棵子树) + … + (父节点_{N+1} + N_{N+1} 棵子树)) 树的构成=父节点1+N1棵子树=父节点1+(父节点2+N2棵子树)+(父节点3+N3棵子树)+(父节点4+N4棵子树)+…+(父节点N+1+NN+1棵子树))

判断树的时候需要注意,树的子树是不会相交的,而且除了根节点,每一个节点都有且只有一个父亲节点
1.2.二叉树
有的时候我们不需要度很大的树,因此就有了二叉树。二叉树的度最大为2,由一个根节点加上左右子树构成(递归定义)
1.2.1.完全二叉树
假设有一棵二叉树,高度为h,则前h-1层都是满的,最后一层是不满的,但呈现连续的状态。则我们称这棵二叉树为完全二叉树。
1.2.2.满二叉树
满二叉树就是二叉树的每一层都是满的(每一层都塞满了节点),而可以认为满二叉树是特殊的完全二叉树
1.3.相关术语
- 度:一个节点含有的子树个数称为该节点的度
- 根节点:根节点没有前驱节点,一棵树有且只有一个根节点
- 叶节点/终端节点:叶节点没有后驱节点,其“度”为零,一棵树最少也有一个叶节点
- 分支节点/非终端节点:“度”不为零的节点都叫分支节点
- 节点的层次:从根开始定义起,根为第一层,根的子节点为第二层……
- 树的高度/深度:树中节点最大层次数即树的深度
- 节点之前的亲缘关系
- 父亲节点/双亲节点:若一个节点含有子节点,则这个节点时其子节点的父亲节点
- 兄弟节点:具有相同父亲节点的子节点互称为兄弟节点
- 孩子节点:一个节点若含有子树根节点称为节点的孩子节点
- 堂兄弟节点:双亲在同一层的节点互为堂兄弟
- 节点的祖先:从根节点到该节点所经分支上的所有节点,除了它本身都是他的祖先。其中根节点时所有非根节点的祖先
- 子孙:以某节点为根的子树中任一节点都称为该节点上的子孙
- 森林:由m(m>0)棵互不相交的多棵树的集合称为森林(在数据结构并查集就会用到)(森林的概念在并查集中会用到)
1.4.树的应用
树的应用最经典的地方是在文件系统上,可以叫系统里的所有文件目录为一颗“目录树”。另外,二叉树不是真的为了存储数据,而是优化搜索,比如:搜索二叉树(在搜索二叉树里,任何一棵树,左子树都比根要小,右子树都比根要大,这个特性特别适合搜索,最多查找它的高度K次,时间复杂度为O(N),而左右平衡节点个数还能影响搜索效率,这就涉及到平衡树:AVL树、红黑树、B树(多叉搜索树、数据库原理))
2.树的多种存储结构
2.1.暴力存储法
理论上来说如果明确树的最大度,的确可以暴力穷举,但是对于有新数据插入的树这个方法就有些差劲了,因为谁也不知道到底最终会插入多少个子节点,更加不知道度的最大值是否会产生变化
typedef struct TreeNode
{
int data;//存储节点的数据
struct TreeNode* child_1;//存储节点指向的子孩子1
struct TreeNode* child_2;//存储节点指向的子孩子2
struct TreeNode* child_3;//存储节点指向的子孩子3
//…
}TreeNode;
2.2.亲缘关系存储法
2.2.1.双亲表示法
- 存储原理:使用数组依次存储树中各个节点,每个节点只存储数据和指向双亲节点的指针或下标,只不过这个方法用的比较少。
typedef struct TreeNode
{
int data;//存储节点的数据
int parenti;
}TreeNode;
//然后创建一个数据元素是TreeNode的结构体数组

- 结构优势和劣势(以后再谈)
2.2.2.孩子表示法
- 存储原理:使用数组依次存储树中各个节点。节点不止存储数据,还分别配备了一个链表/顺序表,用于存储各节点的孩子节点位于顺序表中的位置
typedef struct TreeNode
{
int data;//存储节点的数据
ListNode* childArr;//或者使用顺序表SeqList childArr;
}TreeNode;

- 结构优势和劣势(以后再谈)
2.2.3.孩子兄弟表示法
- 存储原理:每一个节点除了存储自己携带的数据,还携带了指向兄弟节点的指针,以及指向第一个孩子节点的指针。这个结构很优秀,无论度有多大都可以存储起来,并且可以将多叉树转化为一种类二叉树的存在。

- 结构优势和劣势(以后再谈)
3.二叉树的相关性质
3.1.一般二叉树性质
3.1.1.性质一:深度 K K K与节点数 N N N的关系 [ f ( K , N ) ] [f(K,N)] [f(K,N)]
把一棵二叉树的 N N N个节点想象成两个极端:安全二叉树(最少)和斜树(最多),因此K的范围就是 [ ⌊ l o g 2 ( N ) ⌋ + 1 ( ⌊ x ⌋ 表示取不小于 x 的最大整数) , N ] [⌊log_2(N)⌋ + 1(⌊x⌋表示取不小于x的最大整数), N] [⌊log2(N)⌋+1(⌊x⌋表示取不小于x的最大整数),N]这个全闭区间
3.1.2.性质二:层阶 i i i的max节点数 N N N
若规定根节点的层数为1,则一颗非空二叉树的第i层最多拥有节点数 N N N为 “ 2 i − 1 ” “2^{i - 1}” “2i−1”
3.1.3.性质三:深度 K K K的max节点数 N N N
若规定根节点的层数为1,则深度为 K K K的二叉树的最大节点数 N N N为 “ ( 2 K ) − 1 ” “(2^K) - 1” “(2K)−1”
3.1.4.性质四:“度0节点数量 n 0 n_0 n0”和“度2节点数量 n 2 n_2 n2”的关系 [ f ( n 0 , n 2 ) ] [f(n_0,n_2)] [f(n0,n2)]
对任何一棵二叉树,如果度为0的分支节点个数为n0,度为2的分支节点个数为n2,则有关系式 “ n 0 = = n 2 + 1 ” “n0 == n2 + 1” “n0==n2+1”
1.假设有n个节点,其中度为0的节点有n0个、度为1的节点有n1个、度为2的节点有n2个,那么 “ n 0 + n 1 + n 2 = = n ” “n0 + n1 + n2 == n” “n0+n1+n2==n”①
2.假设所有的祖先节点和其拥有的所有子节点都有连线,则向上看除了根节点,每一个节点拥有一根连线,那么总共有 “ n − 1 ” “n - 1” “n−1”条连线。而由于度为0的节点向下引出0根线,度为1的节点向下引出1根线,度为2的节点向下引出2根线。则 “ n − 1 = = 2 ∗ n 2 + 1 ∗ n 1 + 0 ∗ n 0 “n - 1 == 2 * n_{2} + 1 * n_{1} + 0 * n_0 “n−1==2∗n2+1∗n1+0∗n0”,即 “ n − 1 = = 2 ∗ n 2 + n 1 ” “n - 1 == 2 * n_{2} + n_{1}” “n−1==2∗n2+n1”②
3.结合①和②得出 “ n 0 = = n 2 + 1 ” “n_{0} == n_{2} + 1” “n0==n2+1”
3.2.完全二叉树性质

3.2.1.性质一:深度 K K K与节点数 N N N的关系 [ f ( K , N ) ] [f(K,N)] [f(K,N)]
对于完全二叉树,设其具有 N N N个节点,其深度 K K K为 “ ⌊ l o g 2 ( N ) ⌋ + 1 ” “⌊log_2(N)⌋ + 1” “⌊log2(N)⌋+1”(⌊x⌋表示取不小于x的最大整数)
1.对于完全二叉树来说,其总节点数有 N N N,深度为 K K K, “ ( 2 K − 1 ) − 1 + 1 < = N < = ( 2 K ) − 1 ” “(2^{K - 1}) - 1 + 1 <= N <= (2^K) - 1” “(2K−1)−1+1<=N<=(2K)−1”,即 “ ( 2 K − 1 ) < = N < = ( 2 K ) ” “(2^{K - 1}) <= N <= (2^K)” “(2K−1)<=N<=(2K)”
2.两边同时取对数,得到 “ k − 1 < = l o g 2 ( N ) < k ” “k - 1 <= log_2(N) < k” “k−1<=log2(N)<k”,得到 “ l o g 2 ( N ) < k < = l o g 2 ( N ) + 1 ” “log_2(N) < k <= log_2(N) + 1” “log2(N)<k<=log2(N)+1”,这就会有一个类似高斯函数的问题,则k的取值可以表示为 “ ⌊ l o g 2 ( N ) + 1 ⌋ = = ⌊ l o g 2 ( N ) ⌋ + 1 ” “⌊log_2(N) + 1⌋ == ⌊log_2(N)⌋ + 1” “⌊log2(N)+1⌋==⌊log2(N)⌋+1”。实际上也可以根据“完全二叉树 = 满二叉树 + 一层不完整子节点”来得出节点的范围数,逆推完全二叉树的高度
3.2.2.性质二:“ 节点 i n d e x 节点index 节点index”和“ 子节点 i n d e x 子节点index 子节点index”的关系
对一颗有 n n n个节点的完全二叉树,对每个节点进行编号(从1开始,从左到右,从上到下)对任意节点 i i i都有:
- 若 “ i = 1 ” “i=1” “i=1”,则节点 i i i是根,没有双亲节点;若 i > 1 i > 1 i>1,则节点i的双亲节点是 ⌊ i / 2 ⌋ ⌊i/2⌋ ⌊i/2⌋
- 若 “ 2 ∗ i > n ” “2*i>n” “2∗i>n”,则节点i没有左孩子,否则左孩子为 2 ∗ i 2*i 2∗i
- 若 “ 2 ∗ i + 1 > n ” “2*i+1>n” “2∗i+1>n”,则节点i没有右孩子,否则左孩子为 2 ∗ i + 1 2*i+1 2∗i+1
实际上还可以理解为:
1.父节点找子节点如果从0开始编号,某个节点的编号为i,则 “ 2 ∗ i + 1 ” “2*i+1” “2∗i+1”为其左孩子, “ 2 ∗ i + 2 ” “2*i+2” “2∗i+2”为其右孩子,证明方法实际上也简单,因为每一个左孩子都是偶索引,右孩子都是奇索引,满足奇偶数的通项公式 l e f t C h i l d = 2 ∗ p a r e n t r i g h t C h i l d = 2 ∗ p a r e n t + 1 leftChild = 2 * parent rightChild = 2 * parent + 1 leftChild=2∗parentrightChild=2∗parent+1
2.子节点找父节点 在C语言中 “ / ” “/” “/”是向0取整的,所以不使用数学表达式而是使用C语言表达式,那么只需要一个式子就可以表示 p a r e n t = ( c h i l d − 1 ) / 2 parent = (child - 1) / 2 parent=(child−1)/2
3.依靠这个性质使得完全二叉树和满二叉树非常适合用数组存储,而且也不会空间浪费
3.3.满二叉树性质

3.3.1.性质一:深度 K K K与节点数 N N N的关系 [ f ( K , N ) ] [f(K,N)] [f(K,N)]
若规定根节点的层数为 1 1 1,具有 N N N个节点的满二叉树的深度 K K K为 “ l o g 2 ( N + 1 ) ” “log_2(N + 1)” “log2(N+1)”
因为 ( 2 K ) − 1 = N (2^K) - 1 = N (2K)−1=N,则 K = l o g 2 ( N + 1 ) K = log_{2}(N + 1) K=log2(N+1)
4.二叉树的堆接口实现
4.1.堆的概念
这里提到的堆是一种数据结构,而不是操作系统里的堆空间。堆的表现形式是一棵完全二叉树,不过这棵完全二叉树的要求是“任何一个父节点都大于或等于子节点”或者“任何一个父节点都小于或等于子节点”,因此堆也被分为“大堆”或“小堆”。堆的实现可以采用逻辑结构为“完全二叉树”、物理结构为“数组”的方式来实现。
4.1.1.入堆
- 将要插入的元素放在堆的最后一个位置(即数组的最后一个位置)
- 将其与其父节点进行比较,使用向上调整算法来调整节点位置,直到满足堆的特性为止
4.1.2.出堆
- 将堆的最后一个节点和堆顶节点互换,然后将原来的堆顶节点隔离(也就是说不再将其视为堆的节点)
- 将此时新的堆顶节点与其子节点进行比较,使用向下调整算法调整节点位置,直到满足堆的特性为止
4.2.堆的实现
4.2.1.具体代码
// 堆的实现(以下是大堆结构)
typedef int HPDataType;
typedef struct Heap
{
HPDataType* _a;
int _size;
int _capacity;
}Heap;
// 1.堆的初始化
void HeapInit(Heap* hp)
{
assert(hp);
hp->_a = NULL;
hp->_size = hp->_capacity = 0;
}
// 2.堆的销毁
void HeapDestory(Heap* hp)
{
free(hp->_a);
hp->_capacity = hp->_size = 0;
}
// 3.堆的判空
bool HeapEmpty(Heap* hp)
{
return hp->_size == 0;//空则true
}
// 4.堆的插入(堆的插入要保持大堆/小堆的条件)
// 辅助函数:向上调整算法
/*
* 前提:一个完全二叉树满足堆性质,
* 但是某个节点的值发生了变化,
* 需要将其调整到合适的位置以恢复堆的性质
*/
void AdjustUp(HPDataType* arr, int childi)//这里也可以不加childi解决,但是由于以后用向上调整算法的时候不一定直接从最后一个节点开始,所以就设计了这个参数
{
assert(arr);
int parenti = (childi - 1) / 2;
while (childi > 0)//这里不能用parent
{
//1.不满足父节点大于子节点就交换
if (arr[parenti] < arr[childi])
{
int tmp = arr[parenti];
arr[parenti] = arr[childi];
arr[childi] = tmp;
childi = parenti;//2.迭代更新
parenti = (childi - 1) / 2;
}
else
{
break;
}
}
//3.补充一下,向上调整算法的时间复杂度为O(log(2)(n))
}
void HeapPush(Heap* hp, HPDataType x)
{
assert(hp);
//1.查看容量是否充足,不足就扩容
if (hp->_capacity == hp->_size)
{
int newcapacity = hp->_capacity == 0 ? 4 : hp->_capacity * 2;
HPDataType* cache = (HPDataType*)realloc(hp->_a, sizeof(HPDataType) * newcapacity);
if (!cache)
{
perror("realloc fail\n");
return;
}
hp->_a = cache;
hp->_capacity = newcapacity;
}
//2.直接插入
hp->_a[hp->_size] = x;
hp->_size++;
//3.使用向上调整算法
AdjustUp(hp->_a, hp->_size - 1);
}
// 5.堆的删除
// 辅助函数:向下调整算法
/*
* 前提:一个完全二叉树满足堆性质,
* 但是某个节点的值发生了变化,
* 需要将其调整到合适的位置以恢复堆的性质
*/
void AdjustDown(HPDataType* arr, int arrsize, int parenti)//在本例中不加上参数parenti也是可以解决的,但是长远来看,在以后使用向下调整算法的时候不一定从根节点开始也有可能从任意节点开始
{
//这是我一开始的写法,有什么问题呢?发生了数组越界,但其实如果在开头正确处理了数组越界问题那也是可以这么写的,只是不够整洁
//assert(arr);
//int childi = arr[parenti * 2 + 1] > arr[parenti * 2 + 2] ? (parenti * 2 + 1) : (parenti * 2 + 2);
//while (childi < arrsize)
//{
// if (arr[parenti] < arr[childi])
// {
// int tmp = arr[parenti];
// arr[parenti] = arr[childi];
// arr[childi] = tmp;
// parenti = childi;
// childi = arr[parenti * 2 + 1] > arr[parenti * 2 + 2] ? (parenti * 2 + 1) : (parenti * 2 + 2);
// }
// else
// {
// break;
// }
//}
int childi = parenti * 2 + 1;//先将左孩子索引赋给childi
while (childi < arrsize)//childi + 1 < arrsize不能写在这里,因为有可能左孩子存在但是没有右孩子
{
//1.修正孩子坐标
if (childi + 1 < arrsize && arr[childi] < arr[childi + 1])
{
childi++;
}
//2.判断是否需要交换
if (arr[childi] > arr[parenti])
{
int tmp = arr[childi];
arr[childi] = arr[parenti];
arr[parenti] = tmp;
parenti = childi;
childi = parenti * 2 + 1;
}
else
{
break;
}
}
}
void HeapPop(Heap* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
//1.交换堆顶节点和堆的最后一个节点
int tmp = hp->_a[0];
hp->_a[0] = hp->_a[hp->_size - 1];
hp->_a[hp->_size - 1] = tmp;
hp->_size--;//隔离
//2.使用向下调整算法
AdjustDown(hp->_a, hp->_size, 0);
}
// 6.取堆顶的数据
HPDataType HeapTop(Heap* hp)
{
assert(hp);
assert(hp->_size > 0);
return hp->_a[0];
}
// 7.堆的数据个数
int HeapSize(Heap* hp)
{
assert(hp);
return hp->_size;
}
4.2.2.测试用例
void test(void)
{
Heap hp;//创建堆
HeapInit(&hp);//初始化堆
int arr[10] = { 1, 2, 5, 23, 100, 234, 12, 0, -3, -313 };
for (int i = 0; i < sizeof(arr)/sizeof(int); i++)
{
HeapPush(&hp, arr[i]);//不断入堆
}
//不断出堆
for (int i = hp._size; i > 0; i--)
{
for (int i = 0; i < hp._size; i++)
{
printf("%d ", hp._a[i]);
}
printf(" 此时堆有%d个元素,堆顶元素是%d", HeapSize(&hp), HeapTop(&hp));
printf("\n");
HeapPop(&hp);//出堆
}
printf("此时堆有%d个元素\n", HeapSize(&hp));
//HeapPop(&hp);//非法出堆
//HeapTop(&hp);//非法取堆顶
HeapDestory(&hp);//销毁堆
}
4.3.堆的作用
4.3.1.Top-k问题的解决
堆的插入和删除时间复杂度都为 O ( l o g 2 ( n ) ) O(log_{2}(n)) O(log2(n)),因此堆的插入和删除效率很高
最坏都要调整树的高度/深度次,而“高度/深度”为 K = ⌊ l o g 2 ( N ) ⌋ + 1 K = ⌊log_{2}(N)⌋ + 1 K=⌊log2(N)⌋+1 ( ⌊ x ⌋ 表示取不小于 x 的最大整数) (⌊x⌋表示取不小于x的最大整数) (⌊x⌋表示取不小于x的最大整数),考虑最坏情况并且简化公式就可以得到时间复杂度为 l o g 2 ( n ) log_{2}(n) log2(n)
堆可以高效解决top-k问题。每一次入堆/出堆后,堆顶节点携带的数据都是最大的,并且无需全部排序就能得到最大的数据,而其他普通的排序则需要全部排序,择取前k位才能得到的数据,对比起来堆的效率更高。
4.3.2.堆排序(一种选择排序)
之前有关堆顶(大堆)的实现中,如果一边取堆顶节点数据打印,一边进行出堆,不难发现构成了一种不太严格的“排序算法”。为什么说是不严格呢?因为排序是要在内存中排序,这个只是打印的数据是有序的,并没有真正的改变存储推节点的数据的顺序。
- 堆排实现方法一(只使用之前写过的堆接口来实现)
//利用前面写好的堆接口
void HeapSort_1(int* arr, int arrsize)
{
Heap hp;
HeapInit(&hp);//初始化
for (int i = 0; i < arrsize; i++)
{
HeapPush(&hp, arr[i]);//不断插入
}
for (int i = 0; i < arrsize; i++)
{
arr[i] = HeapTop(&hp);//不断取出拷贝回原来传递过来的数组
HeapPop(&hp);
}
HeapDestory(&hp);
}
int main()
{
int arr[10] = { 1, 192, 34, 412, 32, 0, -2134, 23, 45, 89 };
for (int i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
HeapSort_1(arr, sizeof(arr) / sizeof(int));//堆排序
for (int i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}
//但是这种比较粗糙,不是直接排序出来,而是通过拷贝再粘贴的方式,比较粗糙,效率可以,但还需要先建立一个堆,空间复杂度高
- 堆排实现方法二(模拟堆的入堆和出堆,建堆使用向下调整算法,排序使用向上调整算法)
//利用前面写好的向上和向下调整算法,模拟堆的入堆和出堆
void AdjustUp(HPDataType* arr, int childi)
{
assert(arr);
int parenti = (childi - 1) / 2;
while (childi > 0)//这里不能用parent
{
//1.不满足父节点大于子节点就交换
if (arr[parenti] < arr[childi])
{
int tmp = arr[parenti];
arr[parenti] = arr[childi];
arr[childi] = tmp;
childi = parenti;//2.迭代更新
parenti = (childi - 1) / 2;
}
else
{
break;
}
}
//3.补充一下,向上调整算法的时间复杂度为O(log(2)(n))
}
void AdjustDown(HPDataType* arr, int arrsize, int parenti)
{
int childi = parenti * 2 + 1;//先将左孩子索引赋给childi
while (childi < arrsize)//childi + 1 < arrsize不能写在这里,因为有可能左孩子存在但是没有右孩子
{
//1.修正孩子坐标
if (childi + 1 < arrsize && arr[childi] < arr[childi + 1])
{
childi++;
}
//2.判断是否需要交换
if (arr[childi] > arr[parenti])
{
int tmp = arr[childi];
arr[childi] = arr[parenti];
arr[parenti] = tmp;
parenti = childi;
childi = parenti * 2 + 1;
}
else
{
break;
}
}
}
//--------------------------
void HeapSort_2(int* arr, int arrsize)
{
//直接把数组内的元素数据调整为堆,因为任何数组在逻辑结构上都可以看作是一棵完全二叉树,所以我们利用这一点把原有的数组调整成堆
//1.将根节点看作一个堆,然后将剩余的元素按照顺序一个一个插入到堆里,而插入就要写向上调整算法
for (int i = 1; i < arrsize; i++)
{
AdjustUp(arr, i);
}//2.一个循环走下来就建好了一个堆(注意我的向上调整算法是拿来建大堆的)
//3.接下来模拟出堆的过程,将每一次生成的堆顶扔(换)到原数组的后面
for (int i = arrsize - 1; i > 0; i--)
{
int tmp = arr[0];
arr[0] = arr[i];
arr[i] = tmp;
AdjustDown(arr, i, 0);
}
}
int main()
{
int arr[10] = { 1, 192, 34, 412, 32, 0, -2134, 23, 45, 89 };
for (int i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
HeapSort_2(arr, sizeof(arr) / sizeof(int));//堆排序
for (int i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
- 堆排实现方法三(模拟堆的入堆和出堆,建堆使用向下调整算法,排序使用向下调整算法)
//利用前面写好的向下调整算法,模拟堆的入堆和出堆
void AdjustDown(HPDataType* arr, int arrsize, int parenti)
{
int childi = parenti * 2 + 1;//先将左孩子索引赋给childi
while (childi < arrsize)//childi + 1 < arrsize不能写在这里,因为有可能左孩子存在但是没有右孩子
{
//1.修正孩子坐标
if (childi + 1 < arrsize && arr[childi] < arr[childi + 1])
{
childi++;
}
//2.判断是否需要交换
if (arr[childi] > arr[parenti])
{
int tmp = arr[childi];
arr[childi] = arr[parenti];
arr[parenti] = tmp;
parenti = childi;
childi = parenti * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort_3(int* arr, int arrsize)
{
//从叶子节点开始倒着调整(自成一个堆),所以从第一个非叶子节点开始调整
//1.利用向下调整来建堆
for(int i = ((arrsize - 1) - 1) / 2; i >= 0; i--)
{
AdjustDown(arr, arrsize, i);
}
//2.利用向下调整法来排序
for (int i = arrsize - 1; i > 0; i--)
{
int tmp = arr[0];
arr[0] = arr[i];
arr[i] = tmp;
AdjustDown(arr, i, 0);
}
}
int main()
{
int arr[10] = { 1, 192, 34, 412, 32, 0, -2134, 23, 45, 89 };
for (int i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
HeapSort_3(arr, sizeof(arr) / sizeof(int));//堆排序
for (int i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
1.方法二(使用向上调整建堆)
1.1.建堆时间复杂度:
假设一棵树深度为 K K K,则最坏情况下有如下分析
第 [ 1 ] [ 1 ] [1]层有 [ 2 0 ] [ 2^0 ] [20]个节点,需要向上移动 [ 0 ] [ 0 ] [0]层
第 [ 2 ] [ 2 ] [2]层有 [ 2 1 ] [ 2^1 ] [21]个节点,需要向上移动 [ 1 ] [ 1 ] [1]层
第 [ 3 ] [ 3 ] [3]层有 [ 2 1 ] [ 2^1 ] [21]个节点,需要向上移动 [ 2 ] [ 2 ] [2]层
……
第 [ K − 2 ] [K-2] [K−2]层有 [ 2 K − 3 ] [2^{K-3}] [2K−3]个节点,需要向上移动 [ K − 3 ] [K-3] [K−3]层
第 [ K − 1 ] [K-1] [K−1]层有 [ 2 K − 2 ] [2^{K-2}] [2K−2]个节点,需要向上移动 [ K − 2 ] [K-2] [K−2]层
第 [ K ] [ K ] [K]层有 [ 2 K − 1 ] [2^{K-1}] [2K−1]个节点,需要向上移动 [ K − 1 ] [K-1] [K−1]层
综上所述,一共要移动: ( 2 1 ) ∗ ( 1 ) + ( 2 2 ) ∗ ( 2 ) + … … + ( 2 K − 1 ) ∗ ( K − 1 ) = 2 K ∗ ( K − 2 ) + 2 = ( N + 1 ) ∗ ( l o g ( N + 1 ) − 2 ) + 2 (2^1)*(1)+(2^2)*(2)+……+(2^{K-1})*(K-1) = 2^K*(K-2)+2 = (N+1)*(log(N+1)-2)+2 (21)∗(1)+(22)∗(2)+……+(2K−1)∗(K−1)=2K∗(K−2)+2=(N+1)∗(log(N+1)−2)+2
因此时间复杂度就是 O ( N ∗ l o g 2 ( N ) ) O(N*log_2(N)) O(N∗log2(N))
1.2.排序时间复杂度:
对于一棵已成堆的树,最后一层有 2 K − 1 2^{K-1} 2K−1个节点,每次都要和堆顶互换,最坏情况下需要调整 K − 1 K-1 K−1次,以此类推,这就和向上调整算法的时间复杂度是一样的,都是 O ( N ∗ l o g 2 ( N ) ) O(N*log_2(N)) O(N∗log2(N))(注意,不要错误认为每次向下调整的而时间复杂度是 l o g 2 ( N ) log_2(N) log2(N),就觉得这个时间复杂度是 l o g 2 ( N ) + l o g 2 ( N − 1 ) + … l o g 2 ( 1 ) = l o g 2 ( N ! ) log_2(N)+log_2(N-1)+…log_2(1)= log_2(N!) log2(N)+log2(N−1)+…log2(1)=log2(N!)这样错误的答案,这是因为一开始树的高度有可能保持一段时间的固定)
1.3.整体时间复杂度: O(N*log_2(N))
2.方法三(使用向下调整建堆)
2.1.建堆时间复杂度:
假设一棵树深度为 K K K,则最坏情况下有如下分析
第 [ 1 ] [ 1 ] [1]层有 [ 2 0 ] [ 2^0 ] [20]个节点,需要向下移动 [ K − 1 ] [K-1] [K−1]层
第 [ 2 ] [ 2 ] [2]层有 [ 2 1 ] [ 2^1 ] [21]个节点,需要向下移动 [ K − 2 ] [K-2] [K−2]层
第 [ 3 ] [ 3 ] [3]层有 [ 2 1 ] [ 2^1 ] [21]个节点,需要向下移动 [ K − 3 ] [K-3] [K−3]层
……
第 [ K − 2 ] [K-2] [K−2]层有 [ 2 K − 3 ] [2^{K-3}] [2K−3]个节点,需要向下移动 [ 2 ] [ 2 ] [2]层
第 [ K − 1 ] [K-1] [K−1]层有 [ 2 K − 2 ] [2^{K-2}] [2K−2]个节点,需要向下移动 [ 1 ] [ 1 ] [1]层
第 [ K ] [ K ] [K]层有 [ 2 K − 1 ] [2^{K-1}] [2K−1]个节点,需要向下移动 [ 0 ] [ 0 ] [0]层
综上所述,一共要移动: ( 2 0 ) ∗ ( K − 1 ) + ( 2 1 ) ∗ ( K − 2 ) + ( 2 2 ) ∗ ( K − 3 ) + … … + ( 2 K − 1 ) ∗ ( 1 ) = 2 K − 1 − K = N − l o g 2 ( N + 1 ) (2^0)*(K-1)+(2^1)*(K-2)+(2^2)*(K-3)+……+(2^{K-1})*(1) = 2^K-1-K = N-log_2(N+1) (20)∗(K−1)+(21)∗(K−2)+(22)∗(K−3)+……+(2K−1)∗(1)=2K−1−K=N−log2(N+1),因此时间复杂度就是 O ( N ) O(N) O(N)(注意,不要因为向下调整算法的单次调整是 l o g 2 ( N ) log_2(N) log2(N),就觉得每个节点都是 l o g 2 ( N ) log_2(N) log2(N),于是得到 N ∗ l o g 2 ( N ) N*log_2(N) N∗log2(N)这个错误结果,错误的原因是因为,每一个节点的 l o g 2 ( N ) log_2(N) log2(N)不同的,因此不是简单的相乘)
2.2.排序时间复杂度:
对于一棵已成堆的树,最后一层有 2 K − 1 2^{K-1} 2K−1个节点,每次都要和堆顶互换,最坏情况下需要调整 K − 1 K-1 K−1次,以此类推,这就和向上调整算法的时间复杂度是一样的,都是 O ( N ∗ l o g 2 ( N ) ) O(N*log_2(N)) O(N∗log2(N))
2.3.整体时间复杂度: O ( N + N ∗ l o g 2 ( N ) ) = O ( N ∗ ( 1 + l o g 2 ( N ) ) ) = O ( N ∗ l o g 2 ( N ) ) O(N+N*log_2(N)) = O(N*(1+log_2(N))) = O(N*log_2(N)) O(N+N∗log2(N))=O(N∗(1+log2(N)))=O(N∗log2(N))
3.总结:向上调整算法效率低的原因就是节点少就调整少,节点多就调整多
4.3.3.堆排解决Top-k的缺陷
-
正常思路:如果在 N N N个数中选取k个数据,则如果这个 N N N过大,建堆的空间复杂度会很大,数据量过大就要装在磁盘中(比如存储在文件中),这个时候不可能全部把文件里的数据全部读取到内存。因为超出内存的数据会被推出内存,以便加载新的数据进入内存,但是这样就始终没有办法把数据全部加载到内存中,那就更加别提说使用堆排序了
-
优化思路:既然全部数据不可能同时加载到内存中,那么我们就只加载一部分把!
- 情况一:先将前k个数据加载进内存,利用向下调整算法建成小堆,则后面N-k个数,逐一何堆顶数据比较,比堆顶数据大就替换堆顶数据,最后这个小堆存储的就是最大的前k个数据,这样就可以找到这其中的k个数据了
- 情况二:先将前k个数据加载进内存,利用向下调整算法建成大堆,则后面N-k个数,逐一何堆顶数据比较,比堆顶数据小就替换堆顶数据,最后这个小堆存储的就是最小的前k个数据,这样就可以找到这其中的k个数据了
//下面选出最小的前k个数据
void AdjustDown(HPDataType* arr, int arrsize, int parenti)
{
int childi = parenti * 2 + 1;//先将左孩子索引赋给childi
while (childi < arrsize)//childi + 1 < arrsize不能写在这里,因为有可能左孩子存在但是没有右孩子
{
//1.修正孩子坐标
if (childi + 1 < arrsize && arr[childi] < arr[childi + 1])
{
childi++;
}
//2.判断是否需要交换
if (arr[childi] > arr[parenti])
{
int tmp = arr[childi];
arr[childi] = arr[parenti];
arr[parenti] = tmp;
parenti = childi;
childi = parenti * 2 + 1;
}
else
{
break;
}
}
}
//开始排序
void HeapSort_4(int* arr, int arrSize, int k)
{
//1.先建一个大堆
for (int i = k - 1; i >= 0; i--)
{
AdjustDown(arr, k, i);//使用向下调整算法
}
//2.再拿后arrSize-k个数据和堆顶一一对比
for (int j = k; j < arrSize; j++)
{
if (arr[0] > arr[j])
{
int tmp = arr[0];
arr[0] = arr[j];
arr[j] = tmp;
AdjustDown(arr, k, 0);
}
}
//3.再复用前面的HeapSort_3()对k个元素单独堆排
HeapSort_3(arr, k);
}
- 模拟情况
//模拟针对大量数据的Top-k的堆排
void HeapSort_Topk(int k)
{
//1.打开文件
const char* file = "data.txt";
FILE* fout = fopen(file, "r");
if (fout == NULL)//打开失败就提示
{
perror("fopen error");
return;
}
//2.先只读取k个数据
int* kmaxheap = (int*)malloc(sizeof(int) * k);//开辟对应大堆的空间
if (kmaxheap == NULL)//开辟失败就提示
{
perror("malloc error");
return;
}
for (int i = 0; i < k; i++)
{
int fscanfreturn = fscanf(fout, "%d", &kmaxheap[i]);//利用格式化输入将文件中前k个数据读取到数组中
}
//3.建大堆
for (int i = (k - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(kmaxheap, k, i);//使用向下调整算法
}
//4.读取N-k个数据然后一一对比
int val = 0;
while (!feof(fout))
{
int fscanfreturn = fscanf(fout, "%d", &val);
if (val < kmaxheap[0])
{
kmaxheap[0] = val;
AdjustDown(kmaxheap, k, 0);
}
}
fclose(fout);
//5.打印前最小的k个数据
HeapSort_3(kmaxheap, k);
for (int i = 0; i < k; i++)
{
printf("%d ", kmaxheap[i]);
}
printf("\n");
free(kmaxheap);
}
//模拟数据在文件中存储
void _make(void)
{
//造数据
int n = 100;//控制数据个数
int m = 100;//控制数据范围
int x = 0;//存储数据本身
srand((unsigned)time(0));//随机数种子
const char* file = "data.txt";//定义文件名字
FILE* fin = fopen(file, "w");//以只写的方式打开该文件,如果该文件不存在就自动创建,存在则覆盖原有的内容
if (fin == NULL)//打开失败就提示错误
{
perror("fopen error");
return;
}
for (size_t i = 0; i < n; ++i)//不断写入n个随机数据
{
x = rand() % m;
fprintf(fin, "%d\n", x);
}
fclose(fin);//关闭该文件
}
int main()
{
_make();
HeapSort_Topk(10);
return 0;
}
5.二叉树的遍历方法

5.1.前中后序遍历
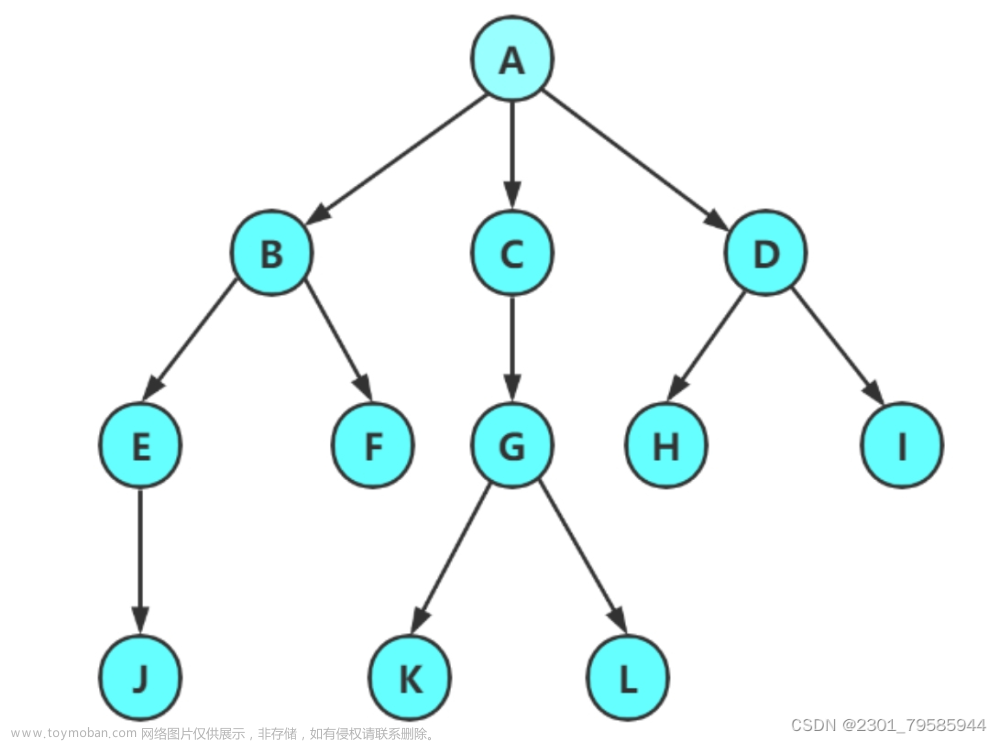
首先无论是什么二叉树结构都需要被理解成三部分,“根+左子树+右子树”,下面我们使用三种同类型的方法来遍历上面这棵二叉树。
- 前中后序概念
- 前序/先根:先访问根、再访问左子树、再访问右子树:A-B-D-G-NULL-NULL-NULL-E-H-NULL-NULL-I-NULL-NULL-C-NULL-F-NULL-NULL-end,简化为:A-B-D-G-E-H-I-C-F(有的时候也叫“先序”)
- 中序/中根:先访问左子树、再访问根、再访问右子树:NULL-G-NULL-D-NULL-B-NULL-H-NULL-E-NULL-I-NULL-A-NULL-C-NULL-F-NULL-end,简化为:G-D-B-H-E-I-A-C-F
- 后序/后根:先访问左子树、再访问右子树、再访问根:NULL-NULL-G-NULL-D-NULL-NULL-H-NULL-NULL-I-E-B-NULL-NULL-NULL-F-C-A-end,简化为:G-D-H-I-E-B-F-C-A
- 前、中、后序的时间和空间复杂度(假设树有N个节点,深度为K)
- 时间复杂度:由于每一个节点都要访问一次,因此时间复杂度都是O(N)
- 空间复杂度:由于有N个节点,所以树的最大深度是K是N,最小深度是log(2)(N+1)。因此在考虑共用栈帧情况下,最多建立N个栈帧,即空间复杂度为O(K)
5.2.层序遍历
层序遍历从遍历方式上比较容易理解,例如上面那棵树的层序遍历就是:A-B-C-D-E-F-NULL-NULL-G-H-I-NULL-NULL-NULL-NULL-NULL-NULL,但是其具体实现就比较难以想到
实现思路就是:
1.假设有一个队列Q
2.这个时候将指向A节点指针入队
3.此时取队头,打印A节点携带的数据,
4.并把指向A的左孩子B和右孩子C的两个指针依次入队
5.取出队头元素的数据
6.然后根据“先入先出”原则,先让指向B节点的指针出队
7.并把指向B的左孩子D和右孩子E的两个指针依次入队
……
例如下面这棵树对应的层序遍历过程
void LevelOrder(BinaryTreeNode* root)
{
//1.初始化队列
Queue qu;
QueueInit(&qu);
//2.将树的根节点入队
if (root)
QueuePush(&qu, root);
//3.将队头的树节点的左右子树入队
while (!QueueEmpty(&qu))
{
BinaryTreeNode* p = QueueFront(&qu);//取出队头
QueuePop(&qu);
if (p != NULL)
{
printf("%c ", p->data);
}
else
{
printf("NULL ");
}
if (p)
{
QueuePush(&qu, p->left);//入左子树
QueuePush(&qu, p->right);//入右子树
}
}
//4.销毁队列
QueueDestroy(&qu);
}
6.二叉树的相关练习
6.1.性质选择题
6.1.1.题目一
某二叉树共有399个节点,其中共有199个度为2的节点,则二叉树的叶子节点数量为?
根据 n 0 = n 2 + 1 n_0 = n_2 + 1 n0=n2+1得到 n 0 = 199 + 1 = 200 n_0 = 199 + 1 = 200 n0=199+1=200
6.1.2.题目二
在具有2n个节点的完全二叉树,叶子节点有多少个呢?
根据 n 0 = n 2 + 1 n_0 = n_2 + 1 n0=n2+1,将 X ( 0 ) + X ( 1 ) + X ( 2 ) = 2 n X(0) + X(1) + X(2) = 2n X(0)+X(1)+X(2)=2n转化为 2 X ( 0 ) + X ( 1 ) − 1 = 2 n 2X(0) + X(1) -1 = 2n 2X(0)+X(1)−1=2n,而一个完全二叉树度为1的节点个数要不是1,要不就是0,因此 x ( 1 ) = 1 或 0 x(1) = 1或0 x(1)=1或0,因此 2 X ( 0 ) + X ( 1 ) − 1 = 2 n 2X(0) + X(1) -1 = 2n 2X(0)+X(1)−1=2n解得 x ( 0 ) = 2 n / 2 或 ( 2 n + 1 ) / 2 x(0) = 2n / 2或(2n +1) /2 x(0)=2n/2或(2n+1)/2,因此正确答案为 n n n个(毕竟有偶数个节点,因此一定有一个度为1的节点)
6.1.3.题目三
一棵完全二叉树的节点数为531个,那么这棵树的高度为多少?
假设树的高度为K,假设最后一层缺了X个,则 2 K − 1 − X = 531 2^K - 1 - X = 531 2K−1−X=531,而X的范围为 [ 0 , 2 ( K − 1 ) − 1 ] [0, 2^(K-1) - 1] [0,2(K−1)−1](没缺,却得只剩一个)个节点,这样就可以解出 532 < = 2 K < = 1062 532 <= 2^K <= 1062 532<=2K<=1062
6.1.4.题目四
某完全二叉树按层次输出(同一层从左到右)的序列为 ABCDEFGH 。该完全二叉树的前序序列为?
A.ABDHECFG
B.ABCDEFGH
C.HDBEAFCG
D.HDEBFGCA
6.1.5.题目五
二叉树的先序遍历和中序遍历如下:先序遍历:EFHIGJK;中序遍历:HFIEJKG.则二叉树根结点为?
A.E
B.F
C.G
D.H
尽管简单,但是根据两序是可以推导出整棵树的,前提是要有一序为中序,就是要注意空节点的情况
6.1.6.题目六
设一课二叉树的中序遍历序列:badce,后序遍历序列:bdeca,则二叉树前序遍历序列为?
A.adbce
B.decab
C.debac
D.abcde
6.2.编程练习题
6.2.1.相同的树
bool isSameTree(struct TreeNode* p, struct TreeNode* q)
{
if(p == NULL && q == NULL)
{
return true;
}
if(p == NULL && q != NULL)
{
return false;
}
if( p!= NULL && q == NULL)
{
return false;
}
if(p->val != q->val)
{
return false;
}
return isSameTree(p->left, q->left) && isSameTree(p->right, q->right);
}
6.2.2.对称二叉树
bool _isSymmetric(struct TreeNode* leftTree, struct TreeNode* rightTree)
{
if(leftTree == NULL && rightTree == NULL)
{
return true;
}
if(leftTree == NULL && rightTree != NULL)
{
return false;
}
if(leftTree != NULL && rightTree == NULL)
{
return false;
}
if(leftTree->val != rightTree->val)
{
return false;
}
return _isSymmetric(leftTree->left, rightTree->right) && _isSymmetric(leftTree->right, rightTree->left);
}
bool isSymmetric(struct TreeNode* root)
{
if(root == NULL)
{
return true;
}
return _isSymmetric(root->left, root->right);
}
6.2.3.二叉树的前序遍历
int __preorderTraversal(struct BinaryTreeNode* root)
{
if (root == NULL)
{
return 0;
}
return 1 + __preorderTraversal(root->left) + __preorderTraversal(root->right);
}
void _preorderTraversal(struct BinaryTreeNode* root, int* arr, int* i)
{
if (root == NULL)
{
return;
}
arr[*i] = root->data;
if (root->left != NULL)
{
(*i)++;
_preorderTraversal(root->left, arr, i);
}
if (root->right != NULL)
{
(*i)++;
_preorderTraversal(root->right, arr, i);
}
}
6.2.4.二叉树的中序遍历
6.2.5.二叉树的后序遍历
6.2.6.另一棵树的子树
bool isSameTree(struct TreeNode* p, struct TreeNode* q)//本质是前序遍历
{
if(p == NULL && q == NULL)
{
return true;
}
if(p == NULL && q != NULL)
{
return false;
}
if(p!= NULL && q == NULL)
{
return false;
}
if(p->val != q->val)
{
return false;
}
return isSameTree(p->left, q->left) && isSameTree(p->right, q->right);
}
bool isSubtree(struct TreeNode* root_1, struct TreeNode* root_2)
{
if(root_1 == NULL && root_2 == NULL)
{
return true;
}
if(root_1 == NULL || root_2 == NULL)
{
return false;
}
bool b = isSameTree(root_1, root_2);
return b || isSubtree(root_1->left, root_2) || isSubtree(root_1->right, root_2);
}
6.2.7.二叉树遍历
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#include <stdbool.h>
typedef char BTDataType;
typedef struct BinaryTreeNode
{
BTDataType data;
struct BinaryTreeNode* left;
struct BinaryTreeNode* right;
}BinaryTreeNode;
BinaryTreeNode* BuyNode(BTDataType x)
{
BinaryTreeNode* cache = (BinaryTreeNode*)malloc(sizeof(BinaryTreeNode));
if (!cache) exit(-1);
cache->data = x;
cache->left = NULL;
cache->right = NULL;
return cache;
}
BinaryTreeNode* BinaryTreeCreate(BTDataType* arr, int n, int* pi)
{
BinaryTreeNode* root = NULL;
if (arr[*pi] == '#')
{
(*pi)++;
return root;
}
root = BuyNode(arr[(*pi)++]);
root->left = BinaryTreeCreate(arr, n, pi);
root->right = BinaryTreeCreate(arr, n, pi);
return root;
}
void BinaryTreeInOrder(BinaryTreeNode* root)
{
if (root == NULL)
{
return;
}
BinaryTreeInOrder(root->left);
printf("%c ", root->data);
BinaryTreeInOrder(root->right);
}
int main()
{
char arr[100];
int scanfreturn = scanf("%s", arr);
int n = strlen(arr);
int i = 0;
BinaryTreeNode* tree = BinaryTreeCreate(arr, n, &i);
BinaryTreeInOrder(tree);
return 0;
}
6.2.8.二叉树的最大深度/高度
int maxDepth(struct BinaryTreeNode* root)
{
if (root != NULL)
{
int a = maxDepth(root->left);
int b = maxDepth(root->right);
return a >= b ? a + 1 : b + 1;
}
return 0;
}
//在三目表达式中直接放入函数效率会很低
6.2.9.平衡二叉树
6.2.10.二叉树的层序遍历
6.2.11.求二叉树的节点个数
这道题目比较捞的写法就是强行返回静态变量或使用全局变量,因此使用递归专有的计数方法(在return中计数是目前最好的)
//强行返回静态变量(已经经过编译,但是过不去力扣,只能过一次)
int countNodes(struct BinaryTreeNode* root)
{
static int SIZE = 0;
if (root == NULL)
{
return SIZE;
}
SIZE++;
countLeafNode(root->left);
countLeafNode(root->right);
return SIZE;
}
//并且哪怕是调用完后也没有办法将SIZE重置为0,这是因为SIZE是一个局部的静态变量,在main函数中不可见
//使用全局变量(已经经过编译,但是过不去力扣,只能过一次)
int SIZE = 0;
int countNodes(struct BinaryTreeNode* root)
{
if(root == NULL)
{
return SIZE;
}
SIZE++;
countLeafNode(root->left);
countLeafNode(root->right);
return SIZE;
}
int main()
{
printf("%d\n", SIZE);
return 0;
}
//这个函数调用完后还可以将SISE初始化为0,这是因为SIZE在本代码中是一个全局变量,因此对于main函数来说是可见的,但是但是,这会大大增加函数使用的错误概率,因为每一次都需要手动置空,否则就会重复计数。
//在return中计数:较优秀的写法(本质是使用了后序)
int countNodes(struct BinaryTreeNode* root)
{
if (root == NULL)
{
return 0;
}
return 1 + countNodes(root->left) + countNodes(root->right);
}
//在return中计数:较简洁的写法(本质是使用了后序)
int countNodes(struct TreeNode* root)
{
return root == NULL ? 0 : 1 + countNodes(root->left) + countNodes(root->right);
}
6.2.12.求二叉树的叶子节点个数
我暂时没有在牛客网和力扣找到这个题目,不过您也可以自己测一测
//写法一(已经过编译测试)
int countLeafNode(struct BinaryTreeNode* root)
{
if (root == NULL)
{
return 0;
}
//1.根节点知道自己不是叶子节点的情况
if (root->left != NULL || root->right != NULL)
{
return countLeafNode(root->left) + countLeafNode(root->right);
}
//2.根节点知道自己是叶子节点的情况
return 1;
}
//写法二(已经过编译测试,和上面的写法是一样的)
int countLeafNode(struct BinaryTreeNode* root)
{
if (root == NULL)
{
return 0;
}
if (root->left == NULL && root->right == NULL)
{
return 1;
}
return (countLeafNode(root->left) + countLeafNode(root->right));
}
6.2.13.求二叉树某一层的节点个数
我暂时没有在牛客网和力扣找到这个题目,不过您也可以自己测一测
int BTreeLevelKSize(BTNode* root,int k)
{
assert(k > 0);
if (root == NULL)
{
return 0;
}
if(k == 1)
{
return 1;
}
return BTreeLevelKSize(root->left, k - 1) + BTreeLevelKSize(root->right, k - 1);
}
6.2.14.查找二叉树的某一节点并返回指向该节点的指针
我暂时没有在牛客网和力扣找到这个题目,不过您也可以自己测一测文章来源:https://www.toymoban.com/news/detail-476890.html
BinaryTreeNode* BTreeFind_1(BinaryTreeNode* root, int x)
{
if (root == NULL)
{
return NULL;
}
if (root->data == x)
{
return root;
}
BinaryTreeNode* p1 = BTreeFind_1(root->left, x);
if (p1) return p1;
BinaryTreeNode* p2 = BTreeFind_1(root->right, x);
if (p2) return p2;
return NULL;
//这里要深刻理解递归的返回值有可能不会直接回到主函数
}
//----------------------------------------
BinaryTreeNode* BTreeFind_2(BinaryTreeNode* root, int x)
{
if (root == NULL)
{
return NULL;
}
if (root->data == x)
{
return root;
}
BinaryTreeNode* p1 = BTreeFind_2(root->left, x);
if (p1)
return p1;
return BTreeFind_2(root->right, x);
//这里要深刻理解递归的返回值有可能不会直接回到主函数
}
6.2.15.单值二叉树
//多加一个小接口比较好操作
bool _isUnivalTree(struct TreeNode* root, int x)
{
if(root == NULL)
{
return true;
}
if(root->val != x)
{
return false;
}
return _isUnivalTree(root->left, x) && _isUnivalTree(root->right, x);
}
bool isUnivalTree(struct TreeNode* root)
{
if(root == NULL)
{
return false;
}
return _isUnivalTree(root, root->val);
}
bool isUnivalTree(BinaryTreeNode* root)
{
if (root == NULL)
{
return true;
}
if (root->left && root->data != root->left->data)
{
return false;
}
if (root->right && root->data != root->right->data)
{
return false;
}
return isUnivalTree(root->left) && isUnivalTree(root->right);
}
6.2.16.二叉树查找值为x的节点
我暂时没有在牛客网和力扣找到这个题目,不过您也可以自己测一测文章来源地址https://www.toymoban.com/news/detail-476890.html
BinaryTreeNode* BinarytreeFind(BinaryTreeNode* root, int x)
{
if (root == NULL)
{
return NULL;
}
if (root->data == x)
{
return root;
}
BinaryTreeNode* a = BinarytreeFind(root->left , x);
BinaryTreeNode* b = BinarytreeFind(root->right, x);
if (a != NULL)
{
return a;
}
if (b != NULL)
{
return b;
}
return NULL;
}
//优化代码
BinaryTreeNode* BinarytreeFind(BinaryTreeNode* root, int x)
{
if (root == NULL)
{
return NULL;
}
if (root->data == x)
{
return root;
}
BinaryTreeNode* a = BinarytreeFind(root->left , x);
if (a != NULL)//这里拉到前面可以减少运算
{
return a;
}
BinaryTreeNode* b = BinarytreeFind(root->right, x);
if (b != NULL)
{
return b;
}
return NULL;
}
//这个思路很清奇,但是可维护性、易读性降低了
BinaryTreeNode* BinarytreeFind(BinaryTreeNode* root, int x)
{
if (root == NULL)
{
return NULL;
}
if (root->data == x)
{
return root;
}
BinaryTreeNode* a = BinarytreeFind(root->left , x);
if (a != NULL)
{
return a;
}
return BinarytreeFind(root->right, x);
}
6.2.17.翻转二叉树
struct TreeNode* invertTree(struct TreeNode* root)
{
if(root == NULL)
{
return NULL;
}
struct TreeNode* left = root->left;
struct TreeNode* right = root->right;
root->left = right;
root->right = left;
invertTree(root->left);
invertTree(root->right);
return root;
}
- 从大量的递归练习中,可以发现除了设立count变量计数,还可以使用递归计数,这是一个很重要的知识
- 递归需要注意其返回值不一定是返回主函数,返回值永远是返回调用函数的地方
- 在二叉树中理解递归的最快方法是画递归展开图,而递归展开图有两种图解方法
- 第一种是直接在代码内展开,符合直线逻辑,但是写起来复杂
- 第二种是靠代码图/二叉树图展开来理解,这种比较简单,但是有可能绕晕,画多了优于第一种方法
7.二叉树的相关常用接口
- 如果单纯使用二叉树存储数据就没有太大意义(因为有链表这样优秀的存储结构,二叉树就太复杂了),但是如果加以一定的规则,比如:规定左子树上所有节点小于根节点,右子树上所有节点大于根节点,变成一棵搜索二叉树(下面就是一棵典型的二叉树例子),那么该二叉树就具有很大的意义了。
- 现在,我们针对二叉树在日常生活中的使用,给出几个具体实用的常用接口,由于篇幅原因,在后续的博文里我会给出下面接口的具体实现方式。
// 通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树
BTNode* BinaryTreeCreate(BTDataType* a, int n, int* pi);
// 二叉树销毁
void BinaryTreeDestory(BTNode** root);
// 二叉树节点个数
int BinaryTreeSize(BTNode* root);
// 二叉树叶子节点个数
int BinaryTreeLeafSize(BTNode* root);
// 二叉树第k层节点个数
int BinaryTreeLevelKSize(BTNode* root, int k);
// 二叉树查找值为x的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x);
// 二叉树前序遍历
void BinaryTreePrevOrder(BTNode* root);
// 二叉树中序遍历
void BinaryTreeInOrder(BTNode* root);
// 二叉树后序遍历
void BinaryTreePostOrder(BTNode* root);
// 层序遍历
void BinaryTreeLevelOrder(BTNode* root);
// 判断二叉树是否是完全二叉树
int BinaryTreeComplete(BTNode* root);
到了这里,关于006+limou+C语言“堆的实现”与“树的相关概念”的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!