hello,大家好,我是 Jackpop,硕士毕业于哈尔滨工业大学,曾在华为、阿里等大厂工作,如果你对升学、就业、技术提升等有疑惑,不妨交个朋友:
我是Jackpop,我们交个朋友吧!
在本系列文章的第3部分关于实时流处理的文章中,我们学习了如何使用ElasticSearch的批量API以及利用REST API将.json航班数据文件导入ElasticSearch。
在这篇文章中,我们将介绍另一种方式,Logstash。
Logstash介绍
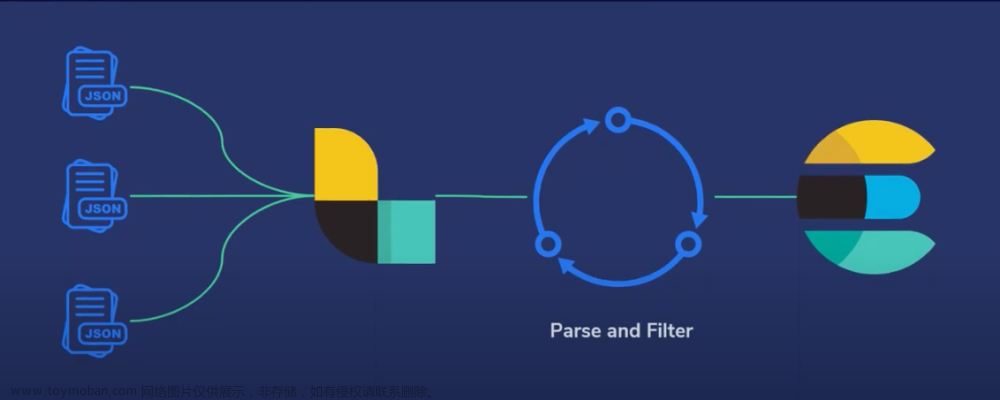
Logstash是一个开源的数据收集引擎,具有实时流水线功能。
它从多个源头接收数据,进行数据处理,然后将转化后的信息发送到stash,即存储。
Logstash允许我们将任何格式的数据导入到任何数据存储中,不仅仅是ElasticSearch。
它可以用来将数据并行导入到其他NoSQL数据库,如MongoDB或Hadoop,甚至导入到AWS。
数据可以存储在文件中,也可以通过流等方式进行传递。
Logstash对数据进行解析、转换和过滤。它还可以从非结构化数据中推导出结构,对个人数据进行匿名处理,可以进行地理位置查询等等。
一个Logstash管道有两个必要的元素,输入和输出,以及一个可选的元素,过滤器。
输入组件从源头消耗数据,过滤组件转换数据,输出组件将数据写入一个或多个目的地。
所以,我们的示例场景的Logstash架构基本如下。
我们从.json文件中读取我们的航班数据,我们对它们进行处理/转换,应用一些过滤器并将它们存储到ElasticSearch中。
Logstash安装
有几种选择来安装Logstash。
一种是访问网站下载你平台的存档,然后解压到一个文件夹。
你也可以使用你的平台的包管理器来安装,比如yum、apt-get或homebrew,或者作为docker镜像来安装。
确保你已经定义了一个环境变量JAVA_HOME,指向JDK 8或11或14的安装(Logstash自带嵌入式AdoptJDK)。
Logstash工作流
一旦你安装了它,让我们通过运行最基本的Logstash工作流来测试你的Logstash安装情况。
bin/logstash -e 'input { stdin { } } output { stdout {} }'
上面的工作流接受来自stdin(即你的键盘)的输入,并将其输出到stdout(即你的屏幕)。
上面的工作流中没有定义任何过滤器。一旦你看到logstash被成功启动的消息,输入一些东西(我输入的是Hello world),按ENTER键,你应该看到产生的消息的结构格式,像下面这样。
[2021-02-11T21:52:57,120][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
Hello world
{
"message" => "Hello world",
"@version" => "1",
"@timestamp" => 2021-02-11T19:57:46.208Z,
"host" => "MacBook-Pro.local"
}
然而,通常Logstash是通过配置文件来工作的,配置文件告诉它该做什么,即在哪里找到它的输入,如何转换它,在哪里存储它。Logstash配置文件的结构基本上包括三个部分:输入、过滤和输出。
你在输入部分指定数据的来源,在输出部分指定目的地。在过滤器部分,你可以使用支持的过滤器插件来操作、测量和创建事件。
配置文件的结构如下面的代码示例所示。
input {...}
filter {...}
output{...}
你需要创建一个配置文件,指定你要使用的组件和每个组件的设置。在config文件夹中已经存在一个配置文件样本,logstash-sample.conf。
其内容如下所示。
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
这里input部分定义了Logstash应该从哪里获取数据。这里有一个可用的输入插件列表。
我们的输入不是来自Beats组件,而是来自文件系统,所以我们使用文件输入组件。
input {
file {
start_position => "beginning"
path => "/usr/local/Cellar/logstash-full/7.11.0/data/flightdata/test.json"
codec => "json"
}
}
我们使用start_position参数来告诉插件从头开始读取文件。
需要注意,数据路径必须是绝对的。
我们使用的是json编解码器,除了json,还可以使用纯文本形式。
在下载的数据中,可以找到一个名为test.json的文件。它只由2条航班数据组成的文件。
输出块定义了Logstash应该在哪里存储数据。我们将使用ElasticSearch来存储我们的数据。
我们添加了第二个输出作为我们的控制台,并使用rubydebugger格式化输出,第三个输出作为文件系统,最后两个用于测试我们的输出。 我们将输出存储在output.json中。
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "testflight"
}
file {
path => "/usr/local/Cellar/logstash-full/7.11.0/data/output.json"
}
stdout {
codec => rubydebug
}
}
此外,还可以定义过滤器来对数据进行转换。
Logstash提供了大量的过滤器,下面介绍一些非常常用的的过滤器:
- grok:解析任何任意文本并添加结构,它包含120种内置模式
- mutate:对字段进行一般的转换,例如重命名、删除、替换和修改字段
- drop:丢弃一个数据
- clone:复制一个数据,可能增加或删除字段
- geoip:添加IP地址的地理位置信息
- split:将多行消息、字符串或数组分割成不同的数据
可以通过执行下方命令查看 Logstash 安装中安装的全部插件列表。
$ bin/logstash-plugin list
你会注意到,有一个JSON过滤器插件。这个插件可以解析.json文件并创建相应的JSON数据结构。
正确地选择和配置过滤器是非常重要的,否则,你最终的输出中没有数据。
所以,在我们的过滤块中,我们启用json插件,并告诉它我们的数据在消息字段中。
filter {
json {
source => "message"
}
}
到此为止,完成的配置文件config/testflight.conf内容如下:
input {
file {
start_position => "beginning"
path => "/usr/local/Cellar/logstash-full/7.11.0/data/flightdata/test.json"
codec => "json"
}
}
filter {
json {
source => "message"
}
}
output {
# elasticsearch {
# hosts => ["http://localhost:9200/"]
# index => "testflight"
# }
file {
path => "/usr/local/Cellar/logstash-full/7.11.0/data/output.json"
}
stdout {
codec => rubydebug
}
}
你可以通过如下命令进行一下测试:
bin/logstash -f config/testflight.conf --config.test_and_exit
...
Configuration OK
[2021-02-11T23:15:38,997][INFO ][logstash.runner ] Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash
如果配置文件通过了配置测试,用以下命令启动Logstash。
bin/logstash -f config/testflight.conf --config.reload.automatic
...
–config.reload.automatic配置选项可以实现自动重载配置,这样你就不必每次修改配置文件时都要停止并重新启动Logstash。
如果一切顺利,你应该会看到如下的输出结果。
{
"CMsgs" => 1,
"@version" => "1",
"PosTime" => 1467378028852,
"Rcvr" => 1,
"EngMount" => 0,
"Tisb" => false,
"Mil" => false,
"Trt" => 2,
"Icao" => "A0835D",
"Long" => -82.925616,
"InHg" => 29.9409447,
"VsiT" => 1,
"ResetTrail" => true,
"CallSus" => false,
"@timestamp" => 2021-02-14T18:32:16.337Z,
"host" => "MacBook-Pro.local",
"OpIcao" => "RPA",
"Man" => "Embraer",
"GAlt" => 2421,
"TT" => "a",
"Bad" => false,
"HasSig" => true,
"TSecs" => 1,
"Vsi" => 2176,
"EngType" => 3,
"Reg" => "N132HQ",
"Alt" => 2400,
"Species" => 1,
"FlightsCount" => 0,
"WTC" => 2,
"Cos" => [
[0] 39.984322,
[1] -82.925616,
[2] 1467378028852.0,
[3] nil
],"message" => "{"Id":10519389,"Rcvr":1,"HasSig":true,"Sig":0,"Icao":"A0835D","Bad":false,"Reg":"N132HQ","FSeen":"\/Date(1467378028852)\/","TSecs":1,"CMsgs":1,"Alt":2400,"GAlt":2421,"InHg":29.9409447,"AltT":0,"Lat":39.984322,"Long":-82.925616,"PosTime":1467378028852,"Mlat":true,"Tisb":false,"Spd":135.8,"Trak":223.2,"TrkH":false,"Type":"E170","Mdl":"2008 EMBRAER-EMPRESA BRASILEIRA DE ERJ 170-200 LR","Man":"Embraer","CNum":"17000216","Op":"REPUBLIC AIRLINE INC - INDIANAPOLIS, IN","OpIcao":"RPA","Sqk":"","Vsi":2176,"VsiT":1,"WTC":2,"Species":1,"Engines":"2","EngType":3,"EngMount":0,"Mil":false,"Cou":"United States","HasPic":false,"Interested":false,"FlightsCount":0,"Gnd":false,"SpdTyp":0,"CallSus":false,"ResetTrail":true,"TT":"a","Trt":2,"Year":"2008","Cos":[39.984322,-82.925616,1467378028852.0,null]}",
"Lat" => 39.984322,
"TrkH" => false,
"Op" => "REPUBLIC AIRLINE INC - INDIANAPOLIS, IN",
"Engines" => "2",
"Sqk" => "",
"Id" => 10519389,
"Gnd" => false,
"CNum" => "17000216",
"path" => "/usr/local/Cellar/logstash-full/7.11.0/data/flightdata/test.json",
"Cou" => "United States",
"HasPic" => false,
"FSeen" => "/Date(1467378028852)/",
"Interested" => false,
"Mdl" => "2008 EMBRAER-EMPRESA BRASILEIRA DE ERJ 170-200 LR",
"Spd" => 135.8,
"Sig" => 0,
"Trak" => 223.2,
"Year" => "2008",
"SpdTyp" => 0,
"AltT" => 0,
"Type" => "E170",
"Mlat" => true
}
数据转换
首先,让我们从输出中删除path, @version, @timestamp, host和message,这些都是logstash添加的。
filter {
json {
source => "message"
}
mutate {
remove_field => ["path", "@version", "@timestamp", "host", "message"]
}
}
mutate过滤器组件可以删除不需要的字段。
重新运行:
bin/logstash -f config/flightdata-logstash.conf –-config.test_and_exit
bin/logstash -f config/flightdata-logstash.conf --config.reload.automatic
接下来,我们将_id设置为Id。
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "testflight"
document_id => "%{Id}"
}
我们在输出组件中通过设置document_id来实现。
然而,如果你重新运行logstash,你会发现Id字段仍然存在。
有一个窍门,在过滤插件中把它改名为[@metadata][Id],然后在输出中使用,@metadata字段被自动删除。
filter {
json {
source => "message"
}
mutate {
remove_field => ["path", "@version", "@timestamp", "host", "message"]
rename => { "[Id]" => "[@metadata][Id]" }
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "flight-logstash"
document_id => "%{[@metadata][Id]}"
}
...
现在让我们尝试解析日期。如果你还记得,这是我们在上一篇文章中没有做的事情,我们需要将日期转换为更适合人们熟悉的格式。
例如:
"FSeen" => "/Date(1467378028852)/"
需要将时间1467378028852转化成容易阅读的格式,并且去掉前后多余的字符串,通过gsub组件可以实现这项功能:
gsub => [
# get rid of /Date(
"FSeen", "/Date(", "",
# get rid of )/
"FSeen", ")/", ""
]
这里通过gsub去掉了数据中/Date()\等多余部分,输出结果为:
"FSeen" : "1467378028852"
然后把时间戳转换成熟悉的格式:
date {
timezone => "UTC"
match => ["FSeen", "UNIX_MS"]
target => "FSeen"
}
UNIX_MS是UNIX时间戳,单位是毫秒。我们匹配字段FSeen并将结果存储在同一字段中,输出结果为:
"FSeen" : "2016-07-01T13:00:28.852Z",
上述转换的完整代码如下:
mutate {
gsub => [
# get rid of /Date(
"FSeen", "/Date(", "",
# get rid of )/
"FSeen", ")/", ""
]
}
date {
timezone => "UTC"
match => ["FSeen", "UNIX_MS"]
target => "FSeen"
}
在这部分中,我们学习了如何使用Logstash将.json航班数据批量文件导入到ElasticSearch中。Logstash是一个非常方便的方式,它有很多过滤器,支持很多数据类型,你只需要学习如何编写一个配置文件就可以了!
Logstash是否适合实时数据处理?
答案是:要看情况
Logstash主要是为批处理数据而设计的,比如日志数据,也许不适合处理来自传感器的实时航班数据。文章来源:https://www.toymoban.com/news/detail-477309.html
不过,你可以参考一些参考资料,这些资料描述了如何创建可以扩展的Logstash部署,并使用Redis作为Logstash代理和Logstash中央服务器之间的中介,以便处理许多事件并实时处理它们。文章来源地址https://www.toymoban.com/news/detail-477309.html
到了这里,关于ElasticSearch从入门到精通:Logstash妙用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!