Elasticsearch官网:欢迎来到 Elastic — Elasticsearch 和 Kibana 的开发者 | Elastic
注意:Elasticsearch官网访问和加载的耗时很长!!!
Lucene官网:Apache Lucene - Welcome to Apache Lucene
目录
一、Elasticsearch入门
1. Elasticsearch介绍
2. Lucene介绍
3. 什么是Elasticsearch
4. 什么是elastic stack(ELK)?
5. 什么是Lucene?
6. 面试题
关于“谈谈你对 ES 的理解”
二、正向索引和倒排索引
1. 什么是正向索引
2. 倒排索引
2.1 什么是倒排索引
2.2 倒排索引相关概念
2.3 如何创建倒排索引
2.4 倒排索引的搜索流程
3. 正向索引和倒排索引
三、Elasticsearch基本概念
1.什么是文档(Document)
2. 什么是字段(Field)
3. 什么是索引(Index)
4. 什么是映射(mapping)
5. Elasticsearch和MySQL的对比
四、Elasticsearch的安装
五、索引库操作
思维导图
1.mapping属性
2. 创建索引
2.1 基本语法
2.2 使用格式
2.3 使用实例
3. 查询索引
3.1 基本语法
3.2 使用格式
3.3 使用实例
4. 添加新的字段到mapping
4.1 基本语法
4.2 使用格式
4.3 使用实例
5. 删除索引库
5.1 基本语法
5.2 使用格式
5.3 使用实例
六、文档操作
思维导图
1. 添加文档
1.1 基本语法
1.2 使用格式
1.3 使用实例
2. 查询文档
1.1 基本语法
3. 删除文档
1.1 基本语法
1.2 使用格式
1.3 使用实例
4.修改文档
4.1 全量修改
4.1.1 全量修改是什么
4.1.2 基本语法
4.1.3 使用格式
4.1.4 使用实例
4.2 增量修改
4.2.1 增量修改是什么
4.2.2 基本语法
4.2.3 使用格式
4.2.4 使用实例
七、 高级查询
思维导图
1. 查询的基本语法:
2. 查询所有
1. 基本语法
2. 使用格式
3. 使用实例
3. 全文检索
1. 基本语法
2. 使用格式
match
multi_match
3. 使用实例
4. 精准查询
1. 基本语法
2. 使用格式
term查询
range查询
3. 使用实例
5. 过滤查询
1. 基本语法
2. 使用格式
3. 使用实例
6. 排序查询
1. 基本语法
2. 使用格式
3. 使用实例
7. 分页查询
1. 基本语法
2. 使用格式
3. 使用实例
8. 高亮查询
1. 基本语法
2. 使用格式
3. 使用实例
9. 聚合查询
1. 使用格式
2. 使用实例
一、Elasticsearch入门
1. Elasticsearch介绍
【摘自百度百科】
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
Elasticsearch使用Lucene,并试图通过JSON和Java API提供其所有特性。它支持facetting和percolating,如果新文档与注册查询匹配,这对于通知非常有用。另一个特性称为“网关”,处理索引的长期持久性;例如,在服务器崩溃的情况下,可以从网关恢复索引。Elasticsearch支持实时GET请求,适合作为NoSQL数据存储,但缺少分布式事务。
2. Lucene介绍
【摘自百度百科】
Lucene是apache软件基金会 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
3. 什么是Elasticsearch
一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能,帮助我们从海量数据中快速找到需要的内容。
4. 什么是elastic stack(ELK)?
是以elasticsearch为核心的技术栈,包括beats、Logstash、kibana、elasticsearch
被广泛应用在日志数据分析、实时监控等领域。

5. 什么是Lucene?
Lucene是Apache的开源搜索引擎类库,提供了搜索引擎的核心API
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。
6. 面试题
关于“谈谈你对 ES 的理解”
Elasticsearch ,简称 ES 。它是建立在全文搜索引擎库 Apache Lucene 基础之上的一个开源的搜索引擎,也可以作为 NoSQL 数据库,存储任意格式的文档和数据。也可以做大数据的分析,是一个跨界开源产品。它最主要的应用场景是 ELK 的日志分析系统。另外它还有以下特点:1. 第一、采用 Master-slave 架构,实现数据的分片和备份2. 第二、使用 Java 编写,并对 Lucene 进行封装,隐藏了 Lucene 的复杂性3. 第三、能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据4. 第四、ES 提供的 Restful API,不仅简化了 ES 的操作,还支持任何语言的客户端提供 API 接口,另外 Restful API 的风格还实现了 CURD 操作、创建索引,删除索引等功能。
二、正向索引和倒排索引
1. 什么是正向索引
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
正向索引是以关键字为主码,查询时需要遍历每一个文件。每个文件都对应一个文件ID,文件内容被表示为一串关键词的集合。实际上在搜索引擎索引库中,关键词也已经转换为关键词ID。
举例:传统数据库(如MySQL)采用正向索引
如果是根据id查询,那么直接走索引,查询速度非常快。
2. 倒排索引
2.1 什么是倒排索引
【摘自百度百科】
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)
2.2 倒排索引相关概念
文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语
2.3 如何创建倒排索引
创建倒排索引是对正向索引的一种特殊处理,
将每一个文档的数据利用算法分词,得到一个个词条
创建表,每行数据包括词条、词条所在文档id、位置等信息
因为词条唯一性,可以给词条创建索引,例如hash表结构索引
2.4 倒排索引的搜索流程
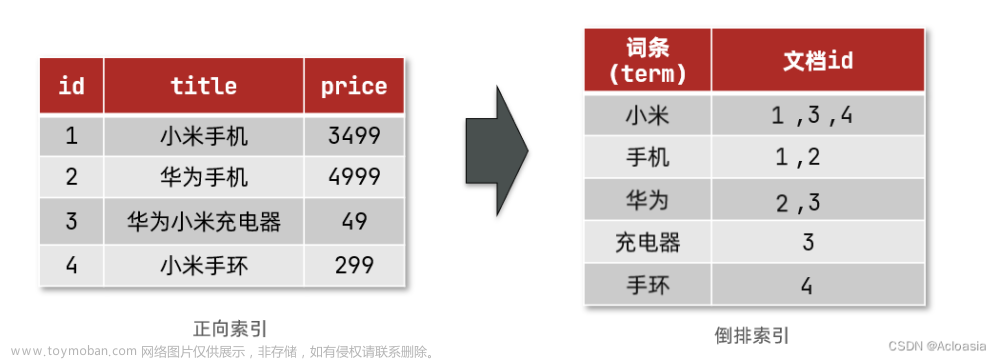
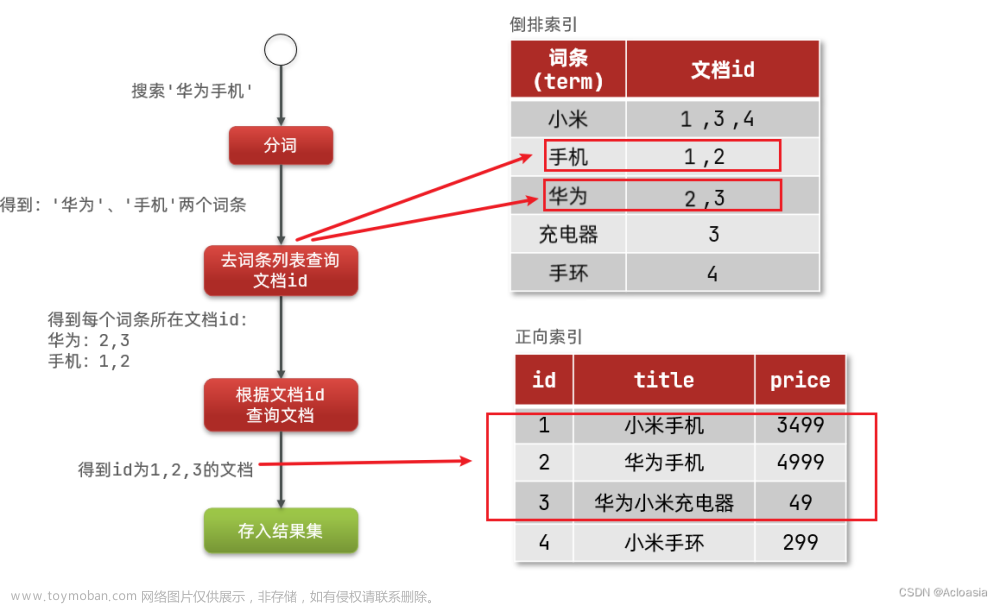
倒排索引的搜索流程如下(以搜索"华为手机"为例):
- 用户输入条件
"华为手机"进行搜索。- 对用户输入内容分词,得到词条:
华为、手机。- 拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
- 拿着文档id到正向索引中查找具体文档
3. 正向索引和倒排索引
正向索引:
优点:
可以给多个字段创建索引
根据索引字段搜索、排序速度非常快
缺点:
根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描
倒排索引:
优点:
根据词条搜索、模糊搜索时,速度非常快
缺点:
只能给词条创建索引,而不是字段
无法根据字段做排序
三、Elasticsearch基本概念
1.什么是文档(Document)
一条数据就是一个文档,在Elasticsearch中是按照Json格式存放
2. 什么是字段(Field)
Json文档中的字段
3. 什么是索引(Index)
通类型文档的集合
4. 什么是映射(mapping)
索引中文档的约束,比如:字段名称、类型
5. Elasticsearch和MySQL的对比
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
四、Elasticsearch的安装
本章主要介绍了 基于Docker安装Elasticsearch、Kibana、IK分词器
请跳转我的另外一篇博客文章:
基于Docker安装Elasticsearch【保姆级教程、内含图解】_elasticsearch docker 安装_Acloasia的博客-CSDN博客
五、索引库操作
思维导图
1.mapping属性
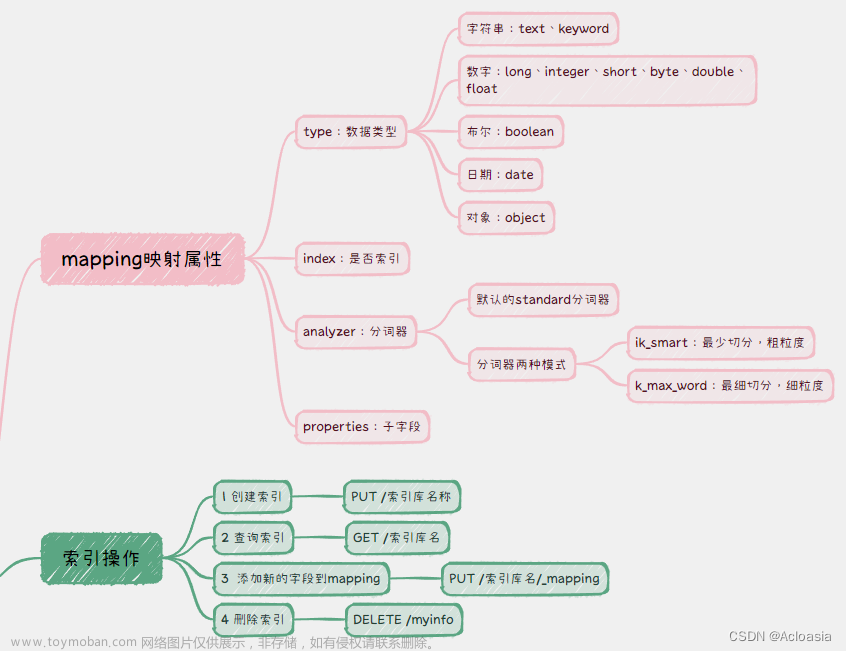
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器、
- 默认的是standard分词器
- 有两种分词模式:
- ik_smart:最少切分,粗粒度
- ik_max_word:最细切分,细粒度
- properties:该字段的子字段
举例:

2. 创建索引
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引。注意: 因此索引库一旦创建,无法修改mapping!!!2.1 基本语法
注意:索引库,不可使用大写的英文
PUT /索引库名2.2 使用格式
PUT /索引库名称 { "mappings": { "properties": { "字段名":{ "type": "text", "analyzer": "ik_smart" }, "字段名2":{ "type": "keyword", "index": "false" }, "字段名3":{ "properties": { "子字段": { "type": "keyword" } } }, // ...略 } } }2.3 使用实例
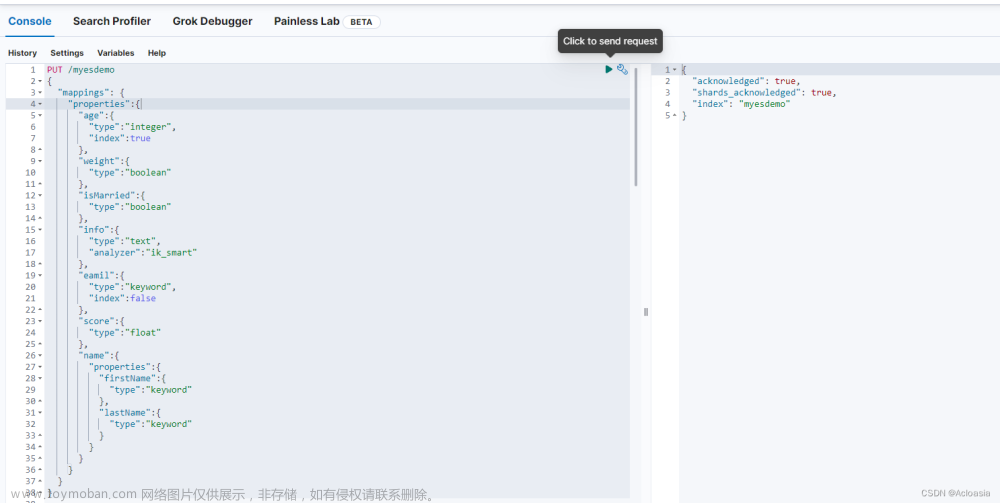
PUT /myesdemo { "mappings": { "properties":{ "age":{ "type":"integer", "index":true }, "weight":{ "type":"boolean" }, "isMarried":{ "type":"boolean" }, "info":{ "type":"text", "analyzer":"ik_smart" }, "eamil":{ "type":"keyword", "index":false }, "score":{ "type":"float" }, "name":{ "properties":{ "firstName":{ "type":"keyword" }, "lastName":{ "type":"keyword" } } } } } }
3. 查询索引
3.1 基本语法
3.2 使用格式
GET /索引库名3.3 使用实例
GET /myesdemo输出
{ "myesdemo": { "aliases": {}, "mappings": { "properties": { "age": { "type": "integer" }, "eamil": { "type": "keyword", "index": false }, "info": { "type": "text", "analyzer": "ik_smart" }, "isMarried": { "type": "boolean" }, "name": { "properties": { "firstName": { "type": "keyword" }, "lastName": { "type": "keyword" } } }, "score": { "type": "float" }, "weight": { "type": "boolean" } } }, "settings": { "index": { "routing": { "allocation": { "include": { "_tier_preference": "data_content" } } }, "number_of_shards": "1", "provided_name": "myesdemo", "creation_date": "1685289278555", "number_of_replicas": "1", "uuid": "rlCb-2bpQuKUdnwJCTH5fQ", "version": { "created": "8060099" } } } } }
4. 添加新的字段到mapping
前言有提到索引库一旦创建,无法修改mapping
但可以在已经创建的索引库,进行添加新的字段。
4.1 基本语法
4.2 使用格式
PUT /myesdemo/_mapping { "properties":{ "全新字段名":{ "type":"keyword", "index":false // .... 略 } } }4.3 使用实例
PUT /myesdemo/_mapping { "properties":{ "gender":{ "type":"keyword", "index":false } } }
5. 删除索引库
5.1 基本语法
5.2 使用格式
DELETE /索引库名5.3 使用实例
DELETE /myesdemo
六、文档操作
思维导图
1. 添加文档
1.1 基本语法
没有指定文档的id,在 ES 中会自动给我们生成一个随机的文档 id 值。
- 请求方式:POST
- 请求路径:/索引库名/_doc/文档id
- 请求参数:无
1.2 使用格式
POST /索引库名/_doc/文档id { "字段1": "值1", "字段2": "值2", "字段3": { "子属性1": "值3", "子属性2": "值4" }, // ... }1.3 使用实例
#创建一个索引库 PUT /mydemo { "mappings": { "properties":{ "age":{ "type":"integer", "index":true }, "eamil":{ "type":"keyword", "index":false }, "id":{ "type":"integer" }, "score":{ "type":"float" }, "name":{ "type":"text", "analyzer": "ik_smart" } } } } #向mydemo索引库,新镇文档 POST /mydemo/_doc/1 { "age":18, "name":"李华华", "email":"XXX@xxx.com", "id":"1", "score":"99" }
2. 查询文档
1.1 基本语法
1.2 使用格式
GET /{索引库名称}/_doc/{id}1.3 使用实例
#查询文档 GET /mydemo/_doc/1
3. 删除文档
1.1 基本语法
1.2 使用格式
DELETE /{索引库名}/_doc/id值1.3 使用实例
#删除文档 DELETE /mydemo/_doc/1
4.修改文档
4.1 全量修改
4.1.1 全量修改是什么
删除旧文档,添加新文档
4.1.2 基本语法
4.1.3 使用格式
PUT /索引库名/_doc/文档id { "字段1": "值1", "字段2": "值2", // ... 略 }4.1.4 使用实例
#全量修改,删除旧文档,添加新文档 PUT /mydemo/_doc/1 { "age":19, "name":"张三", "email":"XXX@xxx.com", "id":"2", "score":"100" }
4.2 增量修改
4.2.1 增量修改是什么
只修改指定id匹配的文档中的指定字段值
4.2.2 基本语法
4.2.3 使用格式
POST /{索引库名}/_update/文档id { "doc": { "字段名": "新的值", } }4.2.4 使用实例
#增量修改,只修改指定id匹配的文档中的指定字段值 POST /mydemo/_update/1 { "doc":{ "name":"李四" } }
七、 高级查询
思维导图
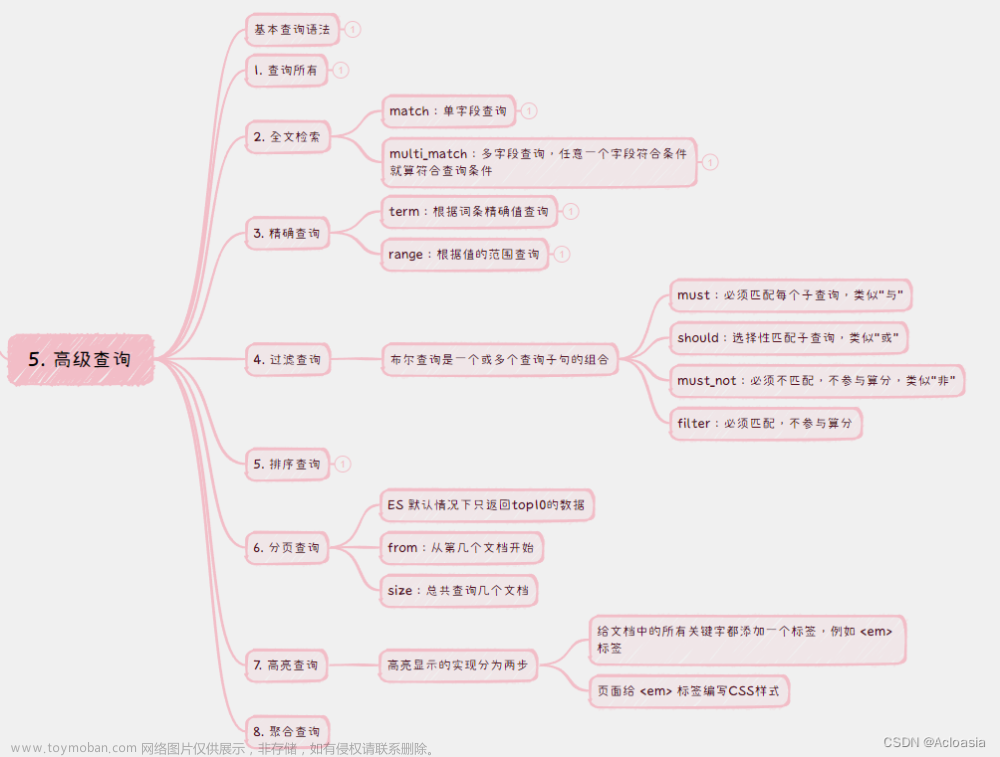
ES 提供了基于 JSON 的 DSL(Domain Specific Language)来定义查询。 文章来源:https://www.toymoban.com/news/detail-477544.html
1. 查询的基本语法:
GET /索引名称/_search { "query": { "查询类型": { "查询条件": "条件值" } } }
2. 查询所有
1. 基本语法
2. 使用格式
GET /索引名称/_search { "query": { "match_all": {} } }3. 使用实例
#查询所有 GET /mydemo/_search { "query":{ "match_all":{} } }
3. 全文检索
全文检索查询的基本流程如下:
- 对用户搜索的内容做分词,得到词条
- 根据词条去倒排索引库中匹配,得到文档id
- 根据文档id找到文档,返回给用户
比较常用的场景包括:
- 商城的输入框搜索
- 百度输入框搜索
1. 基本语法
- match:单字段查询
- multi_match:多字段查询,任意一个字段符合条件就算符合查询条件
2. 使用格式
match
GET /索引名称/_search { "query":{ "match": { "FIELD": "TEXT" } } }multi_match
在 multi_match 的参数中,query 表示要查询的字段值,而 fields 表示在那些字段中查询。 文章来源地址https://www.toymoban.com/news/detail-477544.html
GET /索引名称/_search { "query":{ "multi_match": { "query":"查询值", "fields":["查询条件1","查询条件2",...] } } }3. 使用实例
#全文检索 GET /mydemo/_search { "query":{ "match": { "age": "19" } } } GET /mydemo/_search { "query":{ "multi_match": { "query":"张飞", "fields":["name","email"] } } }
4. 精准查询
精确查询一般是查找keyword 、数值、日期、 boolean 等类型字段。所以 不会 对搜索条件分词。1. 基本语法
- term:根据词条精确值查询
- range:根据值的范围查询
2. 使用格式
term查询
#term查询 GET /索引名称/_search { "query":{ "term": { "FIELD": { "value": "VALUE" } } } }range查询
##range查询 #这里的gte代表大于等于,gt则代表大于 #lte代表小于等于,lt则代表小于 GET /索引名称/_search { "query":{ "range": { "FIELD": { "gte": "VALUE", "lte": "VALUE" } } } }3. 使用实例
###精确查询 ##term查询 GET /mydemo/_search { "query":{ "term": { "age": { "value": "19" } } } } ##range查询 #这里的gte代表大于等于,gt则代表大于 #lte代表小于等于,lt则代表小于 GET /mydemo/_search { "query":{ "range": { "age": { "gte": "18", "lte": "19" } } } } }
5. 过滤查询
布尔查询是一个或多个查询子句的组合,每一个子句就是一个 子查询1. 基本语法
2. 使用格式
#过滤查询 GET /索引名称/_search { "query":{ "bool": { "must": [ {"term": { "FIELD": { "value": "VALUE" } }} ], "should": [ {"term": { "FIELD": { "value": "VALUE" } }} ], "must_not": [ {"term": { "FIELD": { "value": "VALUE" } }} ], "filter": [ {"term": { "FIELD": "VALUE" }} ] } } }3. 使用实例
#过滤查询 GET /mydemo/_search { "query": { "bool": { "must": [ {"term": { "age": { "value": "19" } }} ], "should": [ {"term": { "eamil": { "value": "重庆" } }} ] } } }
6. 排序查询
ES 默认是根据相关度算分( _score )来排序,但是也支持自定义方式对搜索 结果排序1. 基本语法
2. 使用格式
#排序查询 #排序字段、排序方式 #ASC 升序排列 #DESC 降序排列 GET /索引名称/_search { "query":{ "match_all": {} }, "sort": [ { "FIELD": { "order": "排序方式" } } ] } }3. 使用实例
#排序查询 GET /mydemo/_search { "query":{ "match_all": {} }, "sort": [ { "age": { "order": "asc" } } ] } }
7. 分页查询
ES 默认情况下只返回top10的数据如果要查询更多数据就需要修改分页参数了。ES 中通过修改from 、 size 参数来控制要返回的分页结果注意:当查询分页深度较大时,汇总数据过多,对内存和CPU会产生非常大的压力,因此 ES 会禁止 from+ size 超过10000 的请求。 (面试高频点)1. 基本语法
2. 使用格式
GET /索引名称/_search { "query": { "match_all": {} }, "from": 0, "size": 20, "sort": [ { "age": { "order": "desc" } } ] }3. 使用实例
#分页查询 GET /mydemo/_search { "query":{ "match_all": {} }, "from": 0, "size": 20, "sort": [ { "age": { "order": "desc" } } ] }
8. 高亮查询
注意: 高亮查询只能针对字段类型为 Text 的 ,不能是别的类型。默认会自动加上 <em></em> ,如果希望修改,可以在字段中指定。1. 基本语法
高亮显示的实现分为两步:
- 给文档中的所有关键字都添加一个标签,例如 <em> 标签
- 页面给 <em> 标签编写CSS样式
2. 使用格式
GET /索引名称/_search { "query": { "match": { "FIELD": "TEXT" } }, "highlight": { "fields": { "FIELD":{ "pre_tags": "<em>", "post_tags": "<em>" } } } }3. 使用实例
#高亮查询 GET /mydemo/_search { "query": { "match": { "name": "张飞" } }, "highlight": { "fields": { "name":{ } } } }
9. 聚合查询
1. 使用格式
#聚合函数 GET /索引名称/_search { "size":0, "aggs": { "NAME": { "AGG_TYPE": {} } } }2. 使用实例
GET /mydemo/_search { "size": 0, "aggs": { "aggName": { "terms": { "field": "age", "size": 10 } } } }
到了这里,关于微服务-Elasticsearch基础篇【内含思维导图】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!