第1关:基于物品的推荐算法
给用户2推荐2个商品。利用spark.mllib中的矩阵计算库,构建用户与物品的打分矩阵,然后计算物品之间的相似分数,进行推荐。实现基于用户(User CF)的协同过滤算法。文章来源地址https://www.toymoban.com/news/detail-477768.html
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.linalg.SparseVector
import org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix, IndexedRow, MatrixEntry, RowMatrix}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object ItemBasedCF {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
//读入数据
val conf = new SparkConf().setAppName("ItemBasedCFModel").setMaster("local")
val sc = new SparkContext(conf)
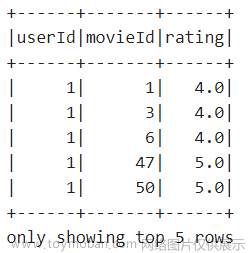
val data = sc.textFile("/root/data/als/ratingdata.txt")
/*MatrixEntry代表一个分布式矩阵中的每一行(Entry)
* 这里的每一项都是一个(i: Long, j: Long, value: Double) 指示行列值的元组tuple。
* 其中i是行坐标,j是列坐标,value是值。*/
val parseData: RDD[MatrixEntry] =
data.map(_.split(",") match { case Array(user, item, rate) => MatrixEntry(user.toLong, item.toLong, rate.toDouble) })
//CoordinateMatrix是Spark MLLib中专门保存user_item_rating这种数据样本的
val ratings = new CoordinateMatrix(parseData)
/* 由于CoordinateMatrix没有columnSimilarities方法,所以我们需要将其转换成RowMatrix矩阵,调用他的columnSimilarities计算其相似性
* RowMatrix的方法columnSimilarities是计算,列与列的相似度,现在是user_item_rating,与基于用户的CF不同的是,这里不需要进行矩阵的转置,直接就是物品的相似*/
val matrix: RowMatrix = ratings.toRowMatrix()
//需求:为某一个用户推荐商品。基本的逻辑是:首先得到某个用户评价过(买过)的商品,然后计算其他商品与该商品的相似度,并排序;从高到低,把不在用户评价过
//商品里的其他商品推荐给用户。
//例如:为用户2推荐商品
//第一步:得到用户2评价过(买过)的商品 take(5)表示取出所有的5个用户 2:表示第二个用户
//解释:SparseVector:稀疏矩阵
val user2pred = matrix.rows.take(5)(2)
val prefs: SparseVector = user2pred.asInstanceOf[SparseVector]
val uitems = prefs.indices //得到了用户2评价过(买过)的商品的ID
val ipi = (uitems zip prefs.values) //得到了用户2评价过(买过)的商品的ID和评分,即:(物品ID,评分)
//计算物品的相似性,并输出
val similarities = matrix.columnSimilarities()
val indexdsimilar = similarities.toIndexedRowMatrix().rows.map {
case IndexedRow(idx, vector) => (idx.toInt, vector)
}
//ij表示:其他用户购买的商品与用户2购买的该商品的相似度
val ij = sc.parallelize(ipi).join(indexdsimilar).flatMap {
case (i, (pi, vector: SparseVector)) => (vector.indices zip vector.values)
}
/********** begin **********/
//ij1表示:其他用户购买过,但不在用户2购买的商品的列表中的商品和评分
val ij1 = ij.filter { case (item, pref) => !uitems.contains(item) }
//将这些商品的评分求和,并降序排列,并推荐前两个物品
val ij2 = ij1.reduceByKey(_ + _).sortBy(_.文章来源:https://www.toymoban.com/news/detail-477768.html
到了这里,关于educoder-Spark机器学习的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![[机器学习、Spark]Spark MLlib机器学习](https://imgs.yssmx.com/Uploads/2024/02/511968-1.jpeg)



