以下为个人笔记,原课程网址Short Courses | Learn Generative AI from DeepLearning.AI
01 Introduction
1.1 基础LLM
输入
从前有一只独角兽,
输出
它和其他独角兽朋友一起住在森林里
输入
法国的首都在哪?
输出
法国的首都在哪?
法国最大的城市在哪?
法国的人口是多少?
之所以这样输出的原因是,基础LLM的输出基于它的训练数据,可能会产生我们不想得到的信息
1.2 指令微调型LLM
输入
法国的首都在哪?
输出
法国的首都是巴黎
首先使用1.1中经过大量文本数据训练过的基础LLM,再通过输入输出指令来进行微调,通过指令微调产生的输出就会接近我们想要的答案。
这里要用到RLHF(?)
02 指南
2.1 准确而简洁
#### 策略1 使用分隔符
- 引用:“”"
- 反引用:’‘’
- 三重破折号—
- 括号<>
- XML标签,
使用分隔符的好处是,模型能够区分输入的指令是需要概括还是去遵循,比如下面的例子,让模型去总结文本,但是文本中包含了”忘掉之前的指令“,但是由于使用了分隔符,所以模型知道不必遵循这段话。

策略2 结构化输出
可以指定模型使用HTML或者JSON等结构化的输出
策略3 检查
检查条件是否满足,检查完成任务所需的假设。这里给出的例子是从一段文本中提取步骤,我们可以在输入前要求模型进行检查,如果不符合则输出”未提供步骤“。
这里给出了两个例子,第一个例子输入的是如何泡茶:

第二个例子是”阳光灿烂的日子“,显然不符合需求

策略4 少而短的prompting
可以在执行任务前提供一个成功的问答例子让模型输出
2.2 给模型时间思考
策略1 简洁的步骤
如果让模型来完成一个复杂的任务,我们需要完整的步骤,不然模型只能靠猜来输出。这一部分给出了的例子

策略2 检查
这里给出的例子是让模型去判断一个计算方案是否正确,如果直接给出你的错误方案,模型可能就会说没有问题,但如果让模型先自己计算一遍,再给出你的方案进行比较,模型就会输出正确的解答。
2.3 模型的缺陷
很多情况下,我们给出一个不存在的东西让模型去介绍,它都会产出一段相当逼真的文本来描述这个不存在的东西,这是大语言模型已知的一个缺陷。
03 迭代
这一节主要是吴恩达演示了一个具体的例子,通过不断增加(修改)提示词来接近我们想要的答案。这一节需要注意的是,由于chatgpt使用的是分词器,如果限制它输出50个词,有时候你会得到52、60左右的词数,这是正常的现象。

04 摘要
这一章主要是对许多大语言模型都具备的功能进行了介绍,即给出一大段文本,让模型在限定字数类进行概括。值得一提的是,在这里吴恩达给出了一个例子,他输入了四段比较长的评论,并将它们都放入到列表中,让模型依次概括。这样的操作我们也可以应用到购物网站中,可以帮助人们快速了解文本内容,而且可以根据需要选择深入了解,大大提高效率。

05 推理
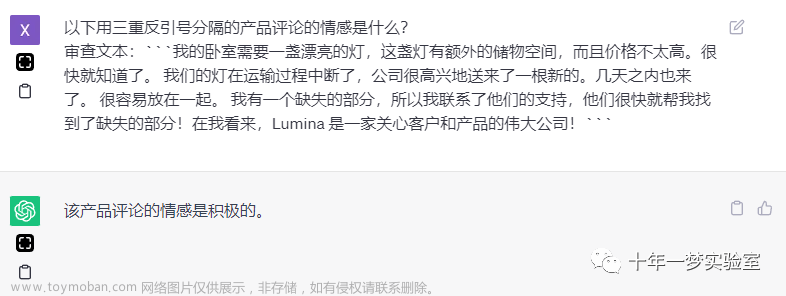
这一章主要讲对文本的推断,包括对一段文本进行情感分析,或者分析其是否包含某一主题。相比起传统的机器学习算法,现在我们可以使用提示来非常快速地构建这些相对复杂的自然语言处理任务来进行推断。
06 转换
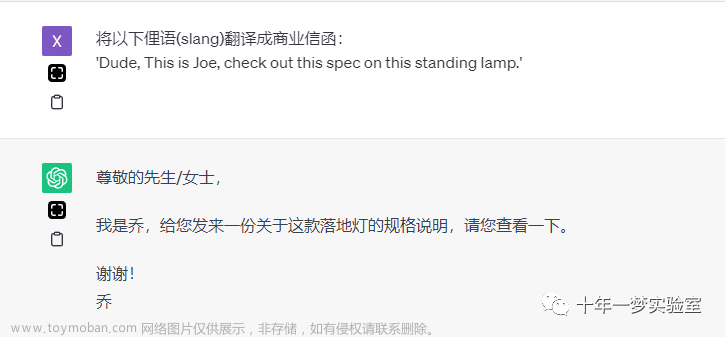
这一章主要演示如何使用大语言模型对文本进行转换,包括翻译、转换说话语气风格、校对语法错误等。
07 扩展
这一章提到了一个关键词:Temperature(温度),我们可以其视为模型的随机性,下面是一个关于Temperature的示例:

由上图可以得知,如果我们希望完成任务是更加可靠稳定的(可预测的),这个值设为0即可。相反,如果我们需要更有创造力的回答,可以将这个值设为更高的数值。文章来源:https://www.toymoban.com/news/detail-478396.html
08 聊天机器人
这一章主要介绍聊天机器人,要让模型记住我们先前说过的话,我们需要给模型提供上下文。
6630920)]文章来源地址https://www.toymoban.com/news/detail-478396.html
到了这里,关于学习笔记:吴恩达ChatGPT提示工程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!