ES的默认中文分词效果太差了,稍微长一点的词句就完全匹配不到,于是选择使用安装IK中文分词器来实现索引的分词。
参考:
https://blog.csdn.net/w1014074794/article/details/119762827
https://www.bbsmax.com/A/6pdDqDaXzw/

一、安装
官网教程:
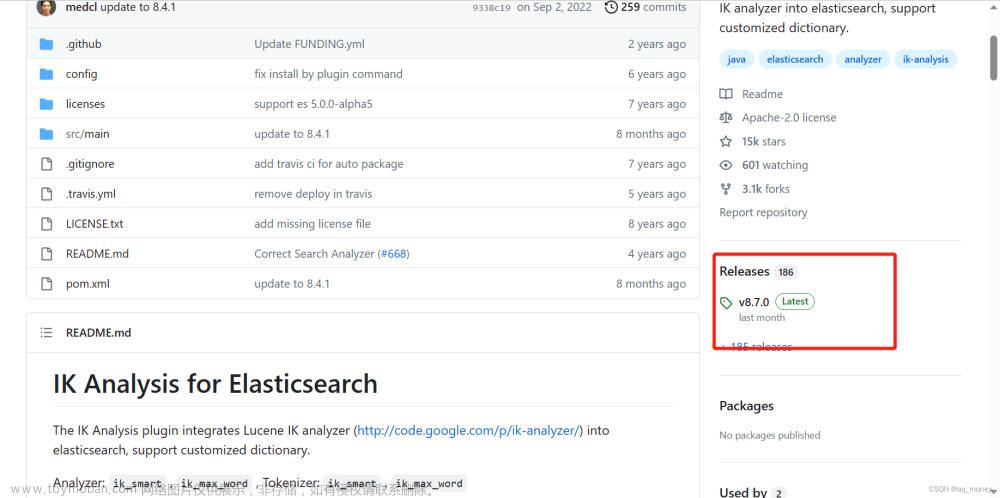
https://github.com/medcl/elasticsearch-analysis-ik,注意版本对应的问题

1.下载
从此处下载预构建包:https ://github.com/medcl/elasticsearch-analysis-ik/releases
根据版本匹配,我使用的是ES7.10.2,因此要下载对应ik7.10.2(如果版本不匹配的话,ik分词器会无法使用)

2.解压
在ES安装文件夹下的plugins文件夹下创建ik目录,将zip文件解压到ik目录下,删除zip

3.重新启动ES后测试
(1)原生分词器效果
GET /_analyze
{
"analyzer": "standard",
"text": "中华人民共和国"
}
(2)ik分词器效果
①ik_max_word
会把文本做最细粒度的解析,会穷尽各种可能的组合,适合词条查询;
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国"
}
②ik_smart
会做最粗粒度的拆分,适合短语查询。
GET /_analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国"
}
二、项目使用
删除之前的索引,创建新的指定分词器的索引(对相应字段设定分词器),并将数据重新导入后测试检索效果
索引字段详解:https://www.cnblogs.com/hld123/p/16538466.html
fields可以让同一文本有多种不同的索引方式,比如所示一个String类型的字段city,可以使用text类型做全文检索,使用keyword类型做聚合和排序。
PUT index_name
{
"mappings": { # 设置 mappings
"properties": { # 属性,固定写法
"city": { # 字段名
"type": "text", # city 字段的类型为 text
"fields": { # 多字段域,固定写法
"raw": { # 子字段名称
"type": "keyword" # 子字段类型
"ignore_above": 256 #在ElasticSearch中keyword,text类型字段ignore_above属性(动态映射默认是256) ,表示最大的字段值长度,超出这个长度的字段将不会被索引,查询不到,但是会存储。
}
}
}
}
}
}通过analyzer属性指定写入分词器采用细粒度模式
ik_max_word;通过search_analyzer属性指定查询时采用智能模式ik_smart

1.创建json对象作为索引mapping
由于数据类型较多,使用json文件,将其装换为json对象
(1)pom.xml
<!--json文件转json对象-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.54</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-io</artifactId>
<version>1.3.2</version>
</dependency>(2)JsonUtil
package org.project.es.common.util;
import java.io.InputStream;
import org.apache.commons.io.IOUtils;
import com.alibaba.fastjson.JSONObject;
/**
* 将json文件装换为json对象
* @author Administrator
*/
public class JsonUtil {
public static JSONObject fileToJson(String fileName) {
JSONObject json = null;
try (
InputStream is = Thread.currentThread().getContextClassLoader().getResourceAsStream(fileName);
) {
json = JSONObject.parseObject(IOUtils.toString(is, "utf-8"));
} catch (Exception e) {
System.out.println(fileName + "文件读取异常" + e);
}
return json;
}
public static void main(String[] args) {
String fileName = "doc/policy.json";
JSONObject json = JsonUtil.fileToJson(fileName);
System.out.println(json);
}
}
2.创建索引
public static void createIndex(RestHighLevelClient client,String index) throws IOException {
// 1.创建索引 - 请求对象
CreateIndexRequest request = new CreateIndexRequest(index);
// 2.设置setting,也就是索引的基本配置信息,将setting添加到请求对象中
Settings setting = Settings.builder()
//设置分片数,主分片数量一旦设置后就不能修改了
.put("index.number_of_shards", 1)
//索引的刷新时间间隔,索引更新多久才对搜索可见(即数据写入es到可以搜索到的时间间隔,设置越小越靠近实时,但是索引的速度会明显下降,),
// 默认为1秒,如果我们对实时搜索没有太大的要求,反而更注重索引的速度,那么我们就应该设置的稍微大一些,这里设置30s
.put("index.refresh_interval", "30s")
//每个节点上允许最多分片数
.put("index.routing.allocation.total_shards_per_node", 3)
//将数据同步到磁盘的频率,为了保证性能,插入ES的数据并不会立刻落盘,而是首先存放在内存当中,
// 等到条件成熟后触发flush操作,内存中的数据才会被写入到磁盘当中
.put("index.translog.sync_interval", "30s")
//每个主分片拥有的副本数,副本数量可以修改
.put("index.number_of_replicas", 1)
//一次最多获取多少条记录
.put("index.max_result_window", "10000000")
.build();
request.settings(setting);
// 3.使用工具类将json文件转换为json对象,添加到请求对象中
JSONObject mapping = JsonUtil.fileToJson("doc/policy.json");
request.mapping(mapping);
// 4.发送请求,获取响应
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
boolean acknowledged = response.isAcknowledged();
// 5.输出响应状态
System.out.println("操作状态 = " + acknowledged);
}查看索引

3.导入数据
索引创建好之后将mysql数据导入es,便于检索
4.测试检索文章来源:https://www.toymoban.com/news/detail-478511.html
之前使用默认分词器的效果很差,检索结果不尽如人意,在安装使用了IK分词器后再次检索测试,发现效果不错,检索速度也很快文章来源地址https://www.toymoban.com/news/detail-478511.html

到了这里,关于ES搜索框架--设置IK分词器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!