1. 相关配置
系统:win 10
YOLO版本:yolov5 5.0
拍摄视频设备:安卓手机
电脑显卡:NVIDIA 2080Ti(CPU也可以跑,GPU只是起到加速推理效果)
2. 测距源码
详见文章 YOLOV5 + 单目测距(python)
3. PYQT环境配置
首先安装一下pyqt5
pip install PyQt5
pip install PyQt5-tools
接着再pycharm设置里配置一下
添加下面两个工具:
工具1:Qt Designer
Program D:\Anaconda3\Lib\site-packages\qt5_applications\Qt\bin\designer.exe#代码所用环境路径
Arauments : $FileName$
Working directory :$FileDir$

工具2:PyUIC
Program D:\Anaconda3\Scripts\pyuic5.exe
Arguments : $FileName$ -o $FileNameWithoutExtension$.py
Working directory :$FileDir$

4. 实验
4.1 下载源码1
实验采用的是一个博主的开源代码,以此代码为基础添加了测距部分,下载 开源代码
4.2 创建distance.py文件
将以下代码写入distance.py文件
foc = 1990.0 # 镜头焦距
real_hight_person = 66.9 # 行人高度
real_hight_car = 57.08 # 轿车高度
# 自定义函数,单目测距
def person_distance(h):
dis_inch = (real_hight_person * foc) / (h - 2)
dis_cm = dis_inch * 2.54
dis_cm = int(dis_cm)
dis_m = dis_cm/100
return dis_m
def car_distance(h):
dis_inch = (real_hight_car * foc) / (h - 2)
dis_cm = dis_inch * 2.54
dis_cm = int(dis_cm)
dis_m = dis_cm/100
return dis_m
具体焦距怎么获得,可以参考我的这篇文章 YOLOV5 + 单目测距(python)
4.3 创建py文件
在文件目录下创建一个main-ceju-pyqt.py文件,将以下代码写入此文件
from PyQt5.QtWidgets import QApplication, QMainWindow, QFileDialog, QMenu, QAction
from main_win.win import Ui_mainWindow
from PyQt5.QtCore import Qt, QPoint, QTimer, QThread, pyqtSignal
from PyQt5.QtGui import QImage, QPixmap, QPainter, QIcon
import sys
import os
import json
import numpy as np
import torch
import torch.backends.cudnn as cudnn
import os
import time
import cv2
from models.experimental import attempt_load
from utils.datasets import LoadImages, LoadWebcam
from utils.CustomMessageBox import MessageBox
# LoadWebcam 的最后一个返回值改为 self.cap
from utils.general import check_img_size, check_requirements, check_imshow, colorstr, non_max_suppression, \
apply_classifier, scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path, save_one_box
from utils.plots import colors, plot_one_box, plot_one_box_PIL
from utils.torch_utils import select_device, load_classifier, time_sync
from utils.capnums import Camera
from dialog.rtsp_win import Window
from distance import person_distance,car_distance
class DetThread(QThread):
send_img = pyqtSignal(np.ndarray)
send_raw = pyqtSignal(np.ndarray)
send_statistic = pyqtSignal(dict)
# 发送信号:正在检测/暂停/停止/检测结束/错误报告
send_msg = pyqtSignal(str)
send_percent = pyqtSignal(int)
send_fps = pyqtSignal(str)
def __init__(self):
super(DetThread, self).__init__()
self.weights = 'yolov5s.pt' # 设置权重
self.current_weight = 'yolov5s.pt' # 当前权重
self.source = '0' # 视频源
self.conf_thres = 0.25 # 置信度
self.iou_thres = 0.45 # iou
self.jump_out = False # 跳出循环
self.is_continue = True # 继续/暂停
self.percent_length = 1000 # 进度条
self.rate_check = True # 是否启用延时
self.rate = 100 # 延时HZ
@torch.no_grad()
def run(self,
imgsz=640, # inference size (pixels)
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=True, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project='runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
):
# Initialize
try:
device = select_device(device)
half &= device.type != 'cpu' # half precision only supported on CUDA
# Load model
model = attempt_load(self.weights, map_location=device) # load FP32 model
num_params = 0
for param in model.parameters():
num_params += param.numel()
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check image size
names = model.module.names if hasattr(model, 'module') else model.names # get class names
if half:
model.half() # to FP16
# Dataloader
if self.source.isnumeric() or self.source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://')):
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadWebcam(self.source, img_size=imgsz, stride=stride)
# bs = len(dataset) # batch_size
else:
dataset = LoadImages(self.source, img_size=imgsz, stride=stride)
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
count = 0
# 跳帧检测
jump_count = 0
start_time = time.time()
dataset = iter(dataset)
while True:
# 手动停止
if self.jump_out:
self.vid_cap.release()
self.send_percent.emit(0)
self.send_msg.emit('停止')
break
# 临时更换模型
if self.current_weight != self.weights:
# Load model
model = attempt_load(self.weights, map_location=device) # load FP32 model
num_params = 0
for param in model.parameters():
num_params += param.numel()
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check image size
names = model.module.names if hasattr(model, 'module') else model.names # get class names
if half:
model.half() # to FP16
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
self.current_weight = self.weights
# 暂停开关
if self.is_continue:
path, img, im0s, self.vid_cap = next(dataset)
# jump_count += 1
# if jump_count % 5 != 0:
# continue
count += 1
# 每三十帧刷新一次输出帧率
if count % 30 == 0 and count >= 30:
fps = int(30/(time.time()-start_time))
self.send_fps.emit('fps:'+str(fps))
start_time = time.time()
if self.vid_cap:
percent = int(count/self.vid_cap.get(cv2.CAP_PROP_FRAME_COUNT)*self.percent_length)
self.send_percent.emit(percent)
else:
percent = self.percent_length
statistic_dic = {name: 0 for name in names}
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
pred = model(img, augment=augment)[0]
# Apply NMS
pred = non_max_suppression(pred, self.conf_thres, self.iou_thres, classes, agnostic_nms, max_det=max_det)
# Process detections
for i, det in enumerate(pred): # detections per image
im0 = im0s.copy()
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Write results
for *xyxy, conf, cls in reversed(det):
x1 = int(xyxy[0])
y1 = int(xyxy[1])
x2 = int(xyxy[2])
y2 = int(xyxy[3])
h = y2 - y1
if names[int(cls)] == "person":
c = int(cls) # integer class 整数类 1111111111
statistic_dic[names[c]] += 1
label = None if hide_labels else (
names[c] if hide_conf else f'{names[c]} {conf:.2f}') # 111
dis_m = person_distance(h)
label += f' {dis_m}m'
txt = '{0}'.format(label)
# annotator.box_label(xyxy, txt, color=(255, 0, 255))
plot_one_box(xyxy, im0, label=label, color=colors(c, True),
line_thickness=line_thickness)
if names[int(cls)] == "car":
c = int(cls) # integer class 整数类 1111111111
statistic_dic[names[c]] += 1
label = None if hide_labels else (
names[c] if hide_conf else f'{names[c]} {conf:.2f}') # 111
dis_m = car_distance(h)
label += f' {dis_m}m'
plot_one_box(xyxy, im0, label=label, color=colors(c, True),
line_thickness=line_thickness)
# 控制视频发送频率
if self.rate_check:
time.sleep(1/self.rate)
# print(type(im0s))
self.send_img.emit(im0)
self.send_raw.emit(im0s if isinstance(im0s, np.ndarray) else im0s[0])
self.send_statistic.emit(statistic_dic)
if percent == self.percent_length:
self.send_percent.emit(0)
self.send_msg.emit('检测结束')
# 正常跳出循环
break
except Exception as e:
self.send_msg.emit('%s' % e)
class MainWindow(QMainWindow, Ui_mainWindow):
def __init__(self, parent=None):
super(MainWindow, self).__init__(parent)
self.setupUi(self)
self.m_flag = False
# win10的CustomizeWindowHint模式,边框上面有一段空白。
# 不想看到空白可以用FramelessWindowHint模式,但是需要重写鼠标事件才能通过鼠标拉伸窗口,比较麻烦
# 不嫌麻烦可以试试, 写了一半不想写了,累死人
self.setWindowFlags(Qt.CustomizeWindowHint)
# self.setWindowFlags(Qt.FramelessWindowHint)
# 自定义标题栏按钮
self.minButton.clicked.connect(self.showMinimized)
self.maxButton.clicked.connect(self.max_or_restore)
self.closeButton.clicked.connect(self.close)
# 定时清空自定义状态栏上的文字
self.qtimer = QTimer(self)
self.qtimer.setSingleShot(True)
self.qtimer.timeout.connect(lambda: self.statistic_label.clear())
# 自动搜索模型
self.comboBox.clear()
self.pt_list = os.listdir('./pt')
self.pt_list = [file for file in self.pt_list if file.endswith('.pt')]
self.pt_list.sort(key=lambda x: os.path.getsize('./pt/'+x))
self.comboBox.clear()
self.comboBox.addItems(self.pt_list)
self.qtimer_search = QTimer(self)
self.qtimer_search.timeout.connect(lambda: self.search_pt())
self.qtimer_search.start(2000)
# yolov5线程
self.det_thread = DetThread()
self.model_type = self.comboBox.currentText()
self.det_thread.weights = "./pt/%s" % self.model_type # 权重
self.det_thread.source = '0' # 默认打开本机摄像头,无需保存到配置文件
self.det_thread.percent_length = self.progressBar.maximum()
self.det_thread.send_raw.connect(lambda x: self.show_image(x, self.raw_video))
self.det_thread.send_img.connect(lambda x: self.show_image(x, self.out_video))
self.det_thread.send_statistic.connect(self.show_statistic)
self.det_thread.send_msg.connect(lambda x: self.show_msg(x))
self.det_thread.send_percent.connect(lambda x: self.progressBar.setValue(x))
self.det_thread.send_fps.connect(lambda x: self.fps_label.setText(x))
self.fileButton.clicked.connect(self.open_file)
self.cameraButton.clicked.connect(self.chose_cam)
self.rtspButton.clicked.connect(self.chose_rtsp)
self.runButton.clicked.connect(self.run_or_continue)
self.stopButton.clicked.connect(self.stop)
self.comboBox.currentTextChanged.connect(self.change_model)
# self.comboBox.currentTextChanged.connect(lambda x: self.statistic_msg('模型切换为%s' % x))
self.confSpinBox.valueChanged.connect(lambda x: self.change_val(x, 'confSpinBox'))
self.confSlider.valueChanged.connect(lambda x: self.change_val(x, 'confSlider'))
self.iouSpinBox.valueChanged.connect(lambda x: self.change_val(x, 'iouSpinBox'))
self.iouSlider.valueChanged.connect(lambda x: self.change_val(x, 'iouSlider'))
self.rateSpinBox.valueChanged.connect(lambda x: self.change_val(x, 'rateSpinBox'))
self.rateSlider.valueChanged.connect(lambda x: self.change_val(x, 'rateSlider'))
self.checkBox.clicked.connect(self.checkrate)
self.load_setting()
def search_pt(self):
pt_list = os.listdir('./pt')
pt_list = [file for file in pt_list if file.endswith('.pt')]
pt_list.sort(key=lambda x: os.path.getsize('./pt/' + x))
if pt_list != self.pt_list:
self.pt_list = pt_list
self.comboBox.clear()
self.comboBox.addItems(self.pt_list)
def checkrate(self):
if self.checkBox.isChecked():
# 选中时
self.det_thread.rate_check = True
else:
self.det_thread.rate_check = False
def chose_rtsp(self):
self.rtsp_window = Window()
config_file = 'config/ip.json'
if not os.path.exists(config_file):
ip = "rtsp://admin:admin888@192.168.1.67:555"
new_config = {"ip": ip}
new_json = json.dumps(new_config, ensure_ascii=False, indent=2)
with open(config_file, 'w', encoding='utf-8') as f:
f.write(new_json)
else:
config = json.load(open(config_file, 'r', encoding='utf-8'))
ip = config['ip']
self.rtsp_window.rtspEdit.setText(ip)
self.rtsp_window.show()
self.rtsp_window.rtspButton.clicked.connect(lambda: self.load_rtsp(self.rtsp_window.rtspEdit.text()))
def load_rtsp(self, ip):
try:
self.stop()
MessageBox(
self.closeButton, title='提示', text='请稍等,正在加载rtsp视频流', time=1000, auto=True).exec_()
self.det_thread.source = ip
new_config = {"ip": ip}
new_json = json.dumps(new_config, ensure_ascii=False, indent=2)
with open('config/ip.json', 'w', encoding='utf-8') as f:
f.write(new_json)
self.statistic_msg('加载rtsp:{}'.format(ip))
self.rtsp_window.close()
except Exception as e:
self.statistic_msg('%s' % e)
def chose_cam(self):
try:
self.stop()
# MessageBox的作用:留出2秒,让上一次摄像头安全release
MessageBox(
self.closeButton, title='提示', text='请稍等,正在检测摄像头设备', time=2000, auto=True).exec_()
# 自动检测本机有哪些摄像头
_, cams = Camera().get_cam_num()
popMenu = QMenu()
popMenu.setFixedWidth(self.cameraButton.width())
popMenu.setStyleSheet('''
QMenu {
font-size: 16px;
font-family: "Microsoft YaHei UI";
font-weight: light;
color:white;
padding-left: 5px;
padding-right: 5px;
padding-top: 4px;
padding-bottom: 4px;
border-style: solid;
border-width: 0px;
border-color: rgba(255, 255, 255, 255);
border-radius: 3px;
background-color: rgba(200, 200, 200,50);}
''')
for cam in cams:
exec("action_%s = QAction('%s')" % (cam, cam))
exec("popMenu.addAction(action_%s)" % cam)
x = self.groupBox_5.mapToGlobal(self.cameraButton.pos()).x()
y = self.groupBox_5.mapToGlobal(self.cameraButton.pos()).y()
y = y + self.cameraButton.frameGeometry().height()
pos = QPoint(x, y)
action = popMenu.exec_(pos)
if action:
self.det_thread.source = action.text()
self.statistic_msg('加载摄像头:{}'.format(action.text()))
except Exception as e:
self.statistic_msg('%s' % e)
# 导入配置文件
def load_setting(self):
config_file = 'config/setting.json'
if not os.path.exists(config_file):
iou = 0.26
conf = 0.33
rate = 10
check = 0
new_config = {"iou": 0.26,
"conf": 0.33,
"rate": 10,
"check": 0
}
new_json = json.dumps(new_config, ensure_ascii=False, indent=2)
with open(config_file, 'w', encoding='utf-8') as f:
f.write(new_json)
else:
config = json.load(open(config_file, 'r', encoding='utf-8'))
iou = config['iou']
conf = config['conf']
rate = config['rate']
check = config['check']
self.confSpinBox.setValue(iou)
self.iouSpinBox.setValue(conf)
self.rateSpinBox.setValue(rate)
self.checkBox.setCheckState(check)
self.det_thread.rate_check = check
def change_val(self, x, flag):
if flag == 'confSpinBox':
self.confSlider.setValue(int(x*100))
elif flag == 'confSlider':
self.confSpinBox.setValue(x/100)
self.det_thread.conf_thres = x/100
elif flag == 'iouSpinBox':
self.iouSlider.setValue(int(x*100))
elif flag == 'iouSlider':
self.iouSpinBox.setValue(x/100)
self.det_thread.iou_thres = x/100
elif flag == 'rateSpinBox':
self.rateSlider.setValue(x)
elif flag == 'rateSlider':
self.rateSpinBox.setValue(x)
self.det_thread.rate = x * 10
else:
pass
def statistic_msg(self, msg):
self.statistic_label.setText(msg)
# self.qtimer.start(3000) # 3秒后自动清除
def show_msg(self, msg):
self.runButton.setChecked(Qt.Unchecked)
self.statistic_msg(msg)
def change_model(self, x):
self.model_type = self.comboBox.currentText()
self.det_thread.weights = "./pt/%s" % self.model_type
self.statistic_msg('模型切换为%s' % x)
def open_file(self):
# source = QFileDialog.getOpenFileName(self, '选取视频或图片', os.getcwd(), "Pic File(*.mp4 *.mkv *.avi *.flv "
# "*.jpg *.png)")
config_file = 'config/fold.json'
# config = json.load(open(config_file, 'r', encoding='utf-8'))
config = json.load(open(config_file, 'r', encoding='utf-8'))
open_fold = config['open_fold']
if not os.path.exists(open_fold):
open_fold = os.getcwd()
name, _ = QFileDialog.getOpenFileName(self, '选取视频或图片', open_fold, "Pic File(*.mp4 *.mkv *.avi *.flv "
"*.jpg *.png)")
if name:
self.det_thread.source = name
self.statistic_msg('加载文件:{}'.format(os.path.basename(name)))
config['open_fold'] = os.path.dirname(name)
config_json = json.dumps(config, ensure_ascii=False, indent=2)
with open(config_file, 'w', encoding='utf-8') as f:
f.write(config_json)
# 切换文件后,上一次检测停止
self.stop()
def max_or_restore(self):
if self.maxButton.isChecked():
self.showMaximized()
else:
self.showNormal()
# 继续/暂停
def run_or_continue(self):
self.det_thread.jump_out = False
if self.runButton.isChecked():
self.det_thread.is_continue = True
if not self.det_thread.isRunning():
self.det_thread.start()
source = os.path.basename(self.det_thread.source)
source = '摄像头设备' if source.isnumeric() else source
self.statistic_msg('正在检测 >> 模型:{},文件:{}'.
format(os.path.basename(self.det_thread.weights),
source))
else:
self.det_thread.is_continue = False
self.statistic_msg('暂停')
# 退出检测循环
def stop(self):
self.det_thread.jump_out = True
def mousePressEvent(self, event):
self.m_Position = event.pos()
if event.button() == Qt.LeftButton:
if 0 < self.m_Position.x() < self.groupBox.pos().x() + self.groupBox.width() and \
0 < self.m_Position.y() < self.groupBox.pos().y() + self.groupBox.height():
self.m_flag = True
def mouseMoveEvent(self, QMouseEvent):
if Qt.LeftButton and self.m_flag:
self.move(QMouseEvent.globalPos() - self.m_Position) # 更改窗口位置
# QMouseEvent.accept()
def mouseReleaseEvent(self, QMouseEvent):
self.m_flag = False
# self.setCursor(QCursor(Qt.ArrowCursor))
@staticmethod
def show_image(img_src, label):
try:
ih, iw, _ = img_src.shape
w = label.geometry().width()
h = label.geometry().height()
# 保持纵横比
# 找出长边
if iw > ih:
scal = w / iw
nw = w
nh = int(scal * ih)
img_src_ = cv2.resize(img_src, (nw, nh))
else:
scal = h / ih
nw = int(scal * iw)
nh = h
img_src_ = cv2.resize(img_src, (nw, nh))
frame = cv2.cvtColor(img_src_, cv2.COLOR_BGR2RGB)
img = QImage(frame.data, frame.shape[1], frame.shape[0], frame.shape[2] * frame.shape[1],
QImage.Format_RGB888)
label.setPixmap(QPixmap.fromImage(img))
except Exception as e:
print(repr(e))
# 实时统计
def show_statistic(self, statistic_dic):
try:
self.resultWidget.clear()
statistic_dic = sorted(statistic_dic.items(), key=lambda x: x[1], reverse=True)
statistic_dic = [i for i in statistic_dic if i[1] > 0]
results = [' '+str(i[0]) + ':' + str(i[1]) for i in statistic_dic]
self.resultWidget.addItems(results)
except Exception as e:
print(repr(e))
def closeEvent(self, event):
# 如果摄像头开着,先把摄像头关了再退出,否则极大可能可能导致检测线程未退出
self.det_thread.jump_out = True
# 退出时,保存设置
config_file = 'config/setting.json'
config = dict()
config['iou'] = self.confSpinBox.value()
config['conf'] = self.iouSpinBox.value()
config['rate'] = self.rateSpinBox.value()
config['check'] = self.checkBox.checkState()
config_json = json.dumps(config, ensure_ascii=False, indent=2)
with open(config_file, 'w', encoding='utf-8') as f:
f.write(config_json)
MessageBox(
self.closeButton, title='提示', text='请稍等,正在关闭程序。。。', time=2000, auto=True).exec_()
sys.exit(0)
if __name__ == "__main__":
app = QApplication(sys.argv)
myWin = MainWindow()
myWin.show()
sys.exit(app.exec_())
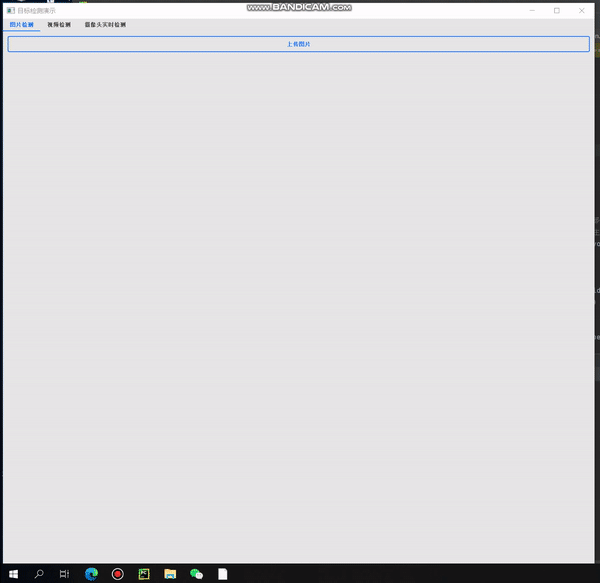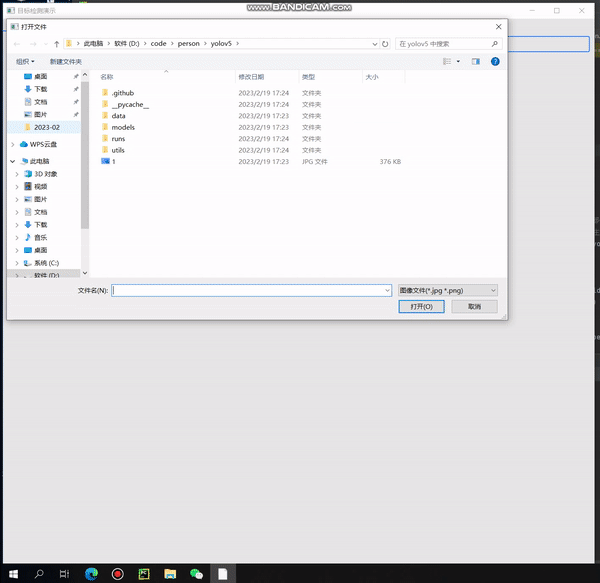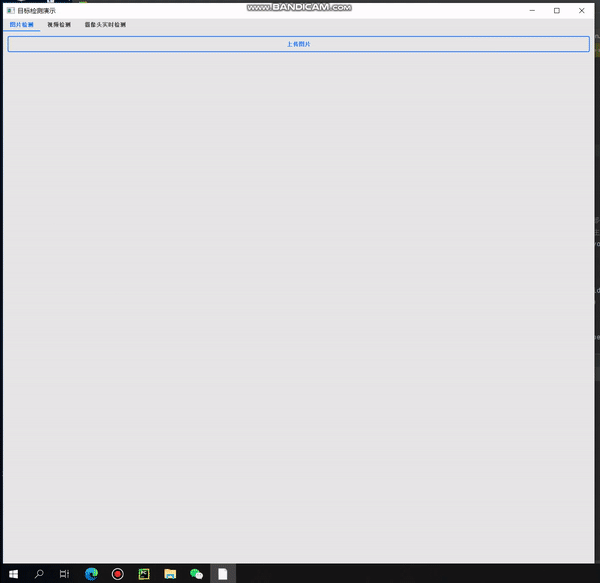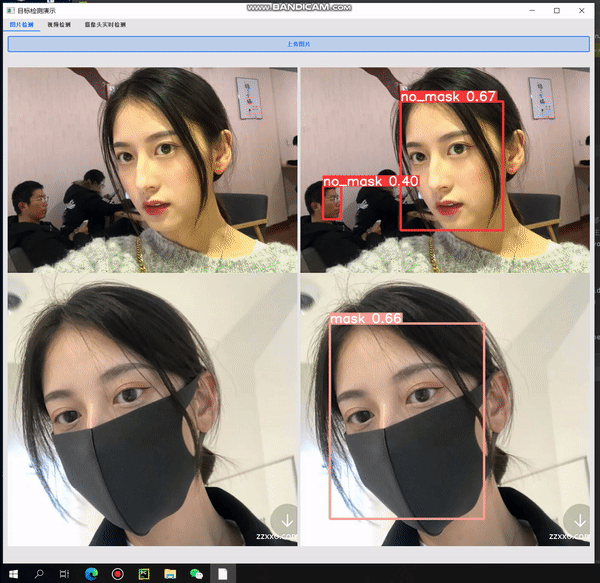
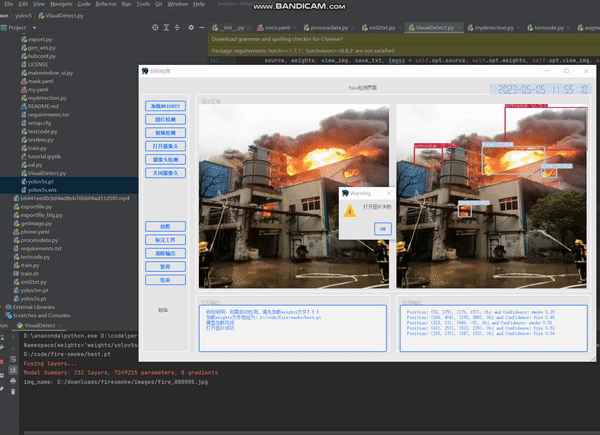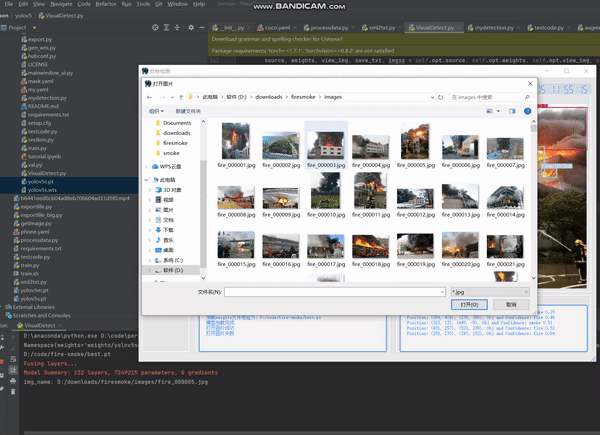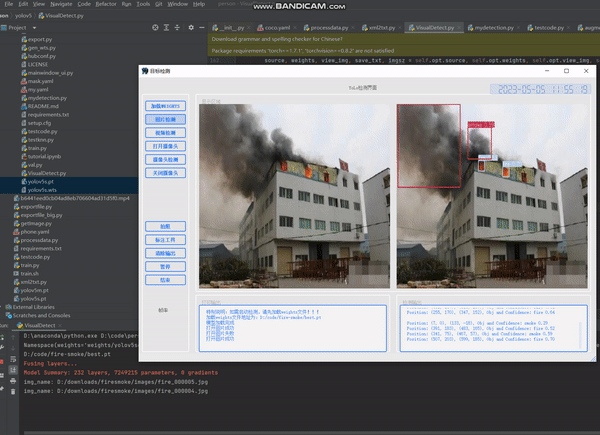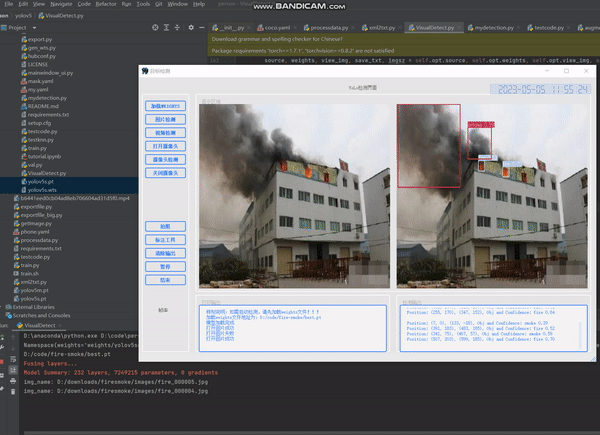
4.4 实验结果

工程源码下载:https://github.com/up-up-up-up/pyqt5-yolov5-v3.0-Monocular文章来源:https://www.toymoban.com/news/detail-478620.html
有关PYQT的内容大致就做到这里文章来源地址https://www.toymoban.com/news/detail-478620.html
到了这里,关于YOLOV5 + PYQT5单目测距(四)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!