java数据结构有:
1、数组 2、列表 (List)
3、集合(Set) 4、栈 (Stack)
5、队列 (Queue) 6、树 (Tree)
7、堆 (Heap) 8、MAP

一:数组
数组是编程语言中最常见的一种数据结构,可以用它来存储一个元素个数固定且元素类型相同的有序集,每个数组元素存放一个数据,通常可通过数组元素的索引来访问数组元素,包括为数组元素赋值和取出数组元素的值。
数组初始化:
静态初始化方式1:int[] number={......} (声明数组、创建数组和初始化数组)
静态初始化方式2:int[] number=new int{.......} (初始化数组和给数组赋值同时完成)
动态初始化方式:String[] value = new String[10] (数组的声明和初始化同时完成)
数组的特点:
1.数组是有序的
2.数组中的元素一定是为相同的数据类型
3.数组中的元素可以通过索引下标访问
4.数组的长度一经确定不可更改
5.数组一经创建在内存中开辟连续的空间
数组的操作:
1.初始化,遍历,打印,最大值,最大值下标
2.foreach增强for循环:
for(double e : list){
System.out.println(e);
}3.复制数组有三种方法:
(1)
.int[] sourceArray = {2,5,8,10,200,-20};
int[] targetArray = new int[sourceArray.length];
for(int i = 0; i < sourceArray.length; i++)
targetArray[i] = sourceArray[i];(2).使用System类中的静态方法ArrayCopy
(3).使用clone方法复制数组
4.线性查找
5.二分查找
6.选择排序
数组的优缺点:
优点:
- 按照索引查询元素的速度很快;
- 按照索引遍历数组也很方便。
缺点:
- 数组的大小在创建后就确定了,无法扩容;
- 数组只能存储一种类型的数据;
- 添加、删除元素的操作很耗时间,因为要移动其他元素。
二、列表 List

概念: List集合是一个元素有序(每个元素都有对应的顺序索引,第一个元素索引为0)、且可重复的集合。
2.1 ArrayList
ArrayList 是一个数组队列,相当于动态数组。与Java中的数组相比,它的容量能动态增长。它继承于AbstractList,实现了List, RandomAccess(随机访问), Cloneable(克隆), java.io.Serializable(可序列化)这些接口。
和Vector不同,ArrayList中的操作不是线程安全的!所以,建议在单线程中才使用ArrayList,而在多线程中可以选择Vector或者CopyOnWriteArrayList
使用:
List是Collection接口的子接口,拥有Collection所有方法外,还有一些对索引操作的方法。
-
void add(int index, E element);:将元素element插入到List集合的index处; -
boolean addAll(int index, Collection<? extends E> c);:将集合c所有的元素都插入到List集合的index起始处; -
E remove(int index);:移除并返回index处的元素; -
int indexOf(Object o);:返回对象o在List集合中第一次出现的位置索引; -
int lastIndexOf(Object o);:返回对象o在List集合中最后一次出现的位置索引; -
E set(int index, E element);:将index索引处的元素替换为新的element对象,并返回被替换的旧元素; -
E get(int index);:返回集合index索引处的对象; -
List<E> subList(int fromIndex, int toIndex);:返回从索引fromIndex(包含)到索引toIndex(不包含)所有元素组成的子集合; -
void sort(Comparator<? super E> c):根据Comparator参数对List集合元素进行排序; -
void replaceAll(UnaryOperator<E> operator):根据operator指定的计算规则重新设置集合的所有元素。 -
ListIterator<E> listIterator();:返回一个ListIterator对象,该接口继承了Iterator接口,在Iterator接口基础上增加了以下方法,具有向前迭代功能且可以增加元素:bookean hasPrevious():返回迭代器关联的集合是否还有上一个元素;E previous();:返回迭代器上一个元素;void add(E e);:在指定位置插入元素;
ArrayList的遍历方式
3种方式
- 通过迭代器遍历。即通过
Iterator去遍历。Integer value = null; Iterator iter = list.iterator(); while (iter.hasNext()) { value = (Integer)iter.next(); } -
随机访问index,通过索引值去遍历。
由于ArrayList实现了RandomAccess接口,它支持通过索引值去随机访问元素。Integer value = null; int size = list.size(); for (int i=0; i<size; i++) { value = (Integer)list.get(i); }3.增强for循环遍历。如下Integer value = null; for (Integer integ:list) { value = integ; }
ArrayList<E>使用泛型
JDK 1.5之后,引入了泛型,可指定列表内元素的类型。类型不符合的元素不允许加入数组,这样就能再编译阶段发现错误,避免运行时出错的尴尬。
// 开团
List<Girl> _泰国五日游 = new ArrayList<Girl>();
……
// 混入
Boy _b = new Boy();
//提示代码有错误: _泰国五日游.add(_b);Collection相关方法
这些方法属于Collection类,可以被子类继承,因此通用性较强,不仅List能用,Set也能用。

Arrays工具类常用方法:
1 equals():比较两个array是否相等。array拥有相同元素个数,且所有对应元素两两相等。
2 fill():将值填入array中。
3 sort():用来对array进行排序。
4 binarySearch():在排好序的array中寻找元素。
5 System.arraycopy():array的复制。
2.2 Vector
Vector是一个比较老的类,和ArrayList用法相同,在JDK 1.0即已出现,不推荐使用(虽然Vector是线程安全的,但是在线程安全方面也不推荐使用。推荐方案如下:
List<String> synList = Collections.synchronizedList(lst);2.3 链表 LinkedList
LinkedList概述
LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。LinkedList的本质是双向链表。1)LinkedList继承于AbstractSequentialList,并且实现了Dequeue接口。2) LinkedList包含两个重要的成员:header 和 size。header:是双向链表的表头,它是双向链表节点所对应的类Entry的实例。Entry中包含成员变量:previous, next, element。(其中,previous是该节点的上一个节点,next是该节点的下一个节点,element是该节点所包含的值。)size:是双向链表中节点的个数。
单链表
不需要连续的存储空间,所以在删除和增加结点时不需要像顺序表一样需要移动全部的元素,提高运行效率。

class SingleList{
Node1 head=new Node1(0,0);
//增加链表到最后
public void add(Node1 node){
Node1 temp=head;
while(true){
if(temp.next==null){
break;
}
temp=temp.next;
}
temp.next=node;
}
//按序号增加链表
public void addByOrder(Node1 node){
Node1 temp=head;
while(true){
if(temp.next==null){
break;
}
if(temp.next.no>=node.no){
break;
}
temp=temp.next;
}
node.next=temp.next;
temp.next=node;
}
//删除指定结点
public void delNode(Node1 node){
Node1 temp=head;
while(true){
if(temp.next==node){
break;
}
temp=temp.next;
}
temp.next=temp.next.next;
}
//修改单链表的结点
public void update(Node1 node,int update){
Node1 temp=head;
while(true){
if(temp.no==node.no){
break;
}
temp=temp.next;
}
temp.date=update;
}
//打印单链表
public void list(){
Node1 temp=head.next;
if(head.next==null){
System.out.println("Empty!");
}
while(temp!=null){
System.out.println(temp.toString());
temp=temp.next;
}
}
}
//创建一个类,每个类的对象就是一个结点。
class Node1{
public int date;
public int no;
public Node1 next;
public Node1(int date, int no) {
this.date = date;
this.no = no;
}
@Override
public String toString() {
return "Node1{" +
"date=" + date +
", no=" + no +
'}';
}
}
双向链表
对于单向链表而言,只有一个查找方向,并且不能自我删除。
所以引入双向链表,与单向链表的主要不同点只是在于pre指针的引入和删除操作
next:指向下一个结点。
pre:指向前一个结点。
LinkedList特点:使用链表实现,查询慢,增删快,适用于经常插入、删除大量数据的场合,适合采用迭代器Iterator遍历。
for(Iterator iter = list.iterator(); iter.hasNext();)
iter.next();LinkedList使用方法:

三、集合 (set)
set:集合注重独一无二的性质,该体系集合可以知道某物是否已近存在于集合中,不会存储重复的元素用于存储无序(存入和取出的顺序不一定相同)元素,值不能重复。
如果想要让两个不同的Person对象视为相等的,就必须覆盖Object继下来的hashCode方法和equals方法,因为Object hashCode方法返回的是该对象的内存地址,所以必须重写hashCode方法,才能保证两个不同的对象具有相同的hashCode,同时也需要两个不同对象比较equals方法会返回true
两个对象hash值相同,值不一行相等,因为可能equals()方法不等。
迭代方法:使用迭代器
public class Demo4 {
public static void main(String[] args) {
//Set 集合存和取的顺序不一致。
Set hs = new HashSet();
hs.add("世界军事");
hs.add("兵器知识");
hs.add("舰船知识");
hs.add("汉和防务");
System.out.println(hs);
// [舰船知识, 世界军事, 兵器知识, 汉和防务]
Iterator it = hs.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
} HashSet : 为快速查找设计的Set。存入HashSet的对象必须定义hashCode()。
TreeSet : 保存次序的Set, 底层为树结构。使用它可以从Set中提取有序的序列。
LinkedHashSet : 具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的次序)。于是在使用迭代器遍历Set时,结果会按元素插入的次序显示。
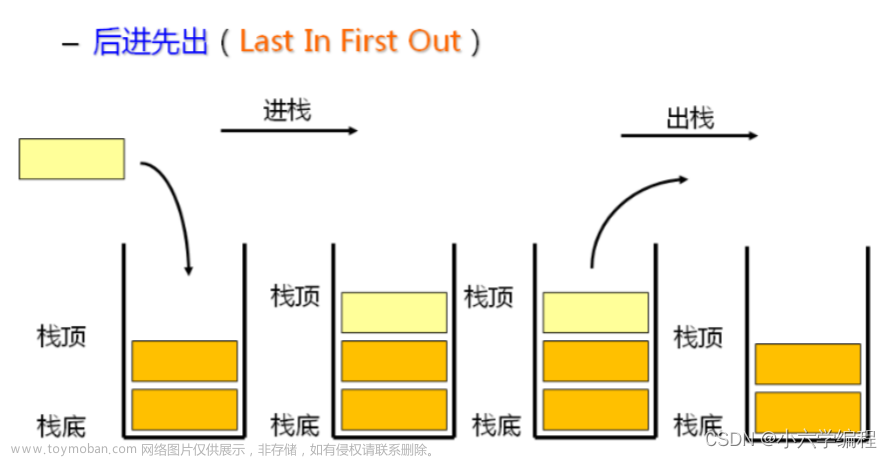
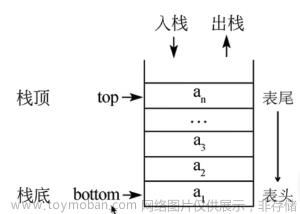
四、栈(先入后出)
特点:先入后出,变化的一端在栈顶,栈底固定,像一个桶
入栈(push):栈顶上移
出栈(pop):栈顶下移
Java中也提供了关于栈的类,便于直接调用。
数组模拟栈的思路分析:
定义top表示栈顶指针,初始为-1;
入栈:top++;
stack[top]=data;
出栈:拿到数据;top--;
/**
* max 表示栈的最大容量
* top 栈顶指针
* stack[] 用数组模拟栈
*/
class stack{
private int max;
private int top=-1;
private int stack[];
public stack(int max){
this.max=max;
stack=new int[max];
}
public boolean isFull(){
return top==max-1;
}
public boolean isEmpty(){
return top==-1;
}
//入栈
public void push(int date){
if(isFull()){
System.out.println("False");
return;
}
top++;
stack[top]=date;
}
//出栈
public int pop(){
if(isEmpty()){
throw new RuntimeException("Empty");
}
int value= stack[top];
top--;
return value;
}
//遍历
public void list(){
for(int i=top;i>=0;i--){
System.out.printf("stack[%d]=%d",i, stack[i]);
}
}
}
栈使用示例:
//1.创建一个字符型的栈
Stack<Character> stack=new Stack<>();
System.out.println(stack);
//2.测试栈是否为空
System.out.println(stack.empty());
//3.入栈
stack.push('a');
stack.push('b');
stack.push('c');
System.out.println(stack);
//4.查看栈顶元素
System.out.println(stack.peek());
System.out.println(stack);
//5.出栈
stack.pop();
System.out.println(stack);
//6.返回对象在栈中的位置
System.out.println(stack.search('b'));
System.out.println(stack.search('a'));五、队列 (先进先出)
Queue:
Queue是java中实现队列的接口,它总共只有6个方法,我们一般只用其中3个就可以了。Queue的实现类有LinkedList和PriorityQueue。最常用的实现类是LinkedList。
Queue的6个方法分类:
压入元素(添加):add()、offer()
相同:未超出容量,从队尾压入元素,返回压入的那个元素。
区别:在超出容量时,add()方法会对抛出异常,offer()返回false
弹出元素(删除):remove()、poll()
相同:容量大于0的时候,删除并返回队头被删除的那个元素。
区别:在容量为0的时候,remove()会抛出异常,poll()返回false
获取队头元素(不删除):element()、peek()
相同:容量大于0的时候,都返回队头元素。但是不删除。
区别:容量为0的时候,element()会抛出异常,peek()返回null。
public class QueueTest {
public static void main(String[] args) {
Queue<String> queue = new LinkedList();
queue.offer("元素A");
queue.offer("元素B");
queue.offer("元素C");
queue.offer("元素D");
queue.offer("元素E");
while (queue.size() > 0) {
String element = queue.poll();
System.out.println(element);
}
}
}
PriorityQueue 优先队列:
优先队列PriorityQueue是Queue接口的实现,可以对其中元素进行排序,可以放基本数据类型的包装类(如:Integer,Long等)或自定义的类对于基本数据类型的包装器类,优先队列中元素默认排列顺序是升序排列但对于自己定义的类来说,需要自己定义比较器
常用方法:
peek()//返回队首元素 poll()//返回队首元素,队首元素出队列 add()//添加元素 size()//返回队列元素个数 isEmpty()//判断队列是否为空,为空返回true,不空返回false
六、树
树定义和基本术语
定义
树(Tree)是n(n≥0)个结点的有限集T,并且当n>0时满足下列条件:
(1)有且仅有一个特定的称为根(Root)的结点;
(2)当n>1时,其余结点可以划分为m(m>0)个互不相交的有限集T1、T2 、…、Tm,每个集Ti(1≤i≤m)均为树,且称为树T的子树(SubTree)。
特别地,不含任何结点(即n=0)的树,称为空树。
如下就是一棵树的结构:

图1
基本术语
结点:存储数据元素和指向子树的链接,由数据元素和构造数据元素之间关系的引用组成。
孩子结点:树中一个结点的子树的根结点称为这个结点的孩子结点,如图1中的A的孩子结点有B、C、D
双亲结点:树中某个结点有孩子结点(即该结点的度不为0),该结点称为它孩子结点的双亲结点,也叫前驱结点。双亲结点和孩子结点是相互的,如图1中,A的孩子结点是B、C、D,B、C、D的双亲结点是A。
兄弟结点:具有相同双亲结点(即同一个前驱)的结点称为兄弟结点,如图1中B、B、D为兄弟结点。
结点的度:结点所有子树的个数称为该结点的度,如图1,A的度为3,B的度为2.
树的度:树中所有结点的度的最大值称为树的度,如图1的度为3.
叶子结点:度为0的结点称为叶子结点,也叫终端结点。如图1的K、L、F、G、M、I、J
分支结点:度不为0的结点称为分支结点,也叫非终端结点。如图1的A、B、C、D、E、H
结点的层次:从根结点到树中某结点所经路径的分支数称为该结点的层次。根结点的层次一般为1(也可以自己定义为0),这样,其它结点的层次是其双亲结点的层次加1.
树的深度:树中所有结点的层次的最大值称为该树的深度(也就是最下面那个结点的层次)。
有序树和无序树:树中任意一个结点的各子树按从左到右是有序的,称为有序树,否则称为无序树。
树的抽象数据类型描述
数据元素:具有相同特性的数据元素的集合。
结构关系:树中数据元素间的结构关系由树的定义确定。
基本操作:树的主要操作有
(1)创建树IntTree(&T)
创建1个空树T。
(2)销毁树DestroyTree(&T)
(3)构造树CreatTree(&T,deinition)
(4)置空树ClearTree(&T)
将树T置为空树。
(5)判空树TreeEmpty(T)
(6)求树的深度TreeDepth(T)
(7)获得树根Root(T)
(8)获取结点Value(T,cur_e,&e)
将树中结点cur_e存入e单元中。
(9)数据赋值Assign(T,cur_e,value)
将结点value,赋值于树T的结点cur_e中。
(10)获得双亲Parent(T,cur_e)
返回树T中结点cur_e的双亲结点。
(11)获得最左孩子LeftChild(T,cur_e)
返回树T中结点cur_e的最左孩子。
(12)获得右兄弟RightSibling(T,cur_e)
返回树T中结点cur_e的右兄弟。
(13)插入子树InsertChild(&T,&p,i,c)
将树c插入到树T中p指向结点的第i个子树之前。
(14)删除子树DeleteChild(&T,&p,i)
删除树T中p指向结点的第i个子树。
(15)遍历树TraverseTree(T,visit())
树的实现
树是一种递归结构,表示方式一般有孩子表示法和孩子兄弟表示法两种。树实现方式有很多种、有可以由广义表的递归实现,也可以有二叉树实现,其中最常见的是将树用孩子兄弟表示法转化成二叉树来实现。
树的遍历
树的遍历有两种
前根遍历
(1).访问根结点;
(2).按照从左到右的次序行根遍历根结点的第一棵子树;
后根遍历
(1).按照从左到右的次序行根遍历根结点的第一棵子树;
(2).访问根结点;
七、堆
概念:堆就是一颗顺序存储的完全二叉树,底层是一个数组。
-
堆逻辑上是一颗完全二叉树
-
堆物理上是保存在数组中
-
堆满足任意结点的值都大于其子树中结点的值,也就是所有根节点 > 其左右孩子结点,叫做大堆,或者大根堆、最大堆,反之则是小堆,或者小根堆、最小堆
-
堆的基本作用是快速找到集合中的最值
java的堆和数据结构堆:java的堆是程序员用new能得到的计算机内存的可用部分。而数据结构的堆是一种特殊的二叉树。
八、MAP
常用Map:Hashtable、HashMap、LinkedHashMap、TreeMap
类继承关系:

HashMap
1)无序; 2)访问速度快; 3)key不允许重复(只允许存在一个null Key);
LinkedHashMap
1)有序; 2)HashMap子类;
TreeMap
1)根据key排序(默认为升序); 2)因为要排序,所以key需要实现 Comparable接口,否则会报ClassCastException 异常; 3)根据key的compareTo 方法判断key是否重复。
HashTable
一个遗留类,类似于HashMap,和HashMap的区别如下:
1)Hashtable对绝大多数方法做了同步,是线程安全的,HashMap则不是;
2) Hashtable不允许key和value为null,HashMap则允许;
3)两者对key的hash算法和hash值到内存索引的映射算法不同。
HashMap
HashMap底层通过数组实现,数组中的元素是一个链表,准确的说HashMap是一个数组与链表的结合体。即使用哈希表进行数据存储,并使用链地址法来解决冲突。
HashMap的几个属性:
initialCapacity:初始容量,即数组的大小。实际采用大于等于initialCapacity且是2^N的最小的整数。
loadFactor:负载因子,元素个数/数组大小。衡量数组的填充度,默认为0.75。
threshold:阈值。值为initialCapacity和loadFactor的乘积。当元素个数大于阈值时,进行扩容。
优化点:1、频繁扩容会影响性能。设置合理的初始大小和负载因子可有效减少扩容次数。
2、一个好的hashCode算法,可以尽可能较少冲突,从而提高HashMap的访问速度。
LinkedHashMap----有序的HashMap
简单来说,HashMap+双向链表=LinkedHashMap。
HashMap是无序的,即添加的顺序和遍历元素的顺序具有不确定性。LinkedHashMap是HashMap的子类,是一种特殊的HashMap。
LinkedHashMap通过维护一个额外的双向链表(在Entry中加入 before, after属性记录该元素的前驱和后继),将所有的Entry节点链入一个双向链表,从而实现有序性。通过迭代器遍历元素是有序的。
两种排序方式:
1)元素插入顺序:accessOrder=false,默认为false;
2)最近访问顺序:accessOrder=true。此情况下,不能使用迭代器遍历集合,因为get()方法会修改Map,在迭代器模式中修改集合会报ConcurrentModificationException。可以用来实现LRU(最近最少使用)算法。
TreeMap
TreeMap实现了SortedMap,可以根据key对元素进行排序,还提供了接口对有序的key集合进行筛选。
内部基于红黑树实现,红黑树是一种平衡查找树,它的统计性能要优于平衡二叉树。可以在O(logN) 时间内做查找、插入和删除,性能较好。
如果确实需要将排序功能加入HashMap,应该使用TreeMap,而不应该自己去实现排序。
文章来源地址https://www.toymoban.com/news/detail-478628.html文章来源:https://www.toymoban.com/news/detail-478628.html
到了这里,关于Java数据结构的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!