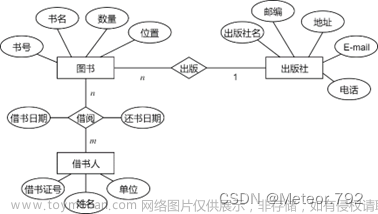
实验名称 应用sklearn分析竞标数据
实验时间 2023-04-26
(gcc的同学不要抄袭呀!)
一、实验目的
1、掌握skleam转换器的用法。
2、掌握训练集、测试集划分的方法。
3、掌握使用sklearm进行PCA降维的方法。
4、掌握 sklearn 估计器的用法。
5、掌握聚类模型的构建与评价方法。
6、掌握分类模型的构建与评价方法。
7、掌握回归模型的构建与评价方法。
二、实验仪器设备或材料
笔记本电脑,Anaconda软件
三、实验原理
任务1:使用sklearn处理竞标行为数据集。(数据集找你们老师要哦!)
1、需求说明
竞标行为数据集(shill bidding.csv)是网络交易平台eBay为了分析竞标者的竞标行为而收集整理的部分拍卖数据,包括记录ID、竞标者倾向、竞标比率等11个输入特征和I个类别标签,共6321条记录,其特征/标签说明如表6-18所示。通过读取竞标行为数据集,进行训练集和测试集的划分、为后续的模型构建提供训练数据和测试数据;并对数据集进行降维,以适当减少数据的特征维度。

任务2:构建基于竞标行为数据集的K-Means聚类模型。
1、需求说明
使用实训1中的竞标行为数据集,竞标行为标签总共分为2种(0表示正常竞标行为,1表示非正常竟标行为)为了通过竞标者的行为特征将竞标行为划分为簇,选择数据集中的竞标者倾向、竞标比率,连续竞标3个特征,构建K-Means模型,对这3个特征的数据进行聚类,聚集为2个族,实现竞标行为的类别划分,并对聚类模型进行评价,确定最优聚类数目。
任务3:构建基于竞标行为数据集的支持向量机分类模型。
1、需求说明
对实训1中的竞标行为数据集进行训练集和测试集的划分,为了对竞标者的竞标行为进行类别判断、根据训练集构建支持向量机分类模型、通过训练完成的模型判断测试集的竞标行为类别归属,并对分类模型性能进行评价。
1、需求说明
对实训1中的竞标行为数据集进行训练集和测试集的划分,为了对竞标者的竞标行为进行预测.构建线性回归模型,用训练集对线性回归模型进行训练,并对测试集进行预测;计算回归模型评价指标得分,通过得分评价回归模型的优劣。
四、实验内容与步骤
任务1:使用sklearn处理竞标行为数据集。
1、实现思路与步骤
(1)使用pandas库读取竞标行为数据集。
(2)对竞标行为数据集的数据和标签进行划分。
(3)将竞标行为数据集划分为训练集和测试集,测试集数据量占总样本数据量的20%。
(4)对竞标行为数据集进行PCA降维,设定n-components=0.999、即降维后数据能保留的信息为原来的99.9%、并查看降维后的训练集、测试集的大小。
任务2:构建基于竞标行为数据集的K-Means聚类模型。
1、实现思路与步骤
(1)选取竟标行为数据集中的竞标者倾向、竞标比率、连续竞标、类别特征。
(2)构建K-Means模型。
(3)使用ARl评价法评价建立的 K-Means模型。
(4)使用V-measure评分评价建立的K-Means模型。
(5)使用FMI评价法评价建立的 K-Means模型,并在聚类数目为1-3类时,确定最优聚类数目。
任务3:构建基于竞标行为数据集的支持向量机分类模型。
1、实现思路与步骤
(1)标准差标准化构建的训练集和测试集。
(2)构建支持向量机模刑,并预测测试集前10个数据的结果。
(3)打印分类模型评价报告、评价分类模型性能。
任务4:构建基于竞标行为数据集的回归模型。
1、实现思路与步骤
(1)根据竟标行为训练集构建线性回归模型,并预测测试集结果。
(2)分别计算线性回归模型各自的平均绝对误差、均方误差、R值。
(3)根据得分,判定模型的性能优劣。
五、实验结果与分析
任务一:
任务二:
1、ari是调整兰德指数,用于衡量聚类算法的性能。在此处评估中,ari的值为-0.004654458188395929,表示聚类效果较差,可能存在重叠或不明显的聚类。
2、v-measure是精确度和召回率的加权平均数,用于衡量聚类的准确性和完整性。在此处评估中,v-measure的值为0.000895321967423075,表示聚类效果较差,存在许多错误的分类。
3、Fmi是fowlkes-mallows index的缩写,用于度量聚类结果与真实分类之间的相似度。在此处评估中,最佳的fmi得分为1对应于第一种情况。
可以看出,这里的聚类结果并不是很好,ari和v-measure得分都较低,其中fmi指标在分为1组时得到了较高的分数。考虑重复执行该聚类算法,或者尝试使用其他算法进行聚类操作可能会改善结果。
任务三:
上图结果是支持向量机(svm)对客户数据进行分类后得出的分类报告。下面是该分类报告的含义。
1、precision:该指标衡量分类器预测为正样本中实际为正样本的比例,即正确预测 positive 的数量除以预测为 positive 的总数,代表分类器的准确性。
2、recall:recall 衡量了分类器能够找到所有正样本的能力,即正确预测 positiv 的数量除以实际为 positive 的总数。
3、f1-score:f1-score 是 precision 和 recall 的调和平均数。
4、support:support 表示每个标签在测试集中出现的个数。
分类结果:
1、在1130个负样本(0)中,有99%被分类器正确地识别为负样本。
2、在135个正样本(1)中,有89%被分类器正确地识别为正样本。
3、整体准确率(accuracy)为99%,表示所有样本都有很高的概率被分类器正确地识别。
4、macro avg 和 weighted avg 分别是各种度量的宏平均和加权平均。macro avg 作为一个宏平均值,是计算给定属性的不加权平均值,而mixed avg 对于宏型评估更关注,在困难情况下可能更准确地反映模型的性能。
任务四:
线性回归模型的评价结果如下:
1、平均绝对误差(mae)为 0.047063925786375076,代表了模型预测结果偏差的平均程度,即预测值与真实值之间的绝对差的平均值。在该模型中,预测结果与真实值的平均差距约为 0.047 左右。
2、均方误差(mse)为 0.014993267130178182,代表了模型预测结果偏差的平方的平均值。mse可视为评估模型的精度和泛化能力的一种方法。在该模型中,预测结果与真实值的平方差的平均值约为 0.015 左右。
3、r方值(r-squared)为 0.8427230357693256,又称为决定系数,是衡量模型拟合优度的一个统计量,表示模型能解释的响应变量(y)方差的比例。在该模型中,r方值为 0.84 左右,说明该模型可以解释大约 84% 的目标变量的方差,具有较高的拟合优度。
因此,这个模型的表现还不错,可以用于数据预测和分析任务。
逻辑回归模型的评价结果。模型表现被用平均绝对误差、均方误差和r方值表示:
1、平均绝对误差(mean absolute error)衡量每个预测值和实际值之间的平均距离,越小表示模型的准确性越好。
2、均方误差(mean squared error)也是度量预测值和实际值之间误差大小的方法,它计算预测值与实际值之间差的平方的平均值。均方误差同样越小越好,因为它会忽略正负误差之间的抵消效果。
3、r方值(r-squared)用于评估模型的拟合程度,一般介于0到1之间。这个数字越接近1越好,因为这意味着模型能够解释更多的数据变化,并且能够更好地进行预测。
在本例中,逻辑回归模型的平均绝对误差和均方误差非常接近,并且较小。r方值为0.77,意味着模型能够解释77%的数据变化,但还有23%的数据变化没有被解释。综合来看,这个模型表现不错,但可能需要进一步优化以提高模型的准确性和预测能力。
最近邻回归模型的三个评价指标。
1、平均绝对误差(mae):是预测值和真实值之差的绝对值的平均值。对于该模型,mae为0.0174,这意味着模型的预测值与真实的观测值的平均偏差为0.0174。
2、均方误差(mse):是预测值和真实值之差的平方的平均值。对于该模型,mse为0.0126,它是mae的平方,可以作为一个更加敏感的度量,因为它惩罚更大的误差值。
3、r方值:也称为确定系数,它是观察到的数据方差中可由模型解释的部分占总方差的比例。r方值越接近1,表示模型拟合得更好。该模型的r方值为0.857,说明预测变量中的85.7%方差可以用最近邻回归模型来解释。
综上所述,最近邻回归模型表现最好,因为mae和mse都很小,并且r方值接近1,表示该模型可以很好地描述响应变量和预测变量之间的关系。
六、结论与体会
结论:文章来源:https://www.toymoban.com/news/detail-478884.html
- Sklearn是一个非常强大的机器学习库,它可以用于各种统计分析和机器学习算法的实现。
- 对于竞标数据的分析,Sklearn可以应用在多个方面,包括预测模型、聚类分析、特征选择等等。
- 在数据分析过程中,需要对数据进行预处理和特征工程,这是确保机器学习算法能够得到最佳效果的关键步骤。
- 在进行预测模型时,使用交叉验证可以提高模型的准确性,并且可以帮助检测是否过度拟合。
体会: - 进行竞标数据分析需要耐心和细心,因为数据集可能很大和复杂。
- 需要学习和理解各种机器学习算法的原理和应用,以及如何调整算法的参数来得到最佳模型。
- 要善于使用Sklearn的文档和示例来帮助解决问题和提高技能水平。
- 通过竞标数据分析,我们可以得出一些有用的结论和洞见,这些结论和洞见可以帮助我们做出更明智的商业决策。
代码:
import pandas as pd
bidding = pd.read_csv('./data/shill_bidding.csv', encoding='gbk', header=None)
# 将类别一列转换为数值类型
# bidding['类别'] = pd.Categorical(bidding['类别']).codes
# 拆分数据和标签
bidding_data = bidding.iloc[1:, 2: -1]
bidding_target = bidding.iloc[1:, -1]
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
bidding_data_train, bidding_data_test, \
bidding_target_train, bidding_target_test = \
train_test_split(bidding_data, bidding_target, test_size=0.2, random_state=123)
# PCA降维
from sklearn.decomposition import PCA
pca = PCA(n_components=8).fit(bidding_data_train) #生成规则
bidding_trainPca = pca.transform(bidding_data_train) #应用规则
bidding_testPca = pca.transform(bidding_data_test)
print(bidding_trainPca.shape) # 降维后的训练集数据大小
print(bidding_testPca.shape) # 降维后的测试集数据大小
# kmeans聚类
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=2, random_state=66).fit(bidding_data_train)
# ARI评价法
from sklearn.metrics import adjusted_rand_score
ari_score = adjusted_rand_score(bidding_target_train, kmeans.labels_)
print('竞标行为数据集的ARI:' ,(ari_score))
# V-measure评分
from sklearn.metrics import completeness_score
V_measure_score = completeness_score(bidding_target_train, kmeans.labels_)
print('竞标行为数据集的V-measure:' ,(V_measure_score))
# fmi评价法
from sklearn.metrics import fowlkes_mallows_score
fmi_score = fowlkes_mallows_score(bidding_target_train, kmeans.labels_)
print('竞标行为数据集的FMI:',(fmi_score))
# 确定聚类数目为1~3时的最优聚类数
for i in range(1, 4):
kmeans = KMeans(n_clusters=i, random_state=66).fit(bidding_data_train)
score = fowlkes_mallows_score(bidding_target_train, kmeans.labels_)
print('竞标行为数据聚%d类 FMI评价分值为:' ,(i, score))
print("接近1为最佳,所以聚类为1的时候效果最好")
# 1标准化数据集
from sklearn.preprocessing import StandardScaler
stdScale = StandardScaler().fit(bidding_data_train)
bidding_trainScaler = stdScale.transform(bidding_data_train)
bidding_testScaler = stdScale.transform(bidding_data_test)
# 2构建SVM模型,并预测测试集结果
from sklearn.svm import SVC
svm = SVC().fit(bidding_trainScaler, bidding_target_train)
bidding_target_pred = svm.predict(bidding_testScaler)
print('预测前10个结果为:', bidding_target_pred[: 10])
print('\n')
# 3打印出分类报告,评价分类模型性能
from sklearn.metrics import classification_report
print('使用SVM预测customer数据的分类报告为:', '\n',
classification_report(bidding_target_test, bidding_target_pred))
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsRegressor
from sklearn.decomposition import PCA
# PCA降维
pca = PCA(n_components=0.999).fit(bidding_data_train)
bidding_trainPca = pca.transform(bidding_data_train)
bidding_testPca = pca.transform(bidding_data_test)
# 线性回归模型
bidding_linear = LinearRegression().fit(bidding_trainPca, bidding_target_train)
y_pred = bidding_linear.predict(bidding_testPca)
# 计算平均绝对误差、均方误差、R方值
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
print('线性回归模型预测的结果为:', y_pred)
print('线性回归模型评价结果')
print('数据线性回归模型的平均绝对误差为:',
mean_absolute_error(bidding_target_test, y_pred))
print('数据线性回归模型的均方误差为:',
mean_squared_error(bidding_target_test, y_pred))
print('数据线性回归模型的R方值为:',
r2_score(bidding_target_test, y_pred))
print("----------------------------------分隔线--------------------------------------")
# 逻辑回归模型
bidding_logistic = LogisticRegression().fit(bidding_trainPca,
bidding_target_train)
y_pred2 = bidding_logistic.predict(bidding_testPca)
print('逻辑回归模型预测前10个结果为:', y_pred2[: 10])
print('逻辑回归模型评价结果')
print('数据逻辑回归模型的平均绝对误差为:',
mean_absolute_error(bidding_target_test, y_pred2))
print('数据逻辑回归模型的均方误差为:',
mean_squared_error(bidding_target_test, y_pred2))
print('数据逻辑回归模型的R方值为(1为最佳):',
r2_score(bidding_target_test, y_pred2))
import pandas as pd
data = pd.read_csv('./data/shill_bidding.csv', encoding='gbk')
#将最后一列的0和1作为标签y,其余特征列组成的矩阵作为输入x:
x = data.iloc[:, :-1].values
y = data.iloc[:, -1].values
from sklearn.preprocessing import StandardScaler
# 对特征值做标准化处理,可以直接使用sklearn.preprocessing库中的StandardScaler类:
sc = StandardScaler()
x_scaled = sc.fit_transform(x)
# 将数据集划分为训练集和测试集,以便于评估模型的性能。这里我使用sklearn.model_selection库中的train_test_split函数:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(
x_scaled, y, test_size=0.2, random_state=0)
# 构建最近邻回归模型了。这里我使用sklearn.neighbors库中的KNeighborsRegressor类:
from sklearn.neighbors import KNeighborsRegressor
# 构建最近邻回归模型了。这里我使用sklearn.neighbors库中的KNeighborsRegressor类:
knnr = KNeighborsRegressor(n_neighbors=2, metric='euclidean')
knnr.fit(x_train, y_train)
y_pred = knnr.predict(x_test) #预测的结果
print(y_pred[:20])
from sklearn.metrics import accuracy_score
# accuracy = accuracy_score(y_test, y_pred.round()) #不适合用accuracy_score方法评估最近邻模型
# print(f"精度: {accuracy}")
print('最近邻回归模型评价结果')
print('最近邻回归模型的平均绝对误差为:',
mean_absolute_error(y_test, y_pred))
print('最近邻回归模型的均方误差为:',
mean_squared_error(y_test, y_pred))
print('最近邻回归模型的R方值为(1为最佳):',
r2_score(y_test, y_pred))
 文章来源地址https://www.toymoban.com/news/detail-478884.html
文章来源地址https://www.toymoban.com/news/detail-478884.html
到了这里,关于python数据分析与应用:第六章课后实训--应用sklearn分析竞标数据(全)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!