如果觉得本篇文章对你有帮助的话请点赞关注加收藏吧!
(默认你有colab,如果没有去看一下如何使用colab,很简单)
首先你需要在colab上挂载谷歌硬盘为了保存你上传好的代码,如果不挂载谷歌硬盘的话就会导致下次你需要重新上传你的文件夹 点击第三个图标就是挂载你的谷歌硬盘。
点击第三个图标就是挂载你的谷歌硬盘。
然后需要用到以下命令进入到你的谷歌硬盘下(因为我们要把代码放到谷歌硬盘里,以后任何通过命令上传到谷歌硬盘的文件也是同样的操作)
%cd /content/drive/MyDrive
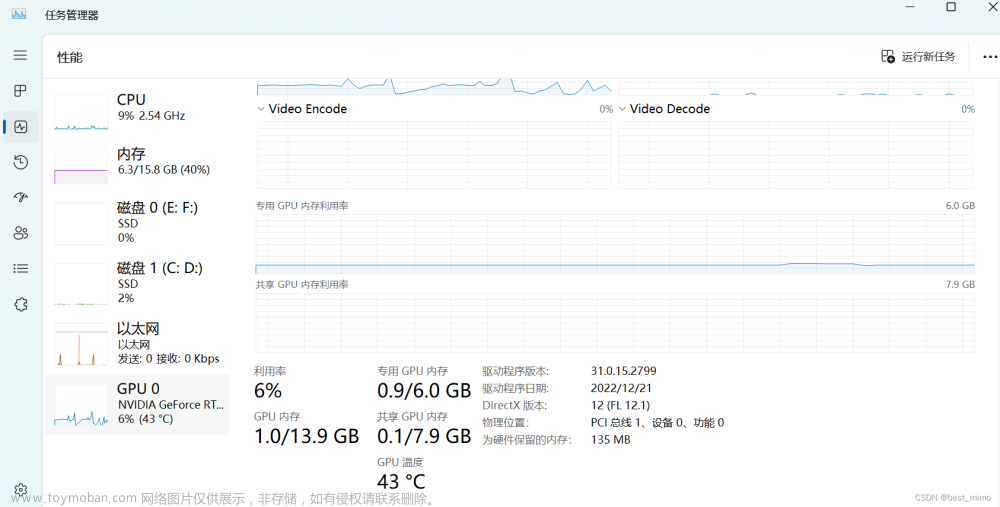
补充一点在此之前要查看colab的gpu显存是否足够,chatglm需要6-7g的显存,查看gpu显存命令
!nvidia-smi
 memory-usage为它的显存大小
memory-usage为它的显存大小
第二我们需要在github上下载chatglm的项目,需要用到以下命令
!git clone https://github.com/THUDM/ChatGLM-6B.git
下载完项目之后我们需要在项目的主文件夹下新建一个model文件来存放chatglm的模型文件,只需要右击主项目文件夹新建即可,如图
然后新建完model文件夹之后,我们需要进入model文件夹下去下载我们的模型文件,进入model文件夹的命令如下
%cd /content/drive/MyDrive/ChatGLM-6B/model
进入文件夹下之后按照如下命令将文件下载到model文件夹下
!wget https://huggingface.co/THUDM/chatglm-6b-int4/resolve/main/LICENSE
!wget https://huggingface.co/THUDM/chatglm-6b-int4/resolve/main/MODEL_LICENSE
!wget https://huggingface.co/THUDM/chatglm-6b-int4/resolve/main/README.md
!wget https://huggingface.co/THUDM/chatglm-6b-int4/resolve/main/config.json
!wget https://huggingface.co/THUDM/chatglm-6b-int4/resolve/main/configuration_chatglm.py
!wget https://huggingface.co/THUDM/chatglm-6b-int4/resolve/main/modeling_chatglm.py
!wget https://huggingface.co/THUDM/chatglm-6b-int4/resolve/main/quantization.py
!wget https://huggingface.co/THUDM/chatglm-6b-int4/resolve/main/ice_text.model
!wget https://huggingface.co/THUDM/chatglm-6b-int4/resolve/main/quantization_kernels.c
!wget https://huggingface.co/THUDM/chatglm-6b-int4/resolve/main/quantization_kernels_parallel.c
!wget https://huggingface.co/THUDM/chatglm-6b-int4/resolve/main/tokenization_chatglm.py
!wget https://huggingface.co/THUDM/chatglm-6b-int4/resolve/main/tokenizer_config.json
!wget https://huggingface.co/THUDM/chatglm-6b-int4/resolve/main/pytorch_model.bin
!wget https://huggingface.co/THUDM/chatglm-6b-int4/resolve/main/.gitattributes
然后我们需要进入到chatGLM-6B文件夹下去配置我们的运行环境
%cd /content/drive/MyDrive/ChatGLM-6B
!pip install protobuf==3.20.0 transformers==4.27.1 icetk cpm_kernels
!pip install -r requirements.txt
以上操作成功之后就可以测试一下我们的部署是否成功了(运行过程会有点慢,请慢慢等待,大概20多分钟)
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("model", trust_remote_code=True)
model = AutoModel.from_pretrained("model", trust_remote_code=True).float()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)

如果有问题的话请评论区留言,如果对你有帮助的话就请点赞关注加收藏哦!文章来源:https://www.toymoban.com/news/detail-479106.html
参考文章
清华 ChatGLM-6B 中文对话模型部署简易教程https://blog.csdn.net/qq_43475750/article/details/129665389?spm=1001.2014.3001.5506文章来源地址https://www.toymoban.com/news/detail-479106.html
到了这里,关于小白也会的在colab上部署Chatglm的详细教程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!