一、持久化存储理论
官方中文参考文档:
1、为什么要做数据持久化存储?
在k8s中部署的应用都是以pod容器的形式运行的,假如我们部署MySQL、Redis等数据库,需要对这些数据库产生的数据做备份。因为Pod是有生命周期的,如果pod不挂载数据卷,那pod被删除或重启后这些数据会随之消失,如果想要长久的保留这些数据就要用到pod数据持久化存储。
2、常见持久化存储方案
- emptyDir:是一种临时性的卷,它的生命周期与 Pod 相同。emptyDir 卷是在 Pod 被调度到节点上时创建的,并且在 Pod 被删除时一并删除。emptyDir 卷通常用于在容器之间共享文件或者缓存数据。
- HostPath:是一种本地存储卷,可以将宿主机目录映射到容器中,删除Pod后宿主机卷不会跟随删除,但是调用到不通节点,卷内容会不一致(MySQL数据在Node1节点存储,删除MySQL Pod后调度到Node2上了,导致数据不一致)。
- NFS:是一种共享卷,需要依赖于NFS服务端,所有Pod共享NFS卷内容,不需要考虑Pod调度在不同节点导致数据不一致问题,但是NFS基于网络传输,会占用带宽。
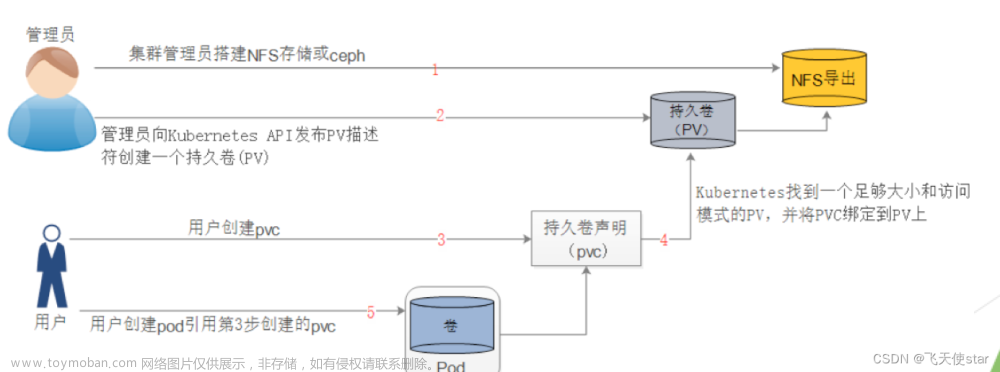
- PVC:用来实现持久化存储,可以将存储资源独立出来,方便管理和共享。
二、案例:持久化存储方案
1、emptydir临时存储卷
临时卷,当Pod被删除时,卷也会删除,用于存储一些不重要的数据。
创建Pod资源,使用emptydir卷方式挂载 ,YAML如下:
cat emptydir-pod.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: empty-pod
labels:
type: empty-pod
spec:
containers:
- name: empty-pod
image: nginx
imagePullPolicy: IfNotPresent
volumeMounts:
- name: volume-empty # 挂载路径名称,必须与下面卷名称一致
mountPath: /usr/share/nginx/html # 卷挂载目录
volumes:
- emptyDir: {} # emptyDir类型,{}表示一个空的配置
name: volume-empty # 卷名称
执行YAML文件:
kubectl apply -f emptydir-pod.yaml
如何查看本地挂载卷路径位置呢?
第一步:确认Pod当前所在节点,可以使用以下命令确认:
kubectl get pods empty-pod -o wide
第二步:确认Pod的uid值,可以使用以下名称确认:
kubectl get pods empty-pod -o yaml|grep uid
uid: 9f76e568-05a9-41c3-9fb2-c43505214b99
第三步:在Pod所在节点中的/var/lib/kubelet/pods/uid 目录下:
cd /var/lib/kubelet/pods/9f76e568-05a9-41c3-9fb2-c43505214b99
cd volumes/kubernetes.io~empty-dir/volume-empty # 此目录对应Pod中/usr/share/nginx/html 目录
确认本地卷对应目录后,我们进入路径,创建index.html文件:
cd /var/lib/kubelet/pods/9f76e568-05a9-41c3-9fb2-c43505214b99/volumes/kubernetes.io~empty-dir/volume-empty
echo "qinzt666" > index.html
访问Pod网站内容:
kubectl get pods empty-pod -o wide
curl 10.244.235.233

我们删除Pod后宿主机上此目录也会跟随删除
kubectl delete pods empty-pod

2、hostPath本地存储卷
本地存储卷,指定宿主机目录,与容器目录做映射,删除Pod,宿主机目录不会跟随删除,hostPath可以支持很多挂载类型,如挂载目录,挂载文件等,如下图,此图来自官方:

创建Pod资源,使用hostPath卷方式挂载 ,YAML如下:
cat hostpath-pod.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: hostpath-pod
labels:
type: hostpath-pod
spec:
containers:
- name: hostpath-pod
image: nginx
imagePullPolicy: IfNotPresent
volumeMounts:
- name: volume-hostpath # 挂载路径名称,必须与下面卷名称一致
mountPath: /usr/share/nginx/html # 容器挂载目录
volumes:
- hostPath:
path: /data1 # 宿主机挂载目录
type: DirectoryOrCreate # 卷类型,DirectoryOrCreate表示目录,宿主机不存在则创建空目录
name: volume-hostpath # 卷名称
执行YAML文件:
kubectl apply -f hostpath-pod.yaml
在Pod调度节点的宿主机挂载卷位置创建 index.html 文件
kubectl get pods hostpath-pod -o wide

echo "hello world qinzt 666 ...." >/data1/index.html
访问Pod网站内容,Pod 的IP地址如上图也可以查看到:
curl 10.244.235.198

删除此Pod,节点上的数据依旧存在。
kubectl delete pod hostpath-pod
ls /data1/
index.html
3、NFS网络共享存储卷
NFS共享存储卷,需要先搭建NFS服务端,Pod共享NFS服务端数据,解决了Pod调度在不通Node节点,导致数据不一致问题,但是NFS需要依赖网络带宽。
搭建NFS服务端:所有Node节点上都需要安装 nfs-utils
yum install nfs-utils -y
mkdir /data/volumes -p
vim /etc/exports
/data/volumes *(rw,no_root_squash)
加载配置生效 && 启动NFS服务
exportfs -arv
systemctl enable nfs --now
在其他Node节点上面测试 NFS 是否可以正常挂载:
yum install nfs-utils -y
mkdir /test
mount 16.32.15.200:/data/volumes /test
df -hT /test/

如上图测试无问题,卸载挂载:
umount /test
OK,至此NFS服务端已经搭建完成,测试没有问题了。
编写 YAML 使用 NFS 类型存储卷:
cat nfs-deployment.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-test
namespace: default
labels:
type: nfs
spec:
replicas: 3
selector:
matchLabels:
type: nfs
template:
metadata:
labels:
type: nfs
spec:
volumes:
- name: nfs-test-volume # 卷名称
nfs:
server: 16.32.15.200 # NFS服务端IP地址
path: /data/volumes # NFS服务端共享目录
containers:
- name: nfs-test
image: nginx
imagePullPolicy: IfNotPresent
volumeMounts:
- name: nfs-test-volume # 挂载卷名称
mountPath: /usr/share/nginx/html # 容器内挂载目录
执行YAML 资源清单文件:
kubectl apply -f nfs-deployment.yaml
在 宿主机NFS共享卷创建 index.html 文件
echo "qinzt coolest 666." > /data/volumes/index.html
访问 Pod网站,由于没有创建Service资源,我们使用Pod IP地址进行访问。
kubectl get pods -o wide
 文章来源:https://www.toymoban.com/news/detail-479169.html
文章来源:https://www.toymoban.com/news/detail-479169.html
上面curl 两个节点上的Pod都可以访问,说明挂载nfs存储卷成功了,nfs支持多个客户端挂载,可以创建多个pod,挂载同一个nfs服务器共享出来的目录;但是nfs如果宕机了,数据也就丢失了,所以需要使用分布式存储,常见的分布式存储有glusterfs和cephfs。文章来源地址https://www.toymoban.com/news/detail-479169.html
到了这里,关于【Kubernetes存储篇】常见存储方案及场景分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!