矩阵乘法的MPI并行实验报告
一、实验要求:
(1) 分别用 1,2,4,8 个进程完成矩阵乘法(同一个程序):A * B = C,其中 A,B,C 均为 2048*2048 双精度点方阵,0号进程负责初始化矩阵 A,B 并将结果存入 0 号进程。
(2) 绘制加速比曲线;
二、实验环境:
- 操作系统:Windows11
- 编程语言:C++(使用MPI接口)
- 编译器:VC++
- 核心库:MPI(MSMPI)
- 编程工具:Visual Studio 2022
- CPU:AMD Ryzen 7 6800H with Radeon Graphics 3.20 GHz
- 内存:16GB
三、实验内容:
1. 实现思路
将可用于计算的进程数分解为a*b,然后将全体行划分为a个部分,全体列划分为b个部分,从而将整个矩阵划分为相同的若干个块。每个子进程负责计算最终结果的一块,只需要接收A对应范围的行和B对应范围的列,而不需要把整个矩阵传过去。主进程(0号进程)负责分发和汇总结果。
注意:
(1) 为了保证平均划分,矩阵需要扩展,即扩展至负责计算的进程数的倍数,扩展部分数据置为0,以保证结果准确性。
(2) 通信接口使用Send/Recv,所以进程编号要管理好。另外,主进程只负责初始化矩阵及分发和汇总结果。
2. 实验结果
(1) 设置为单进程,即串行文章来源:https://www.toymoban.com/news/detail-479397.html
- 单进程命令行参数设置(如图1)

图 1 单进程时命令行参数设置 - 单进程运行结果,约97.20s(如图2)
 图 2 单进程时运行的时间花销
图 2 单进程时运行的时间花销
(2) 设置为2进程 - 2进程命令行参数设置(如图3)
 图 3 程序2进程运行时命令行参数设置
图 3 程序2进程运行时命令行参数设置
- 2进程运行结果,约75.43s(如图4)
 图 4 程序2进程时运行的时间花销
图 4 程序2进程时运行的时间花销
(3) 设置为4进程 - 4进程命令行参数设置(如图5)
 图 5 程序4进程运行时命令行参数设置
图 5 程序4进程运行时命令行参数设置
- 4进程运行结果,约17.17s(如图6)
 图 6 程序4进程时运行的时间花销
图 6 程序4进程时运行的时间花销
(4) 设置为8进程 - 8进程命令行参数设置(如图7)
 图 7 程序8进程运行时命令行参数设置
图 7 程序8进程运行时命令行参数设置
- 8进程运行结果,约9.05s(如图8)
 图 8 程序4进程时运行的时间花销
图 8 程序4进程时运行的时间花销
由上述运行结果可得表格1
表格 1 程序运行结果分析表 由表格1可知,随着进程数的增加,程序运行时间也随之减少,加速比随之增加。但是,可以注意到,单进程和2进程的时间花销相差并不大,2进程时的加速比仅为1.29,其原因是程序在多进程运行时,由于设计思路是主进程(0号进程)并不参与计算,只负责初始化矩阵和分发汇总结果,故2进程时程序优化并不明显。当增加到4进程及8进程时,程序运行时间大大减少。其加速比曲线如图9。
由表格1可知,随着进程数的增加,程序运行时间也随之减少,加速比随之增加。但是,可以注意到,单进程和2进程的时间花销相差并不大,2进程时的加速比仅为1.29,其原因是程序在多进程运行时,由于设计思路是主进程(0号进程)并不参与计算,只负责初始化矩阵和分发汇总结果,故2进程时程序优化并不明显。当增加到4进程及8进程时,程序运行时间大大减少。其加速比曲线如图9。
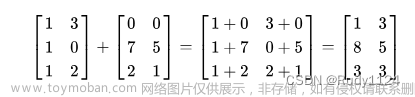
由于实验要求的矩阵为2048*2048的双精度浮点方阵,故在代码完成后,先将矩阵维度设置为7,以检验程序结果是否准确,同时对于生成的随机数不设置种子,以保证每次程序运行的数据一致,从而确保实验数据准确,检验结果如图10所示; 图 10 检验矩阵数据
图 10 检验矩阵数据
四、实验总结:
经过此次实验,文章来源地址https://www.toymoban.com/news/detail-479397.html
- 熟悉掌握了MPI几个基本函数,知晓Send/Recv通信接口的使用;
- 进一步了解MPI通信的相关原理;
- 掌握基本的MPI编程能力;
五、 附录(代码):
#include <iostream>
#include <cstdlib>
#include <ctime>
#include <cmath>
#include <string>
#include "mpi.h"
#define NUM 2048 //矩阵大小
using namespace std;
//打印数组(测试使用)
void printfArray(double* A, int length) {
for (int i = 0; i < length; i++) {
for (int j = 0; j < length; j++) {
cout << A[i * length + j] << " " ;
}
cout << endl;
}
}
//扩展矩阵并且初始化,多余部分填充0
void matGene(double* A, int size, int actual_size) {
// actual size: 使用的矩阵极可能大于原始大小
for (int i = 0; i < actual_size; i++) {
for (int j = 0; j < actual_size; j++) {
if (i < size && j < size)
//初始化矩阵,随机生成双精度浮点数[-1,1]
A[i * actual_size + j] = -1.0 + 1.0 * rand() / RAND_MAX * 2; //A[i][j]
else A[i * actual_size + j] = 0; //扩展部分填充0
}
}
}
//计算矩阵乘法(进程数为1时)
void matMulti(double* A, double* B, double* C, int m, int n, int p) {
for (int i = 0; i < m; i++) {
for (int j = 0; j < p; j++) {
C[i * p + j] = 0;
for (int k = 0; k < n; k++)
C[i * p + j] += A[i * n + k] * B[k * p + j];
}
}
}
//返回不大于根号(n)的最大因子
int factor(int n) {
double sqr_root = sqrt(n);
for (int i = sqr_root; i >= 1; i--) {
if (n % i == 0) return i;
}
}
int main(int argc, char* argv[]) {
int n = NUM; // 数组大小
double beginTime, endTime; //用于记录时间
//srand((unsigned int)time(NULL)); //如果多次测试,可以注释这一句
// 初始化MPI
int my_rank = 0, comm_sz = 0, namelen = 0;
char processor_name[MPI_MAX_PROCESSOR_NAME];
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); //获取进程号
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz); //获取进程数
MPI_Get_processor_name(processor_name, &namelen); //获得处理器名
MPI_Status status; //状态
if (comm_sz == 1) { // no parallel
// Prepare data
double* A = new double[n * n + 2];
double* B = new double[n * n + 2];
double* C = new double[n * n + 2];
int saveN = n;
matGene(A, saveN, n);
matGene(B, saveN, n);
// 计算时间
beginTime = MPI_Wtime(); //开始时间
matMulti(A, B, C, n, n, n);
endTime = MPI_Wtime(); //结束时间
cout << processor_name << ":" << "单进程时间开销:" << endTime - beginTime << "s" << endl;
//删除矩阵
delete[] A;
delete[] B;
delete[] C;
}
else { // 进程数大于1时,启用并行
int saveN = n;
// 主要过程负责收集结果,矩阵必须与散度相等:实际n大于输入
//计算矩阵大小(需扩展至负责计算的进程数的倍数)即comm_sz-1的倍数
if (n % (comm_sz - 1) != 0) {
n -= n % (comm_sz - 1);
n += (comm_sz - 1);
}
/*
将可用于计算的进程数(comm_sz-1)分解为a*b
然后将全体行划分为a个部分,全体列划分为b个部分,
从而将整个矩阵划分为size相同的(comm_sz-1)个块。
每个子进程负责计算最终结果的一块,只需要接收A对应范围的行和B对应范围的列,
而不需要把整个矩阵传过去。
*/
int a = (comm_sz - 1) / factor(comm_sz - 1);
int b = factor(comm_sz - 1);
int each_row = n / a;
int each_column = n / b;
//0号进程负责初始化矩阵,分发和汇总结果
if (my_rank == 0) {
double* A = new double[n * n + 2];
double* B = new double[n * n + 2];
double* C = new double[n * n + 2];
// Prepare data
//cout << "n = " << n << endl;
//将矩阵的维度扩展到comm_sz-1的倍数,多余的部分用0填充,保证正确性。
matGene(A, saveN, n);
matGene(B, saveN, n);
//计算开始时间
beginTime = MPI_Wtime();
//Send:发送数据,矩阵A的行和矩阵B的列至各进程
//发送 A[beginRow:endRow, :], B[:, beginColumn:endColumn]
for (int i = 1; i < comm_sz; i++) { //发送数据到各进程(0号进程除外)
int beginRow = ((i - 1) / b) * each_row;
int beginColumn = ((i - 1) % b) * each_column;
// A: beginRow ~ endRow
MPI_Send(&A[beginRow * n + 0], each_row * n, MPI_DOUBLE, i, i, MPI_COMM_WORLD);
// B: n times, once a row
for (int j = 0; j < n; j++) {
MPI_Send(&B[j * n + beginColumn], each_column, MPI_DOUBLE, i, i * n + j + comm_sz + 2, MPI_COMM_WORLD);
}
}
//接受结果 Recv: C[beginRow:endRow, beginColumn:endColumn]
for (int i = 1; i < comm_sz; i++) {
int beginRow = ((i - 1) / b) * each_row;
int endRow = beginRow + each_row;
int beginColumn = ((i - 1) % b) * each_column;
for (int j = beginRow; j < endRow; j++) {
MPI_Recv(&C[j * n + beginColumn], each_column, MPI_DOUBLE, i, each_row * i + (j - beginRow), MPI_COMM_WORLD, &status);
}
}
endTime = MPI_Wtime(); //结束时间
//打印时间花销
cout << processor_name << ":" << comm_sz << "个进程时间开销:" << endTime - beginTime << "s" << endl;
//删除矩阵
delete[] A;
delete[] B;
delete[] C;
}
else {
double* partA = new double[each_row * n + 2]; // A[beginRow:endRow, :]
double* partB = new double[n * each_column + 2]; // B[:, beginColumn:endColumn]
double* partC = new double[each_row * each_column + 2]; // C[beginRow:endRow, beginColumn:endColumn]
//各进程接受数据 Recv: partA, partB
MPI_Recv(&partA[0 * n + 0], each_row * n, MPI_DOUBLE, 0, my_rank, MPI_COMM_WORLD, &status);
for (int j = 0; j < n; j++) {
MPI_Recv(&partB[j * each_column + 0], each_column, MPI_DOUBLE, 0, my_rank * n + j + comm_sz + 2, MPI_COMM_WORLD, &status);
}
//计算
matMulti(partA, partB, partC, each_row, n, each_column);
//发送计算之后的结果 Send: partC
for (int j = 0; j < each_row; j++) {
MPI_Send(&partC[j * each_column + 0], each_column, MPI_DOUBLE, 0, each_row * my_rank + j, MPI_COMM_WORLD);
}
//删除数组
delete[] partA;
delete[] partB;
delete[] partC;
}
}
//终止MPI
MPI_Finalize();
return 0;
}
到了这里,关于矩阵乘法的MPI并行实验报告的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!