一、前言
实时物体检测已经成为众多邻域应用的关键组成部分,这些领域包括:自动驾驶车辆、机器人、视频监控和增强现实等。在众多物体检测算法中,近年来,YOLO(You Only Look Once)框架以其卓越的速度和准确性脱颖而出,实际证明能够快速可靠地识别图像中的物体。自诞生以来,YOLO经过了多次迭代,每个版本都在前一版本的基础上进行改进,不断在提高性能,截至本文发稿,YOLO框架从V1已经更新到了v8。作为机器视觉技术应用的我们,有必要对YOLO的技术演进进行系统了解,熟悉YOLO每个版本之间的关键创新、差异和改进(如网络设计、损失函数修改、锚框适应和输入分辨率缩放等)。从而更好地把握YOLO的技术发展主脉搏,更好地选择应用相关的视觉识别技术。YOLO技术概要学习笔记共三篇,主要遵照国外文章《A COMPREHENSIVE REVIEW OF YOLO: FROM YOLOV1 AND
BEYOND》的主线进行学习,通过综合其它文献对YOLO技术进行细品,形成理性认识。
二、YOLOv2
YOLOv2 是由 Joseph Redmon 和 Ali Farhadi 在2017年的CVPR会议上发表的。它在原有的YOLO基础上进行了多项改进,使其更好,保持了相同的速度,同时变得更强——能够检测9000个类别! 改进包括以下几点:
2.1 v2特点
(1)卷积层归一化
对所有卷积层进行批量归一化,改善了收敛性,并作为正则化器减少了过拟合。
(2)高分辨率分类器
使用ImageNet在224×224上对模型进行了预训练,同时,在ImageNet上使用448×448的分辨率对模型进行了10个时期的微调,提高了网络在更高分辨率输入上的性能。
(3)完全卷积
移除了密集层(全连接层),采用了完全卷积的架构。
(4)使用锚框来预测边界框
使用一组先验框或锚框,这些是具有预定义形状的框,用于匹配对象的原型形状,如图所示。每个网格单元定义了多个锚框,系统预测每个锚框的坐标和类别。网络输出的大小与每个网格单元的锚框数量成比例。
(5)维度聚类
选择好的先验框有助于网络学习预测更准确的边界框。v2对训练边界框运行了k-means聚类,以找到好的先验框。他们选择了五个先验框,提供了在召回率和模型复杂性之间的良好平衡。
(6)直接位置预测
与其他预测偏移量的方法不同[45],YOLOv2遵循相同的哲学,相对于网格单元预测位置坐标。网络为每个单元格预测五个边界框,每个边界框有五个值tx、ty、tw、th和to,其中to等价于YOLOv1中的Pc,最终边界框坐标如下图(通过经过sigmoid函数的预测tx、ty值并通过网格单元cx、cy的位置进行偏移,可以获得盒子的中心坐标。最终框的宽度和高度分别使用先前的宽度pw和高度ph,分别缩放etw 和eth,其中tw 和th由YOLOv2预测)所示获得 。
(7) 更细粒度的特征
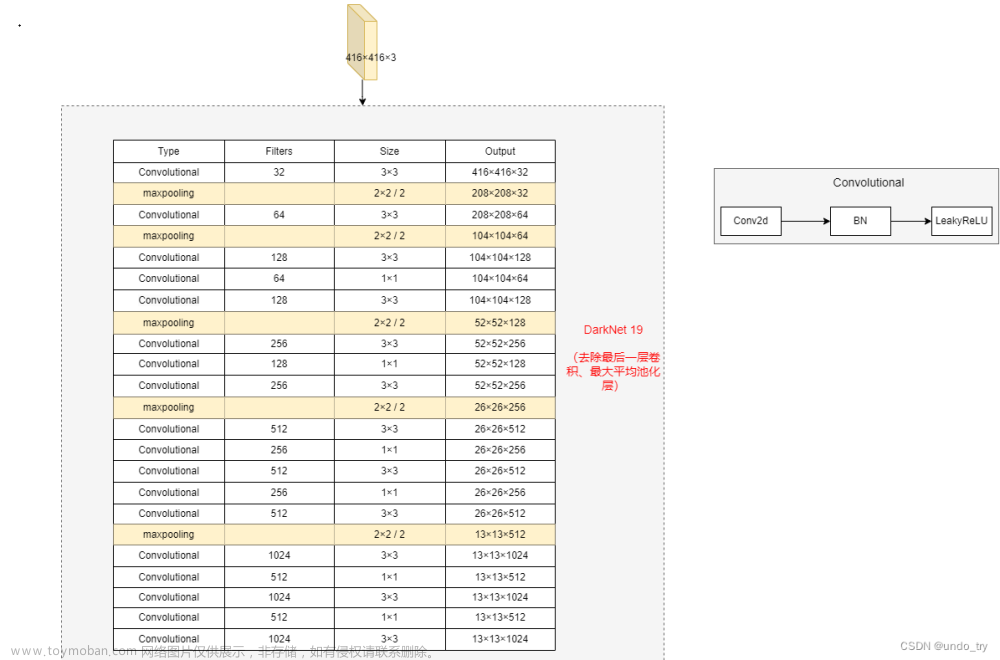
与YOLOv1相比,YOLOv2去掉了一个池化层,以获得416×416输入图像的13×13的输出特征映射或网格。YOLOv2还使用了一个直通层,它将26×26×512特征映射重新组织成不同通道中的相邻特征,而不是通过空间子采样丢失它们。这生成了13×13×2048特征映射,与低分辨率的13×13×1024映射在通道维度上连接,以获得13×13×3072特征映射。有关架构详细信息,请参见下表:
(8) 多尺度训练
由于YOLOv2不使用全连接层,输入可以是不同的大小。为了使YOLOv2对不同的输入大小具有鲁棒性,作者随机训练模型,每10个批次改变一次输入大小——从320×320到608×608不等。YOLOv2在PASCAL VOC2007数据集上取得了AP为78.6%,而YOLOv1仅获得了63.4%
2.2 YOLOv2 框架
YOLOv2使用的骨干架构称为Darknet-19,包含19个卷积层和五个最大池化层。与YOLOv1的架构类似,它受到Network in Network 的启发,使用1×1卷积在3×3之间减少参数数量。此外,正如上面提到的,他们使用批量归一化来规范化和帮助收敛。
上表显示了整个Darknet-19骨干架构和目标检测头。当使用PASCAL VOC数据集时,YOLOv2预测五个边界框,每个边界框有五个值和20个类别。目标分类头将最后四个卷积层替换为具有1000个过滤器的单个卷积层,然后是全局平均池化层和Softmax。
3 YOLOv3
YOLOv3 是由Joseph Redmon和Ali Farhadi于2018年在ArXiv上发布的。它包括了重大的变化和更大的架构,以保持与最先进的技术水平相当的同时保持实时性能。接下来,我们将描述与YOLOv2相比发生的变化。
3.1 v3特点
(1)边界框预测
与YOLOv2相似,网络为每个边界框预测四个坐标tx、ty、tw和th;然而,这一次,YOLOv3使用逻辑回归为每个边界框预测一个物体得分。该得分对于与地面实况具有最高重叠的锚定框为1,对于其余锚定框为0。与Faster R-CNN不同,YOLOv3仅将一个锚定框分配给每个地面实况对象。此外,如果没有为对象分配锚定框,则仅产生分类损失而不是定位损失或置信度损失。
(2)类别预测
与使用softmax进行分类不同,他们使用二元交叉熵来训练独立的逻辑分类器,并将问题作为多标签分类。这种改变允许将多个标签分配给同一个框,在一些具有重叠标签的复杂数据集中可能会出现。例如,同一个对象可以是一个人和一个男人。
(3)新的骨干网络
YOLOv3具有由53个卷积层和残差连接组成的更大的特征提取器。骨干网络Darknet-53,是一个53层的卷积神经网络,具有残差结构,由卷积层、批量归一化层和Leaky ReLU激活函数组成。其结构类似于ResNet,但使用了更小的卷积核和更少的参数,同时具有更高的准确率和更快的速度。
(4)空间金字塔池化(SPP)
v3还向骨干网络添加了一个修改后的SPP块,它将多个最大池化输出连接起来,而不进行子采样(步幅=1),每个输出具有不同的内核大小k×k,其中k=1、5、9、13,从而允许更大的感受野。这个版本被称为YOLOv3-spp,是表现最好的版本,将AP提高了2.7%。
ps:什么是SPP:空间金字塔池化(SPP)是一种用于图像分类和对象检测的技术,可以将任意大小的输入图像转换为固定大小的特征向量。SPP对输入图像进行多尺度划分,并在每个划分区域上进行池化操作,最后将所有池化结果连接起来形成一个固定长度的特征向量。
以下是使用PyTorch实现SPP的示例代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SPP(nn.Module):
def __init__(self, levels):
super(SPP, self).__init__()
self.levels = levels
def forward(self, x):
# 获取输入特征张量的形状
shape = x.size()
# 对输入特征张量进行多尺度划分
for i in range(self.levels):
# 计算每个划分区域的大小
pool_size = (shape[2] // (2 ** i), shape[3] // (2 ** i))
# 在每个划分区域上进行最大池化
pooled = F.max_pool2d(x, kernel_size=pool_size, stride=pool_size)
# 将池化结果展平
flattened = pooled.view(shape[0], -1)
# 将所有池化结果连接起来
if i == 0:
spp = flattened
else:
spp = torch.cat([spp, flattened], dim=1)
# 返回SPP层的输出特征张量
return spp
(5)多尺度预测
与特征金字塔网络类似,YOLOv3在三个不同的尺度上预测三个框。
(6)边界框先验
与YOLOv2类似,v3还使用k-means确定锚定框的边界框先验。不同之处在于,在YOLOv2中,他们每个单元格使用了总共五个先验框,在YOLOv3中,他们为三个不同的尺度使用了三个先验框。
3.2 YOLOv3 框架
YOLOv3中提出的架构骨干称为Darknet-53,它用分步卷积替换了所有的最大池化层,并添加了残差连接。总共包含53个卷积层。
下图显示了架构细节。Darknet-53骨干获得的Top-1和Top-5准确度与ResNet-152相当,但速度几乎快2倍。
上图中:YOLOv3 Darknet-53骨干网络。YOLOv3的架构由53个卷积层组成,每个卷积层都有批量归一化和Leaky ReLU激活。此外,残差连接将1×1卷积的输入与整个网络中3×3卷积的输出连接起来。这里显示的架构仅包括骨干网络,不包括由多尺度预测组成的检测头。
3.3 YOLOv3多尺度预测
除了更大的架构之外,YOLOv3的一个重要特征是多尺度预测,即在多个网格大小上进行预测。这有助于获得更精细的框,并显着改善小物体的预测,这是以前版本的YOLO的主要弱点之一。
如下图所示的多尺度检测架构的工作方式如下:标记为y1的第一个输出等效于YOLOv2的输出,其中13×13网格定义输出。第二个输出y2由Darknet-53的(Res×4)输出和(Res×8)输出之后的输出连接而成。特征图具有不同的大小,即13×13和26×26,因此在连接之前进行上采样操作。最后,使用上采样操作,第三个输出y3将26×26特征图与52×52特征图连接起来。
对于包含80个类别的COCO数据集,每个尺度都提供一个形状为N×N×[3×(4+1+80)]的输出张量,其中N×N是特征图(或网格单元)的大小,3表示每个单元格的框数,4+1包括四个坐标和物体性得分。
上图中:Darknet-53骨干网络的输出分为三个不同的输出,标记为y1、y2和y3,每个输出的分辨率都有所提高。最终预测的框使用非最大值抑制进行过滤。CBL(卷积-批量归一化-整流ReLU)块包括一个卷积层,具有批量归一化和泄漏ReLU。Res块包括一个CBL,后跟两个具有残差连接的CBL结构
3.4 YOLOv3 效果
当 YOLOv3 发布时,目标检测的基准已经从 PASCAL VOC 更改为 Microsoft COCO。因此,从这里开始,所有的 YOLO 都在 MS COCO 数据集中进行评估。YOLOv3-spp 在 20 FPS 下实现了平均精度 AP 36.2% 和 AP50 60.6%,在当时实现了最先进技术,并且快了 2 倍。
3.5 骨干网络、中间层和头部
目标检测器的架构通常被描述为由三个部分组成:骨干网络、中间层和头部。下图显示了高级别的骨干网络、中间层和头部的图示。骨干网络负责从输入图像中提取有用的特征。它通常是一个卷积神经网络(CNN),在大规模图像分类任务(如ImageNet)上进行训练。骨干网络在不同尺度上捕获分层特征,较低层次的特征(例如边缘和纹理)在较早的层中提取,而较高层次的特征(例如物体部件和语义信息)在较深的层中提取。中间层是连接骨干网络和头部的中间组件。它聚合和精炼骨干网络提取的特征,通常专注于增强不同尺度上的空间和语义信息。中间层可能包括额外的卷积层、特征金字塔网络(FPN)[49]或其他机制来改善特征的表示
头部是目标检测器的最终组成部分;它负责根据骨干和中间提供的特征进行预测。它通常由一个或多个任务特定的子网络组成,执行分类、定位,最近也包括实例分割和姿势估计。头部处理颈部提供的特征,为每个对象候选生成预测。最后,一个后处理步骤,例如非极大值抑制(NMS),过滤掉重叠的预测,并仅保留最有信心的检测。在其余的 YOLO 模型中,我们将使用骨干、中间层和头部来描述它们的架构。
上图中,显示了高级别的骨干网络、中间层和头部的图示。骨干网络通常是一个卷积神经网络(CNN),在不同尺度上从图像中提取关键特征。中间层精炼这些特征,增强空间和语义信息。最后,头部使用这些精炼的特征进行目标检测预测
3.6 用pytorch实现YOLOv3的伪代码
为了用PyTorch实现一个YOLOv3,您可以按照以下步骤进行操作:文章来源:https://www.toymoban.com/news/detail-479607.html
- 下载YOLOv3的预训练权重文件,并将其转换为PyTorch模型。
- 定义YOLOv3的网络架构。YOLOv3包含多个卷积层、池化层和残差块,以及三个不同尺度的检测头。您可以使用PyTorch的nn.Module类来定义网络架构。
- 定义损失函数。YOLOv3使用多个损失函数来优化不同的检测头。您可以使用PyTorch的损失函数模块来定义这些损失函数。
- 加载训练数据,并将其转换为适合网络输入的格式。YOLOv3使用的输入格式是416x416的图像,以及每个目标的类别、边界框坐标和置信度得分。
- 训练网络。您可以使用PyTorch的优化器和学习率调度程序来训练网络。在训练过程中,您需要将网络输出转换为目标格式,并计算多个损失函数的总损失。
- 测试网络。在测试过程中,您需要将网络输出转换为目标格式,并使用非极大值抑制(NMS)算法来过滤重叠的边界框。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import transforms
from dataset import YOLOv3Dataset
from model import YOLOv3
# Download the pre-trained weights and convert them to PyTorch model
...
# Define the YOLOv3 network architecture
class YOLOv3(nn.Module):
def __init__(self):
super(YOLOv3, self).__init__()
...
def forward(self, x):
...
# Define the loss function
class YOLOv3Loss(nn.Module):
def __init__(self):
super(YOLOv3Loss, self).__init__()
...
def forward(self, output, target):
...
# Load the training data and transform it to the appropriate format
transform = transforms.Compose([
transforms.Resize((416, 416)),
transforms.ToTensor(),
...
])
train_dataset = YOLOv3Dataset(...)
train_loader = DataLoader(train_dataset, batch_size=..., shuffle=True)
# Define the optimizer and learning rate scheduler
optimizer = optim.Adam(...)
scheduler = optim.lr_scheduler.StepLR(...)
# Train the network
model = YOLOv3()
criterion = YOLOv3Loss()
for epoch in range(num_epochs):
for i, (images, targets) in enumerate(train_loader):
optimizer.zero_grad()
output = model(images)
loss = criterion(output, targets)
loss.backward()
optimizer.step()
scheduler.step()
# Test the network
model.eval()
with torch.no_grad():
for images, _ in test_loader:
output = model(images)
# Apply NMS algorithm to filter overlapping bounding boxes
...
下篇《YOLO技术概要学习笔记3——YOLOV4到YOLOV8》文章来源地址https://www.toymoban.com/news/detail-479607.html
到了这里,关于YOLO技术概要学习笔记2——YOLOV2到YOLOV3的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!