本系列主要是为了对redis的网络模型和集群原理进行学习,我会用golang实现一个reactor网络模型,并实现对redis协议的解析。
系列源码已经上传github
https://github.com/HobbyBear/tinyredis/tree/chapter2
redis 网络模型
在介绍redis网络模型前,我们先来看看redis的一条命令执行涉及到哪些阶段。
从连接读取数据 => 协议解析 => 命令执行 => 将结果返回给客户端
而平时我们说的redis的单线程指的则是 命令执行阶段是单线程的,而redis6.0以后协议解析和返回结果给客户端都可以是多线程去进行处理。
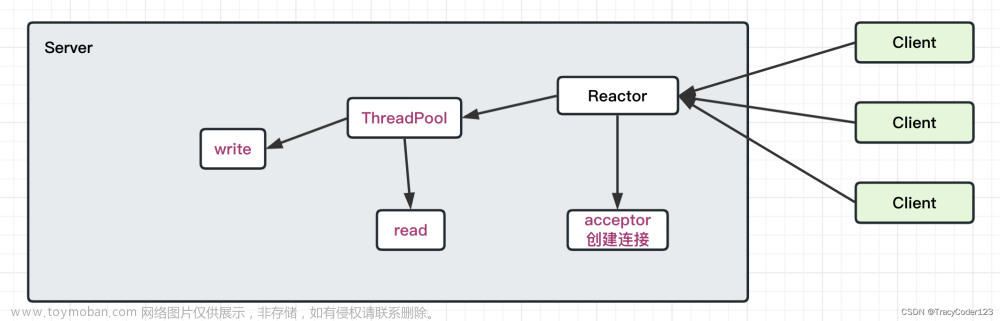
由此衍生出redis6.0的网络模型如下:

主线程通过一个epoll实例负责监听连接和等待数据的到达,并且执行解析好的命令。
举个例子,当主线程执行epoll wait时发现有100个socket可读,并且这100个socket都是已经完成连接建立的socket,然后主线程就会把这100个socket分给子线程去进行读取, 当子线程将这些socket的 字节数据解析成redis命令后,会再把这些命令交再给主线程去执行。主线程执行完以后又将这些命令执行结果交给子线程去进行发送。
整个过程可以看到实际的网络io的读取是交给多个线程去执行了,但是命令的执行还是在一个线程完成的。
再用流程图去表示整个过程将会更加清晰,

可以看见,整个过程中命令执行是在主线程去顺序执行的。而现在我们就是要用golang去实现这样一个模型。
🤔思考用golang如何实现这样的网络模型
要实现主线程等待子线程池执行的效果,我们可以用golang的sync.WaitGroup 实现主协程等待子协程执行完毕的效果,子协程去进行协议的解析,为此,在前面代码的基础上,我封装了两个队列,一个用于读,一个用于写,主协程在需要读写时就将任务丢给队列执行,并等待队列执行完毕。
type Server struct {
Poll *poll
addr string
listener net.Listener
ConnMap sync.Map
readQueue *ioReadQueue
writeQueue *ioWriteQueue
}
队列的实现则是利用sync.WaitGroup实现的等待效果,
type ioReadQueue struct {
seq atomic.Int32
handle ioReadHandle
conns []chan *Conn
wg sync.WaitGroup
requests []*Request
}
handle则是进行协议解析的方法,conns 存放的则是待解析协议的连接,在队列创建时,会启用conns长度大小的协程对conns里的连接进行读取。
func newIoReadQueue(perChannelLen int, handle ioReadHandle, goNum int) *ioReadQueue {
res := &ioReadQueue{handle: handle, wg: sync.WaitGroup{}, requests: make([]*Request, 0)}
conns := make([]chan *Conn, goNum)
for i := range conns {
conns[i] = make(chan *Conn, perChannelLen)
connlist := conns[i]
go func() {
for conn := range connlist {
....
res.wg.Done()
}
}()
}
res.conns = conns
return res
}
这样便最简单的实现了一个固定大小的协程池,然后继续进行接下来的代码编写。
对协议进行抽象
最终读队列是要对redis协议进行解析,redis的协议是被称作resp协议,由于我的重点并不是放在协议解析上,所以我不打算对resp协议的解析进行具体的讲解。但是我们要做的是对协议层进行抽象,因为当你实现一个网络框架后,你应该让你的框架支持不止一种协议,比如它同时支持http,icmp等等。
源码部分实现了对resp协议和行协议的解析,篇幅有限,所以本文只关注关键逻辑和设计即可
🤔思考抽象的一个协议需要具备哪些方法
由于网络中传输的都是字节,要转换成特定的协议,必然涉及到字节与协议体的相互转换,所以协议必然有编码和解码的方法。并且对协议的处理也应该有上层应用定义,网络框架只管对数据传输。
这样我便设计出了下面的接口
type ProtocolMsg interface {
Bytes() []byte
}
type Protocol interface {
ReadConn(c *Conn) (ProtocolMsg, error)
OnExecCmd(msg ProtocolMsg) ProtocolMsg
}
ReadConn 用于在连接可读时从连接读取协议数据,这将由应用层自己定义解码操作,OnExecCmd 用于处理解析出的协议消息,OnExecCmd返回结果到时则会由网络框架层进行发送,协议消息编码为字节数据的方式则是ProtocolMsg的Bytes 方法中定义的,ProtocolMsg 会由应用层自己实现。
❗️❗️不过这里还有一点要做修改,ReadConn定义的是解码的操作,直接将网络框架内部的Conn传递给应用层进行读写不够安全,更安全的方式是只传递一个读缓冲区给应用层进行读写。这样的好处还有一个,因为我们的目的是非阻塞的读取连接里的数据,如果连接到达的数据还不能够组成一个完整的协议,那么这个连接已经读取出来的数据应该保存起来,供下次读取时,组成一个完整的协议。
所以,我们要为Conn这个结构定义一个缓冲区了。在通过redis学网络(1)-用go基于epoll实现最简单网络通信框架 里我们定义的Conn结构是
type Conn struct {
s *Server
conn *net.TCPConn
nfd int
}
现在还需要为它加一个缓冲区结构,并且为了复用缓冲区内存,我实现了一个RingBuffer 结构,关于其实现的讲解可以参考我的这篇文章go 实现ringbuffer以及ringbuffer使用场景介绍
目前Conn结构将变为
type Conn struct {
s *Server
conn *net.TCPConn
reader *RingBuffer
nfd int
}
然后协议解码接口我将把缓冲区传进去
type Protocol interface {
ReadConn(c *Conn) (ProtocolMsg, error)
OnExecCmd(msg ProtocolMsg) ProtocolMsg
}
环形缓冲区RingBuffer 的方法我再在这里列举一下
func (r *RingBuffer) Peek(readOffsetBack, n int) ([]byte, error) {
...
}
func (r *RingBuffer) PeekBytes(readOffsetBack int, delim byte) ([]byte, error) { ...
}
func (r *RingBuffer) AddReadPosition(n int) {
...
}
RingBuffer的peek开头的方法不会改变读指针的位置,但是会读取数据,AddReadPosition则是应用层在判断是完整协议后调用的方法,用于更新读指针的位置。
接着再来看服务器的handle方法主要做的改动。我在关键步骤标记了注释文章来源:https://www.toymoban.com/news/detail-479941.html
func (s *Server) handler() {
for {
// 等待连接事件到达
events, err := s.Poll.WaitEvents()
if err != nil {
log.Error(err.Error())
continue
}
for _, e := range events {
connInf, ok := s.ConnMap.Load(int(e.FD))
if !ok {
continue
}
conn := connInf.(*Conn)
if IsClosedEvent(e.Type) {
conn.Close()
continue
}
// 连接可读,则放到读队列
if IsReadableEvent(e.Type) {
s.readQueue.Put(conn)
}
}
// 等待读队列任务完成
s.readQueue.Wait()
requests := s.readQueue.requests
replyMsgs := make([]*Request, 0)
// 将读队列解析好的命令进行执行
for _, request := range requests {
replyMsgs = append(replyMsgs, &Request{msg: s.protocol.OnExecCmd(request.msg), conn: request.conn})
}
// 将执行结果放回到写队列执行
for _, replyMsg := range replyMsgs {
s.writeQueue.Put(replyMsg)
}
// 等待些队列执行完毕
s.writeQueue.Wait()
// 由于读队列缓存了中间结果,一次轮询后进行清除
s.readQueue.Clear()
}
}
对于代码的讲解和设计思路,我这里只是列出了关键的点,细节可能还是需要去看下源码是如何实现的。但是最重要的是通过这个小demo,理解epoll的网络编程并且理解了redis的网络模型。文章来源地址https://www.toymoban.com/news/detail-479941.html
到了这里,关于通过redis学网络(2)-redis网络模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!