2022.12.4 大数据运维基础篇 本章主要是基础坏境配置
目录
前言
一、hadoop是什么?
1.1 Hadoop 是什么
1.2 Hadoop 优势
1.3 Hadoop 组成
二、大数据技术体系
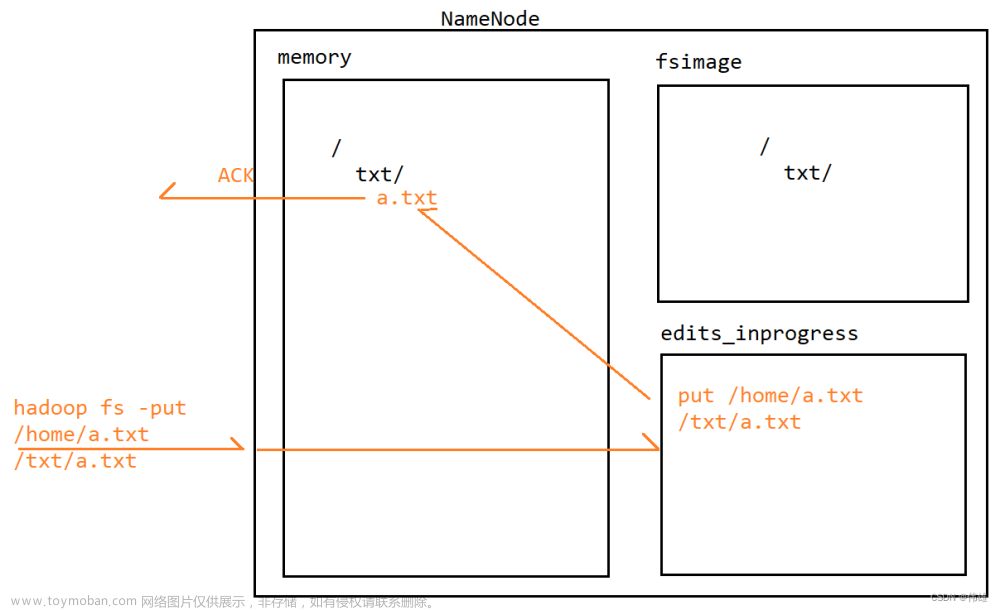
2.1 HDFS 架构概述Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。
2.2 YARN 架构概述
2.3 MapReduce 架构概述
三. 推荐系统框架图
四. 实操 Hadoop集群基础环境的配置 (重点!!!)
1.配置ip
2.设置主机名(三台都需要)
3.集群ip地址和主机名的映射
4.创建hadoop用户
5.关闭防火墙
5.1 步骤一:关闭防火墙(三台都要关闭)
5.2 步骤二:关闭防火墙自启
5.3 步骤三:查看防火墙状态
6.配置集群主机之间的时钟同步(避免集群中主机连接超时)
6.1 直接同步(集群中所有的节点都可以访问互联网)
6.2平滑时间同步
7. SSH免密(重要!)
7.1 生成ssh密钥
7.2 交换ssh密钥
总结
前言
适用于大数据平台运维 1+x证书等
一、hadoop是什么?
1.1 Hadoop 是什么
(1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构
(2)主要解决海量数据的存储和海量数据的分析计算问题
(3)广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈
1.2 Hadoop 优势
(1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
(2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
(3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
(4)高容错性:能够自动将失败的任务重新分配。
1.3 Hadoop 组成

版权声明:本文为CSDN博主「@从一到无穷大」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/huxili2020/article/details/117809913
二、大数据技术体系

图中涉及的技术名词解释如下:
(1)Sqoop:Sqoop 是一款开源的工具,主要用于在Hadoop、Hive 与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop 的HDFS 中,也可以将HDFS 的数据导进到关系型数据库中。
(2)Flume:Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据。
(3)Kafka:Kafka 是一种高吞吐量的分布式发布订阅消息系统。
(4)Spark:Spark 是当前最流行的开源大数据内存计算框架。可以基于Hadoop 上存储的大数据进行计算。
(5)Flink:Flink 是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
(6)Oozie:Oozie 是一个管理Hadoop 作业(job)的工作流程调度管理系统。
(7)Hbase:HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
(8)Hive:Hive 是基于Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL 查询功能,可以将SQL 语句转换为MapReduce 任务进行运行。其优点是学习成本低,可以通过类SQL 语句快速实现简单的MapReduce 统计,不必开发专门的MapReduce 应用,十分适合数据仓库的统计分析。
(9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
### 重点:HDFS Yarn MapReduce
2.1 HDFS 架构概述
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。
(1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
(2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
(3)Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
2.2 YARN 架构概述
Yet Another Resource Negotiator 简称YARN ,另一种资源协调者,是Hadoop 的资源管理器。
ResourceManager(RM):整个集群资源(内存、CPU等)的管理者
NodeManager(NM):单个节点服务器资源的管理者。
ApplicationMaster(AM):单个任务运行的管理者。
Container:容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。
2.3 MapReduce 架构概述
MapReduce 将计算过程分为两个阶段:Map 和 Reduce
1)Map 阶段并行处理输入数据
2)Reduce 阶段对Map 结果进行汇总
三. 推荐系统框架图

四. 实操 Hadoop集群基础环境的配置 (重点!!!)
master slave1 slave2 三台主机以单链路连接为例 (理论+实操相结合以便更好理解,单理论或者单实操都是不可取的)
1.配置ip
之前博客教程如下:
linux网络配置(超简单,一看就会)_北神树的博客-CSDN博客
命令:ip a 查看网络
确定linux系统vim等工具能够正常使用,不能则需下载(下载命令 yum -y install “xx”)
2.设置主机名(三台都需要)
[root@localhost ~]# hostnamectl set-hostname master
[root@localhost ~]# bash
[root@localhost ~]# hostnamectl set-hostname slave1
[root@localhost ~]# bash
[root@localhost ~]# hostnamectl set-hostname slave2
[root@localhost ~]# bash
三台主机名修改完成
主机名修改方法二,永久保存
[root@localhost ~]# vi /etc/profile/hostname #将master节点的主机名修改为master
.....
3.集群ip地址和主机名的映射
映射文件地址: /etc/hosts
[root@master ~]# vi /etc/hosts
[root@slave1 ~]# vi /etc/hosts
[root@slave2 ~]# vi /etc/hosts
配置完毕后使用 reboot命令重启系统 使配置生效
或者使用source命令 格式 : source 配置文件 如:#source /etc/profile,可以使配置的profile文件立刻生效

4.创建hadoop用户
#useradd hadoop
#passwd (hadoop) 密码自设
5.关闭防火墙
5.1 步骤一:关闭防火墙(三台都要关闭)
[root@master ~]# systemctl stop firewalld.service
[root@slave1 ~]# systemctl stop firewalld.service
[root@slave2 ~]# systemctl stop firewalld.service
5.2 步骤二:关闭防火墙自启
[root@master ~]# systemctl disable firewalld.service
[root@slave1 ~]# systemctl disable firewalld.service
[root@slave2 ~]# systemctl disable firewalld.service
5.3 步骤三:查看防火墙状态
[root@master ~]# systemctl status firewalld.service
[root@slave1 ~]# systemctl status firewalld.service
[root@slave2~]# systemctl status firewalld.service

6.配置集群主机之间的时钟同步(避免集群中主机连接超时)
NTP同步方式分为直接同步和平滑同步两种
6.1 直接同步(集群中所有的节点都可以访问互联网)
1.查看ntp服务是否安装
[root@master ~]#rpm -qa | grep ntp
安装成功会有版本信息
若无则安装
[root@master ~]# yum -y install ntp
2.直接同步时间
[root@master ~]# ntpd
6.2平滑时间同步
适用于一个节点可以联网或者所有节点都不能联网,则可以在集群中选择一个节点,将其搭建成一个内网的NTP时间服务器,然后让集群中的各个节点与这个NTP服务器进行时间同步
1.同步时间
[root@master ~]# vi /etc/sysconfig/ntpdate
在ntpd文档中添加一行内容
SYS_HWLOCK=yes
2.启动服务
启动ntp服务
[root@master ~]# service ntpd start
设置ntpd为开机自启动状态
[root@master ~]# chkconfig ntpd on
3.编辑 /etc/ntp.conf
[root@master ~]# vi /etc/ntp.conf
(1)在文件中添加
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
#设置始终同步的广播地址
(2)并注释下方四行内容
#service 0.ccentos.pool.ntp.org
#service 1.ccentos.pool.ntp.org
#service 2.ccentos.pool.ntp.org
#service 3.ccentos.pool.ntp.org
(3)去掉以下内容的注释(如果没有就加上)
server 127.127.1.0 # local -e
fudge 127.127.127.1.0 stratum 10
4.slave节点与master节点时间同步
[root@master ~]# crontab -e
添加以下任务
*/ 1* * * */usr/sbin/ntpdate 192.168.1.6
查看时间
data命令
7. SSH免密(重要!)
问 :为什么需要免密? 答:hadoop运行过程中需要管理远端
7.1 生成ssh密钥
7.1.1 切换用户
[root@master ~]#su - hadoop
[root@slave1 ~]#su - hadoop
[root@slave2 ~]#su - hadoop
7.1.2 在每个节点上生成密钥对
[hadoop@master ~]$ ssh-keygen -t rsa -P " "
[hadoop@slave1 ~]$ ssh-keygen -t rsa -P ""
[hadoop@slave2 ~]$ ssh-keygen -t rsa -P ""
在每个节点上均使用ssh-keygen命令生成密钥对,使用-t他参数设定加密类型,本次用rsa加密方式,并使用-P 参数设定密钥保护密码,本次未设定密钥保护类型,传递空符串作为参数
7.1.3 在master节点上创建公钥
[hadoop@master ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
可以查看密钥文件和授权文件
[hadoop@master ~]$ ls ~/.ssh/
authorized_keys id_rsa i d_rsa.pub
[hadoop@master ~]$ chmod 700 ~/.ssh/authorized_keys #赋予权限
通过重定向的方式将id_rsa.pub文件中的内容写入授权的authorized_keys文件中
7.2 交换ssh密钥
7.2.1 交换密钥
1.将master节点上的公钥分发给slave1节点
[hadoop@master ~]$ scp ~/.ssh/authorized_keys hadoop@slave1:~/.ssh/
#输入yes #输入hadoop用户密码
2.在slave1节点追加公钥
[hadoop@slave1 ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
3.将slave1节点上的公钥分发给slave2和master节点
[hadoop@slave1 ~]$ scp ~/.ssh/authorized_keys hadoop@slave2:~/.ssh/
[hadoop@slave1 ~]$ scp ~/.ssh/authorized_keys hadoop@master:~/.ssh/
4.在slave2节点追加公钥
[hadoop@slave2 ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
5.将slave1节点上的公钥分发给slave1和master节点
[hadoop@slave1 ~]$ scp ~/.ssh/authorized_keys hadoop@slave1:~/.ssh/
[hadoop@slave1 ~]$ scp ~/.ssh/authorized_keys hadoop@master:~/.ssh/
#总体而言,就是主节点master创建公钥 每个节点都追加公钥,并把公钥分发给另外的两个节点,让每个节点都有其他节点包括自己的钥匙
7.2.2 验证ssh无密码登录
1.查看master/slave1/slave2 节点的authorized_keys 文件
[hadoop@master ~]$ cat ~/.ssh/authorizded_keys #或用vim命令
2.ssh验证
[hadoop@slave1 ~]$ ssh slave2
........
总结
理论参考CSDN博主「@从一到无穷大」/ 大数据平台运维(中级)课本所编写
实践参考大数据平台运维(中级)课本所编写文章来源:https://www.toymoban.com/news/detail-480179.html
仅供学习使用文章来源地址https://www.toymoban.com/news/detail-480179.html
到了这里,关于大数据平台运维(hadoop入门(保姆篇))----概述及基本环境配置(HA-1)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!