目录
一、课题说明
1.1、设计原因:
1.2、设计目标:
1.3、开发环境:
1.4、爬取网站链接
二、准备工作
2.1、数据获取:
2.2、爬取的数据说明:
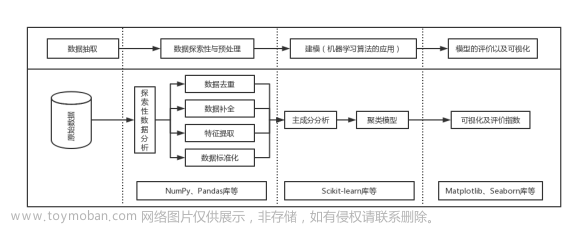
2.3、爬虫程序设计的思路:
三、详细设计
3.1、导入库的模块:
3.2、对数据先进行读取:
3.2.1、显示前5条记录
3.2.2、查看数据的规模:行数和列数
3.2.3、利用info()查看数据的维度、字段名及类型等
3.2.4、利用describe()查看数据初步统计信息
3.3、对数据整体进行清洗:
3.3.1、查看数据是否有缺失值或者重复值
3.3.2、查看各元素是否为空值
3.4、对数据进行统计:
3.4.1、查看规格列包含具体种类
3.4.2、查看规格列各种类出现的次数
3.5、对蔬菜数据分析
3.5.1、查看每一列的数据类型
3.5.2、查看价格的相关情况
3.5.3、随机抽取10条数据:
3.6数据可视化展示:
3.6.1、#绘制每个属性的直方图,来快速了解数据
3.6.2、对平均价做对应的直方图与密度图的集合、加阴影的图以及小细线图
3.6.3、对产地以及品名做计数图
3.6.4、对产地的最高价绘制散点图
3.6.5、对蔬菜信息表的前70条数据产地的平均价绘制箱线图
3.6.6、对蔬菜信息表的前100条数据绘制最高价与最低价绘制多面板图
3.6.7、对蔬菜信息表第10条到20条数据绘制分组关系图
3.6.8、对于蔬菜信息表的最高价、最低价、平均价特征进行两两对比
3.6.9、绘制蔬菜信息表100到300条数据品名次数分布的散点图
3.6.10、蔬菜规格展示图
3.6.11、按照产地绘制柱状图
3.6.12、分析最高价与最低价以及平均价之间的箱线图
3.6.13、查看鲁地的各蔬菜平均价的分布情况饼图展示
3.6.14、绘制产地的词云
3.6.15、红尖椒与线椒的最高价、最低价、平均价随日期的变化趋势
3.6.16、绘制最高价前40的品名的散点图
3.6.17“红尖椒”的最高价在全部时间的分布情况饼图展示
3.6.18、“番茄”的最高价在全部时间的变化情况折线图展示
3.6.19、产地信息第200到1000条数据的蔬菜分布图
3.6.20、最低价排序第300到500条数据的蔬菜分布图
3.6.21、查看规格列各种类出现的次数,并且绘制节点图
3.6.22、部分蔬菜产地路线和数量图
四、设计遇到的问题以及难点:
4.1关键技术与难点:
4.2 处理数据与绘制图像
五、设计的总结与体会
一、课题说明
1.1、设计原因:
参考数据可视化课程内容,结合已学习的课程知识,对新发地官网的蔬菜价格数据进行“爬取—清洗—存储—可视化—结论性分析”的工作。
1.2、设计目标:
通过对上述数据的爬取和分析,实现对数据的整体评价或预测,并对一些数据进行可视化展示。
1.3、开发环境:
主要是Jupyter Notebook
1.4、爬取网站链接
http://www.xinfadi.com.cn/priceDetail.html
二、准备工作
2.1、数据获取:
爬取的代码:
import json
import requests
import threading
import pandas as pd
# 页数
page = 1
# 商品总列表
count = []
# json列表
jsons = []
# 解析网页函数
def url_parse(page):
# 请求地址
url = 'http://www.xinfadi.com.cn/getPriceData.html'
headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Content-Length": "89",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Host": "www.xinfadi.com.cn",
"Origin": "http://www.xinfadi.com.cn",
"Pragma": "no-cache",
"Referer": "http://www.xinfadi.com.cn/priceDetail.html",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36",
"X-Requested-With": "XMLHttpRequest",
}
data = {
"limit": "20",
"current": page,
"pubDateStartTime": "",
"pubDateEndTime": "",
"prodPcatid": "1186", # 商品类id
"prodCatid": "",
"prodName": "",
}
response = requests.post(url=url, headers=headers, data=data).text
# 获取商品信息
response = json.loads(response)['list']
# 生成线程锁对象
lock = threading.RLock()
# 上锁
lock.acquire()
# 添加到json列表中
jsons.append(response)
# 解锁
lock.release()
# 解析json函数
def json_parse(product):
lock = threading.RLock()
lock.acquire()
dic = {'品名': product['prodName'], "最低价": product['lowPrice'], '最高价': product['highPrice'],
'平均价': product['avgPrice'], '规格': product['specInfo'], '产地': product['place'],
'单位': product['unitInfo'],
'发布日期': product['pubDate']}
print(dic)
# 将商品信息添加到商品总列表中
count.append(dic)
lock.release()
if __name__ == '__main__':
num = int(input('请输入爬取页数:'))
# 多进程解析网页
for i in range(1, num + 1):
x = threading.Thread(target=url_parse, args=(i,))
x.start()
x.join()
# 多进程解析json
for i in jsons:
for product in i:
y = threading.Thread(target=json_parse, args=(product,))
y.start()
y.join()
# 生成excel
data = pd.DataFrame(count)
data.to_excel('爬取蔬菜相关信息.xlsx', index=None)2.2、爬取的数据说明:
本次爬虫从2022-11-07到2022-11-22开始爬取,共爬取了100页,1741条数据,八列分别为品名、最低价、最高价、平均价、规格、产地、单位、发布日期、等,其中无重复值,产地有409个缺失值,规格有1188个缺失值,缺失值过多不能直接删除,这两个变量在后续研究中只看比较关系,无需填充,所以不用进行缺失值处理。数据类型有两类,object类型的数据有产地、单位、发布日期、品名、规格等,float64类型的数据包括平均价、最低价、最高价等。
2.3、爬虫程序设计的思路:
向HTML网页提交POST请求的方法,对应于HTTP的POST,找到蔬菜信息页面,然后进行翻页,发现页面的url没有发生改变,所有蔬菜信息是通过接口数据动态获取的,是动态数据。进行chrom调试抓包,找到每个页面信息所在的url,发现每个信息的url都相同,post请求,formdata不同。通过修改提交的data来获取不同页面的蔬菜信息。
三、详细设计
3.1、导入库的模块:
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import jieba
from tkinter import _flatten
import wordcloud
import warnings#引入警告信息库
warnings.filterwarnings('ignore')#过滤警告信息
import pandas as pd
from matplotlib.font_manager import FontProperties
plt.rcParams['font.sans-serif']=['simhei']# 添加中文字体支持
plt.rcParams['font.serif'] = ['simhei']
%matplotlib inline3.2、对数据先进行读取:
3.2.1、显示前5条记录
df1 = pd.read_excel(r'爬取蔬菜相关信息.xlsx')
df1
df1.head()查询结果:
3.2.2、查看数据的规模:行数和列数
print(df1.shape) #查看维度
print(df1.index.size) #获得行数
print(df1.columns.size) #获得列数查询结果:
(1740, 8)
1740
8
3.2.3、利用info()查看数据的维度、字段名及类型等
df1.info()查询结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1740 entries, 0 to 1739
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 品名 1740 non-null object
1 最低价 1740 non-null float64
2 最高价 1740 non-null float64
3 平均价 1740 non-null float64
4 规格 552 non-null object
5 产地 1331 non-null object
6 单位 1740 non-null object
7 发布日期 1740 non-null object
dtypes: float64(3), object(5)
memory usage: 108.9+ KB
3.2.4、利用describe()查看数据初步统计信息
df1.describe()查询结果:
3.3、对数据整体进行清洗:
3.3.1、查看数据是否有缺失值或者重复值
#查看是否存在重复行
df1.duplicated()
#查看重复行与非重复行的数量
cf = df1.duplicated()
cf.value_counts()查询结果:
False 1740
dtype: int64
3.3.2、查看各元素是否为空值
df1.isnull()
df1.isnull().any()
#各列含空值的具体数目
df1.isnull().sum()查询结果:
品名 0
最低价 0
最高价 0
平均价 0
规格 1188
产地 409
单位 0
发布日期 0
dtype: int64
可以得到该数据集中产地有409个缺失值,规格有1188个缺失值,缺失值过多不能直接删除,这两个变量在后续研究中只看比较关系,所以无需填充
3.4、对数据进行统计:
3.4.1、查看规格列包含具体种类
p1 = df1['规格'].drop_duplicates()
ww = []
for i in p1:
ww.append(i)
ww查询结果:
[nan, '大', '白球\\净', '毛\\箱', '大\\小', '红\\黄', '泥\\洗', '洗', '脆', '黄', '麻', '泥', '红', '铁棍', '龙薯九', '西瓜红\\烟薯', '湿\\干', '黏\\甜', '长\\短', '箱', '袋\\箱', '黑框', '纸箱\\泡沫箱', '白框', '鲜干花', '旱\\荷兰', '吊', '地', '长\\小', '姜头\\整', '机剥\\手工', '净', '毛', '新', '小叶']
3.4.2、查看规格列各种类出现的次数
from collections import Counter
Counter(df1['规格'])查询结果:
Counter({nan: 1188,
'大': 17,
'白球\\净': 15,
'毛\\箱': 15,
'大\\小': 15,
'红\\黄': 16,
'泥\\洗': 29,
'洗': 31,
'脆': 15,
'黄': 15,
'麻': 14,
'泥': 16,
'红': 15,
'铁棍': 14,
'龙薯九': 14,
'西瓜红\\烟薯': 14,
'湿\\干': 12,
'黏\\甜': 13,
'长\\短': 13,
'箱': 13,
'袋\\箱': 56,
'黑框': 15,
'纸箱\\泡沫箱': 15,
'白框': 15,
'鲜干花': 14,
'旱\\荷兰': 14,
'吊': 14,
'地': 14,
'长\\小': 14,
'姜头\\整': 14,
'机剥\\手工': 14,
'净': 14,
'毛': 14,
'新': 14,
'小叶': 5})
可以看到规格为'袋\箱'的较多,出现了56次,其次依次是'洗'31次,’泥\洗’29,'大'17次,'等,'小叶'出现较少,仅有5次,规格列缺失较多,但我们只需对已有的值进行分析,.缺失值不影响比较结果,所以不对其进行处理
3.5、对蔬菜数据分析
3.5.1、查看每一列的数据类型
df1.dtypes查询结果:
品名 object
最低价 float64
最高价 float64
平均价 float64
规格 object
产地 object
单位 object
发布日期 object
dtype: object
3.5.2、查看价格的相关情况
#最高价的平均值
pj1 = df1['最高价'].mean()
print("最高价的平均值是{}".format(pj1))
#最高价的众数:
zs1 = df1['最高价'].mode()
print("最高价的众数是:{}".format(zs1))
#最高价的方差:
fc1 = df1['最高价'].var()
print("最高价的方差是:{}".format(fc1))查询结果:
最高价的平均值是3.1683333333333357
最高价的众数是:0 2.0
Name: 最高价, dtype: float64
最高价的方差是:12.062323270078608
#最低价的平均值
pj2 = df1['最低价'].mean()
print("最低价的平均值是{}".format(pj2))
#最低价的众数:
zs2 = df1['最低价'].mode()
print("最低价的众数是:{}".format(zs2))
#最低价的方差:
fc2 = df1['最低价'].var()
print("最低价的方差是:{}".format(fc2))查询结果:
最低价的平均值是2.454327586206895
最低价的众数是:0 1.5
Name: 最低价, dtype: float64
最低价的方差是:10.684754061688226
#平均价的平均值
pj3 = df1['平均价'].mean()
print("平均价的平均值是{}".format(pj3))
#平均价的众数:
zs3 = df1['平均价'].mode()
print("平均价的众数是:{}".format(zs3))
#平均价的方差:
fc3 = df1['平均价'].var()
print("平均价的方差是:{}".format(fc3))查询结果:
平均价的平均值是2.8115000000000028
平均价的众数是:0 1.25
Name: 平均价, dtype: float64
平均价的方差是:11.286187455434195
对最高价、最低价以及平均价做成图表:
data = {'平均值':[pj1,pj2,pj3],'众数':[zs1,zs2,zs3],'方差':[fc1,fc2,fc3]}
w = pd.DataFrame(data,index=['最高价','最低价','平均价'])
w3.5.3、随机抽取10条数据:
sj = df1.sample(10)
sj3.6数据可视化展示:
3.6.1、#绘制每个属性的直方图,来快速了解数据
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['simhei']# 添加中文字体支持
plt.rcParams['font.serif'] = ['simhei']
df1.hist(bins=100,figsize=(20,20))
plt.show()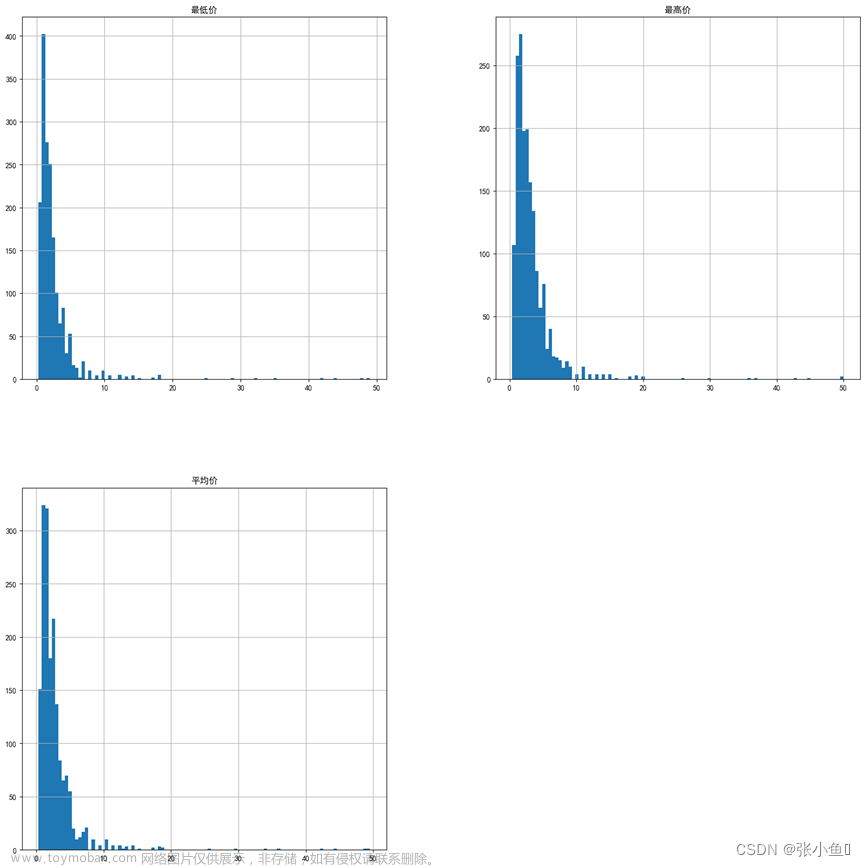
3.6.2、对平均价做对应的直方图与密度图的集合、加阴影的图以及小细线图
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['simhei']# 添加中文字体支持
plt.rcParams['font.serif'] = ['simhei']
fig,axes = plt.subplots(1,3)
sns.distplot(df_sc['平均价'].head(80),ax = axes[0],kde = True,rug = True)
sns.kdeplot(df_sc['平均价'].head(80),ax = axes[1],shade = True)#阴影
sns.rugplot(df_sc['平均价'].head(80),ax = axes[2])
plt.show()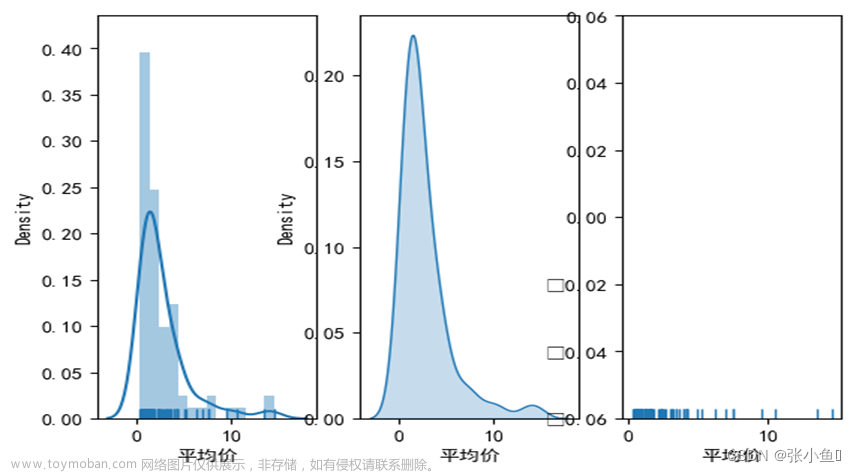
3.6.3、对产地以及品名做计数图
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['simhei']# 添加中文字体支持
plt.rcParams['font.serif'] = ['simhei']
sns.countplot(x = "产地",hue = "品名",data = df_sc.head(20))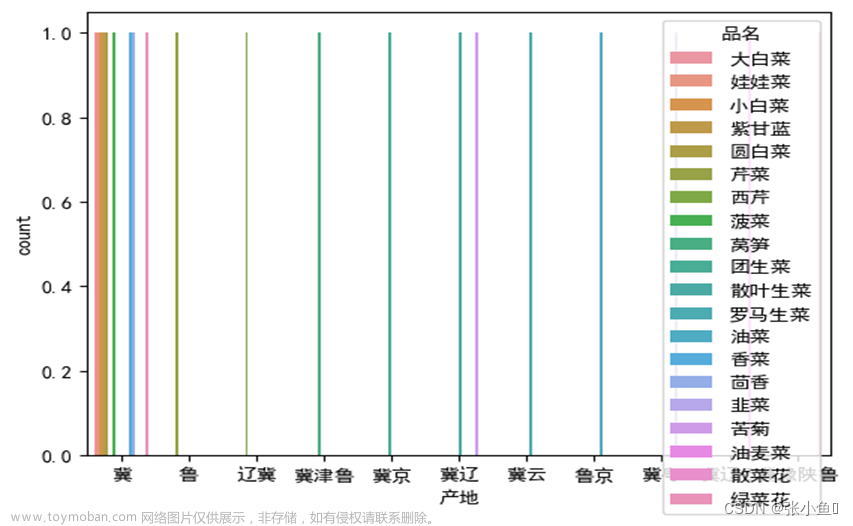
3.6.4、对产地的最高价绘制散点图
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['simhei']# 添加中文字体支持
plt.rcParams['font.serif'] = ['simhei']
sns.swarmplot(x=df_sc['最高价'][200:400],y=df_sc['产地'][200:250],data=df_sc['最高价'][200:400])#产地上面最高价的数量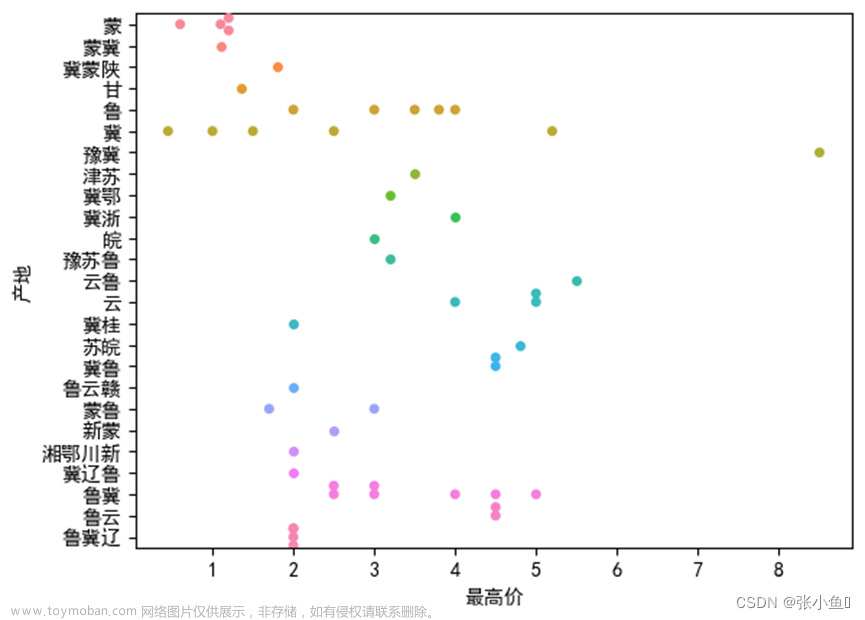
3.6.5、对蔬菜信息表的前70条数据产地的平均价绘制箱线图
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['simhei']# 添加中文字体支持
plt.rcParams['font.serif'] = ['simhei']
sns.boxplot(x = df_sc['产地'].head(70),y = df_sc['平均价'][40:100])#箱线图
plt.show()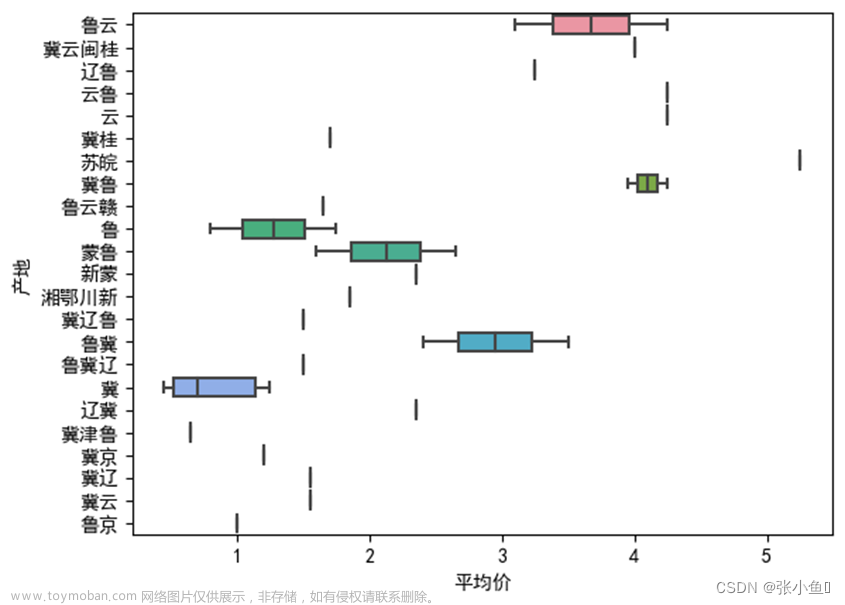
3.6.6、对蔬菜信息表的前100条数据绘制最高价与最低价绘制多面板图
sns.jointplot(kind = "hex",x = '最高价',y = '最低价',data = df_sc.head(100))
#绘图多变量分布关系
plt.show()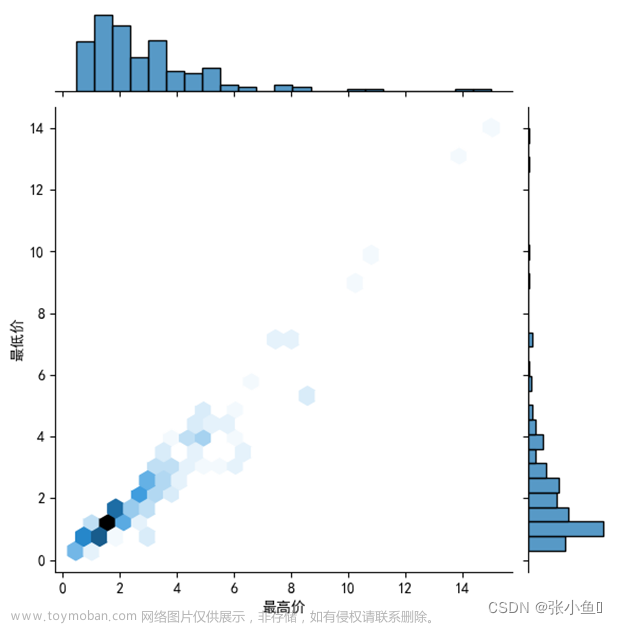
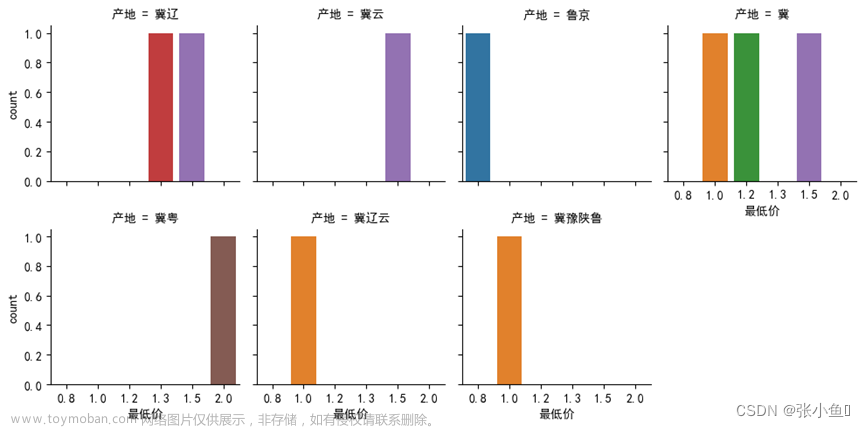
3.6.7、对蔬菜信息表第10条到20条数据绘制分组关系图
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['simhei']# 添加中文字体支持
plt.rcParams['font.serif'] = ['simhei']
sns.factorplot(x = "最低价",col = "产地",col_wrap = 4,data = df_sc[10:20],kind = "count",size = 2.5,aspect = 1)
3.6.8、对于蔬菜信息表的最高价、最低价、平均价特征进行两两对比
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['simhei']# 添加中文字体支持
plt.rcParams['font.serif'] = ['simhei']
sns.pairplot(df_sc[['最高价','最低价','平均价']],diag_kind = 'auto')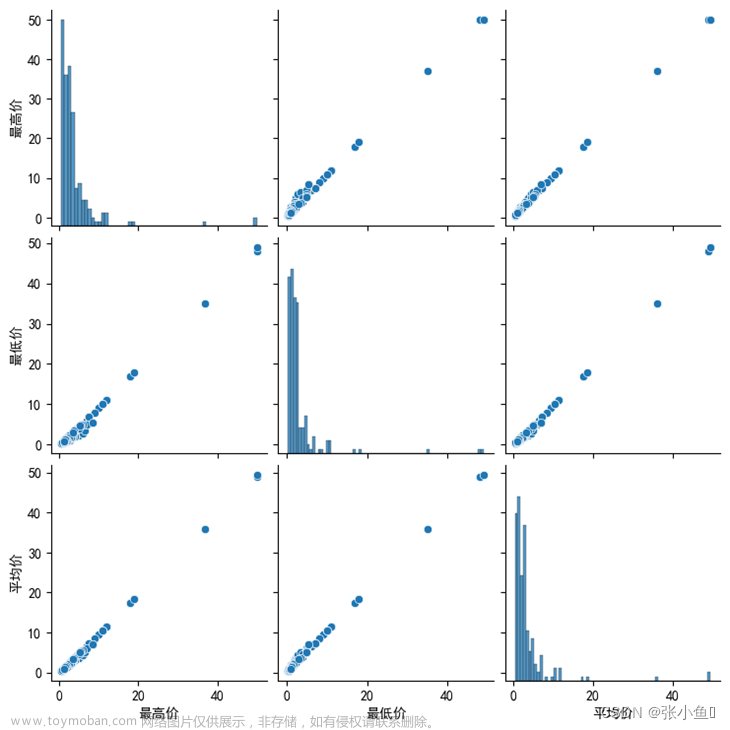
3.6.9、绘制蔬菜信息表100到300条数据品名次数分布的散点图
from pyecharts.charts import Scatter
w2 = data1.sort_values('品名',ascending=True)[100:300]
y = []
x = []
for i in w2['品名'].value_counts().index:
x.append(i)
for i in w2['品名'].value_counts():
y.append(i)
c = Scatter(opts.InitOpts(width = '660px',height = "380px"))
c.add_xaxis(x)#x轴
c.add_yaxis("品名次数",y)#加入与前面的一一对应
c.set_global_opts(title_opts = opts.TitleOpts(title = "品名出现次数的散点图"))
c.render_notebook()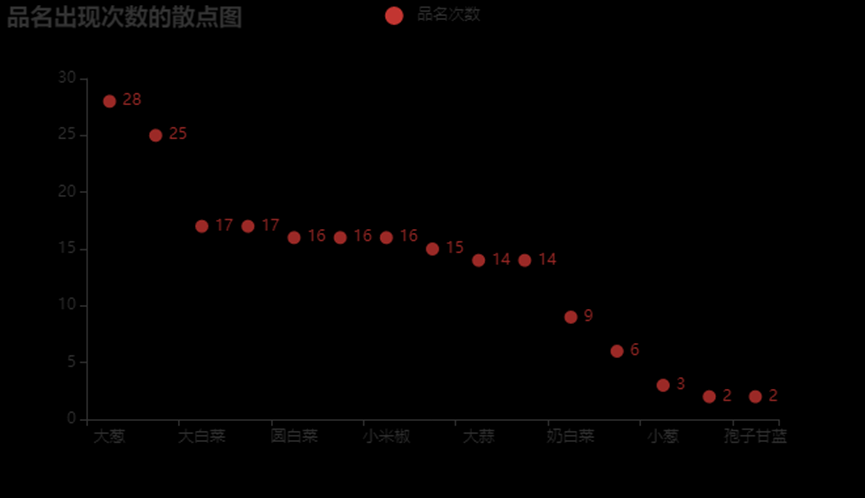
3.6.10、蔬菜规格展示图
from pyecharts import options as opts
from pyecharts.charts import Pie
www = df1['规格'].value_counts().index
cc = df1['规格'].value_counts()
c = (Pie().add("", [list(z) for z in zip(www,cc)],center=["80%", "40%"],radius=["30%", "60%"],)
.set_global_opts(title_opts=opts.TitleOpts(title="蔬菜规格"),
legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="0%"),)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}")))
c.render_notebook()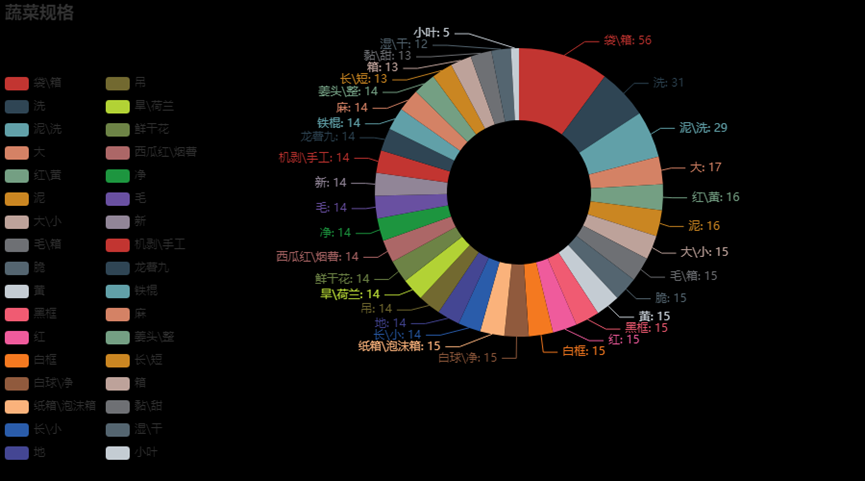
3.6.11、按照产地绘制柱状图
w2 = data1.sort_values('产地',ascending=True)
y = []
x = []
for i in w2['产地'].value_counts().index:
x.append(i)
for i in w2['产地'].value_counts():
y.append(i)
bar1 = (Bar().add_xaxis(x).add_yaxis('个数', y)
.set_global_opts(title_opts=opts.TitleOpts("产地信息的蔬菜分布图"),
yaxis_opts=opts.AxisOpts(name="个数"),
xaxis_opts=opts.AxisOpts(name="产地"))
)
bar1.render_notebook()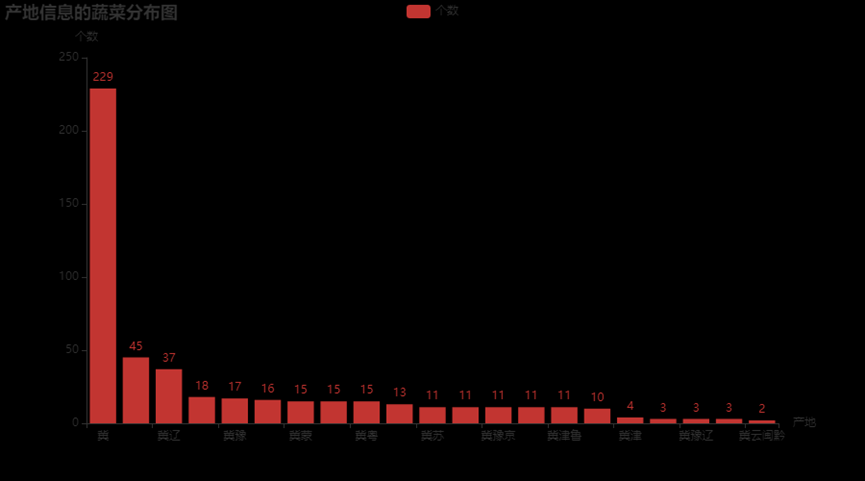
3.6.12、分析最高价与最低价以及平均价之间的箱线图
corr = df1[['最高价','最低价','平均价']].corr()
corr
sns.heatmap(corr,xticklabels = corr.columns,yticklabels = corr.columns)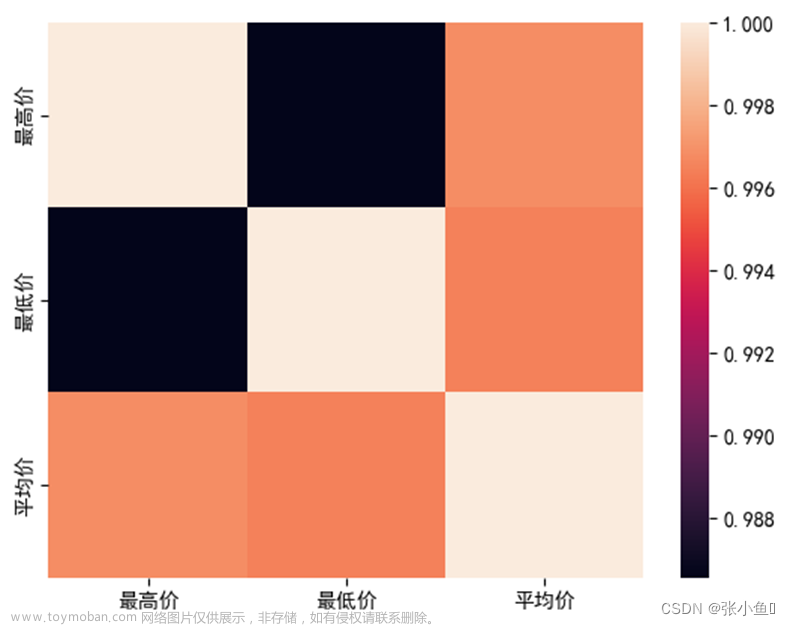
3.6.13、查看鲁地的各蔬菜平均价的分布情况饼图展示
data1 = pd.read_excel(r'爬取蔬菜相关信息.xlsx')
d1 = data1[data1['产地'] == "鲁"]
from pyecharts.charts import *
from pyecharts import options as opts
num = d1['平均价'].value_counts()
c = Pie(init_opts=opts.InitOpts(theme='light',width='1000px',height='600px'))
c.add("", [list(z) for z in zip(num.index, num)])
c.set_global_opts(title_opts=opts.TitleOpts(title="鲁地的各蔬菜平均价的分布情况饼图"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="90%", orient="vertical"))
c.set_colors(["blue", "green", "yellow", "red", "pink", "orange", "purple"])
c.set_series_opts(label_opts=opts.LabelOpts(position='top',
color='red', font_family='Arial',
font_size=12,font_style='italic',
interval=1,formatter='{b}:{c}, 占比{d}%'))
c.render_notebook()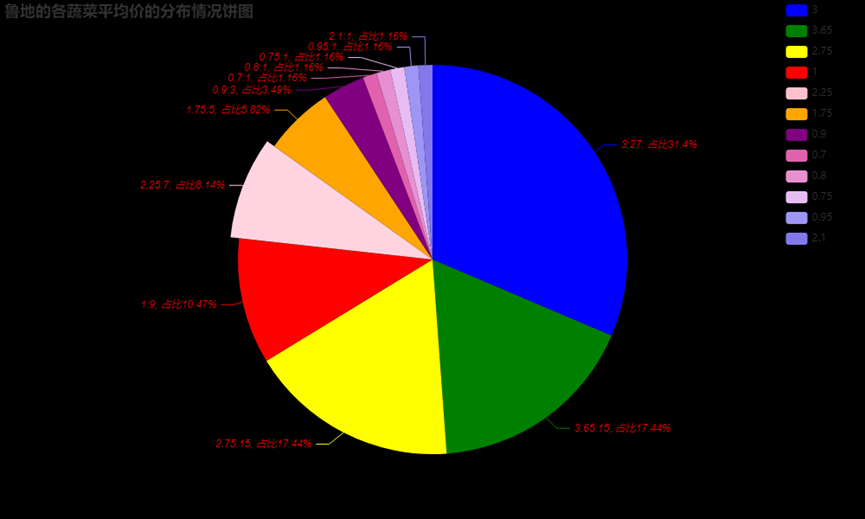
3.6.14、绘制产地的词云
import jieba
from tkinter import _flatten
import wordcloud
data1 = pd.read_excel(r'爬取蔬菜相关信息.xlsx').astype(str)
comment =data1[~data1['产地'].isin(["nan"])]
comment_cut = comment['产地'].apply(jieba.lcut)
comment_last = [] #一维列表,存放分词结果
for i in comment_cut:
for j in i:
comment_last.append(j)
counts = {}
for word in comment_last:
if len(word) > 1:
counts[word] = counts.get(word, 0) + 1
pic = plt.imread(r'tx5.jpg')
w = wordcloud.WordCloud(
mask = pic, #背景图片
background_color = 'white',#词云背景颜色
font_path='C:/Windows/Fonts/simhei.TTF' #设置为中文字体,否则无法正常显示
)
w.fit_words(counts)#传入词频为字典类型,dic为上述字典
plt.imshow(w) #转为plt图形数据
plt.axis('off')#取消显示x-y轴
plt.show()#展示图形
w.to_file(r'产地5.jpg')
3.6.15、红尖椒与线椒的最高价、最低价、平均价随日期的变化趋势
yj = df1[df1['产地']=='鲁冀']
yj['规格'].value_counts()
yj['品名'].value_counts()
x=[]
for i in yj['发布日期'].sort_values().drop_duplicates():#.drop_duplicates去重
x.append(i[4:20])
print(x)
r1 = yj[yj['品名']=='红尖椒']['最高价']
r2 = yj[yj['品名']=='红尖椒']['最低价']
r3 = yj[yj['品名']=='红尖椒']['平均价']
r4 = yj[yj['品名']=='线椒']['最高价']
r5 = yj[yj['品名']=='线椒']['最低价']
r6 = yj[yj['品名']=='线椒']['平均价']
from pyecharts.charts import Line
from pyecharts.globals import ThemeType
c=(Line(init_opts=opts.InitOpts(theme=ThemeType.LIGHT)).add_xaxis(x)
.add_yaxis("红尖椒最高价",r1,is_smooth=True)#is_smooth平滑曲线
.add_yaxis("红尖椒最低价",r2,is_smooth=True)
.add_yaxis("红尖椒平均价",r3,is_smooth=True)
.add_yaxis("线椒最高价",r4,is_smooth=True)
.add_yaxis("线椒最低价",r5,is_smooth=True)
.add_yaxis("线椒平均价",r6,is_smooth=True)
.set_global_opts(title_opts=opts.TitleOpts(title="红尖椒和线椒的最高价、最低价、平均价随日期的变化趋势",pos_left="center",pos_top="3%")))
c.render_notebook()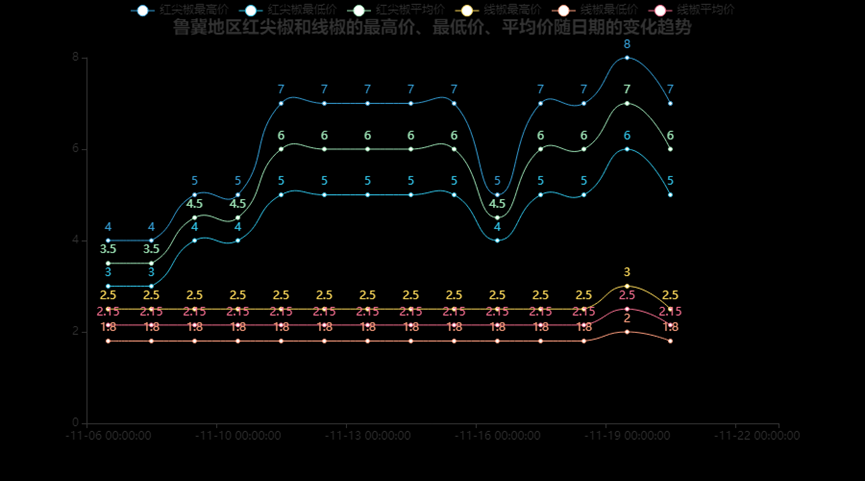
3.6.16、绘制最高价前40的品名的散点图
from pyecharts.charts import Scatter
data2 = pd.read_excel(r'爬取蔬菜相关信息.xlsx').astype(str)
w1 = data2.sort_values('最高价',ascending=False).head(40)
comment =w1['品名']
y = []
x = []
for i in comment.value_counts().index:
x.append(i)
for i in comment.value_counts():
y.append(i)
c = Scatter(opts.InitOpts(width = '660px',height = "380px"))
c.add_xaxis(x)#x轴
c.add_yaxis("品名",[list(z) for z in zip(y, x)],symbol_size=20)#加入与前面的一一对应
c.set_global_opts(title_opts=opts.TitleOpts(title="最高价前40的品名散点图"))
c.render_notebook()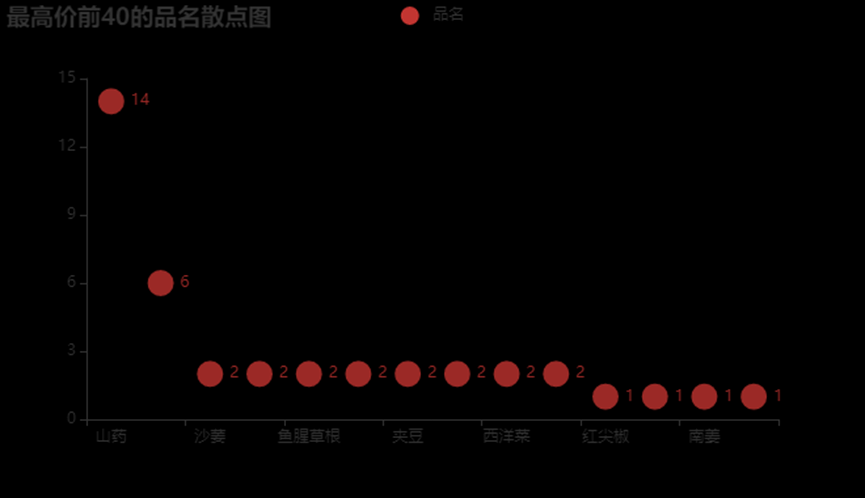
3.6.17“红尖椒”的最高价在全部时间的分布情况饼图展示
d3 = data1[data1['品名']=="红尖椒"]
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
d3['最高价'].value_counts()
a1=[]
for i in d3['最高价'].value_counts().index:
a1.append(i)
c = Pie(opts.InitOpts(width = '800px',height = '380px'))
c.add("",[list(z) for z in zip(a1,d3['最高价'].value_counts())],
rosetype="radius",radius=["20%", "40%"],center=["35%", "40%"],
label_opts=opts.LabelOpts(is_show=False),)
c.add("",[list(z) for z in zip(a1,d3['最高价'].value_counts())],
rosetype="area",radius=["20%", "40%"], center=["73%", "40%"])
c.set_global_opts(title_opts=opts.TitleOpts(title="红尖椒的最高价在全部时间的分布情况玫瑰图示"),
legend_opts=opts.LegendOpts(orient="vertical", pos_top="30%", pos_left="2%"))
#设置数据标签格式
c.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c},占比:{d}%"))
c.render_notebook()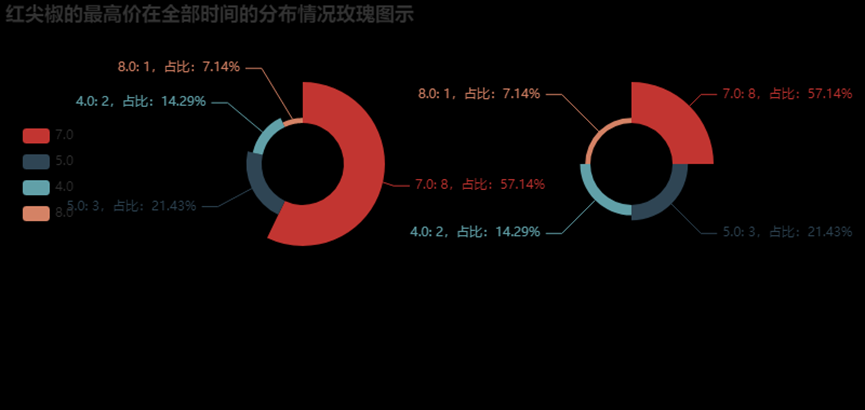
3.6.18、“番茄”的最高价在全部时间的变化情况折线图展示
d3 = data1[data1['品名']=="番茄"]
d4 = d3[d3['产地']=='蒙冀鲁'].sort_values('发布日期')
d5 = d3[d3['产地']=='蒙'].sort_values('发布日期')
a=[]
for i in d4['发布日期']:
a.append(i[5:10])
print(a)
b = d4['最高价']
e = d5['最高价']
y1=[]
for i in b:
y1.append(i)
y2=[]
for i in e:
y2.append(i)
from pyecharts.charts import Bar, Grid, Line
bar = ( Bar().add_xaxis(a).add_yaxis("蒙冀鲁",y1).add_yaxis("蒙",y2)
.set_global_opts(title_opts=opts.TitleOpts(title="番茄最高价随时间变化情况直方图展示")))
line = (Line().add_xaxis(a).add_yaxis("蒙", b).add_yaxis("蒙冀鲁", e)
.set_global_opts(title_opts=opts.TitleOpts(title="番茄最高价随时间变化情况折线图展示", pos_top="48%"),
legend_opts=opts.LegendOpts(pos_top="48%"),))
grid = (Grid().add(bar, grid_opts=opts.GridOpts(pos_bottom="60%"))
.add(line, grid_opts=opts.GridOpts(pos_top="60%"))
)
grid.render_notebook()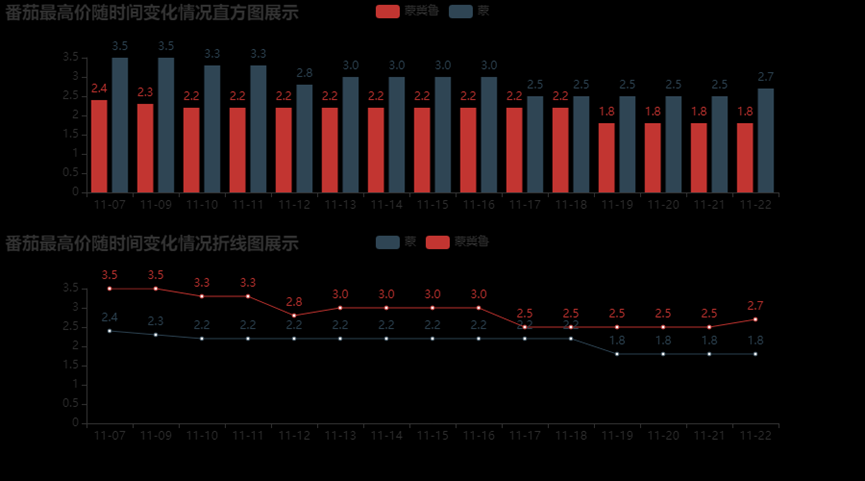
3.6.19、产地信息第200到1000条数据的蔬菜分布图
w2 = data1.sort_values('最低价',ascending=True).head(100)[200:1000]
y = []
x = []
for i in w2['品名'].value_counts().index:
x.append(i)
for i in w2['品名'].value_counts():
y.append(i)
bar1 = (Bar().add_xaxis(x).add_yaxis('个数', y)
.set_global_opts(title_opts=opts.TitleOpts("最低价排序前100的蔬菜分布图"),
yaxis_opts=opts.AxisOpts(name="个数"),
xaxis_opts=opts.AxisOpts(name="品名"))
)
bar1.render_notebook()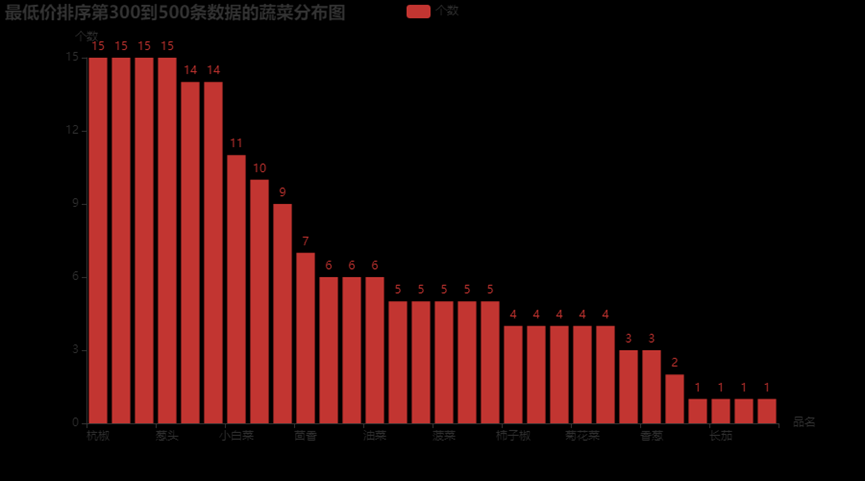
3.6.20、最低价排序第300到500条数据的蔬菜分布图
from pyecharts.charts import Funnel
w3 = data1.sort_values('最高价',ascending=True)[300:500]
y = []
x = []
for i in w3['产地'].value_counts().index:
x.append(i)
for i in w3['产地'].value_counts():
y.append(i)
wf = Funnel()
wf.add('产地最高价分布图',[list(z) for z in zip(x,y)],is_selected = True)
wf.render_notebook()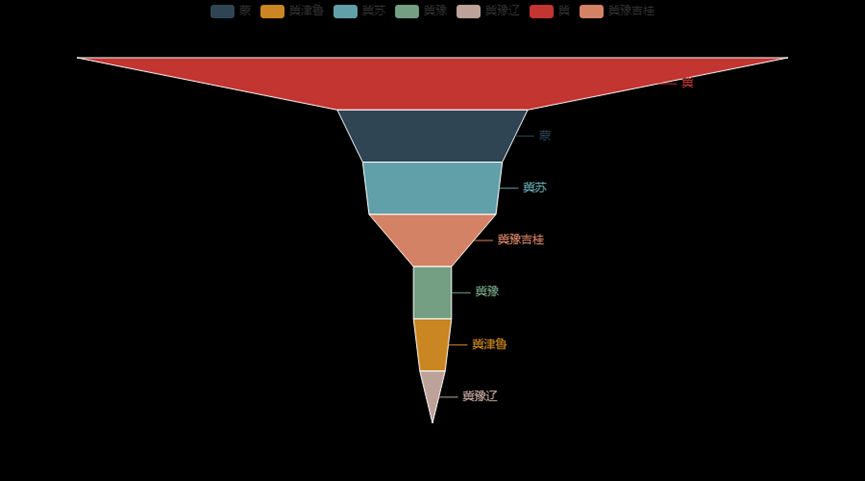
3.6.21、查看规格列各种类出现的次数,并且绘制节点图
from collections import Counter
Counter(df1['产地'])#绘制各省份蔬菜产地之间的关联关系
from pyecharts.charts import Graph
nodes_data = [
opts.GraphNode(name = '辽',symbol_size = 18),
opts.GraphNode(name = '京',symbol_size = 20),
opts.GraphNode(name = '冀',symbol_size = 15),
opts.GraphNode(name = '鲁',symbol_size = 30),
opts.GraphNode(name = '豫',symbol_size = 25),
opts.GraphNode(name = '云',symbol_size = 15),
opts.GraphNode(name = '蒙',symbol_size = 35),
opts.GraphNode(name = '苏',symbol_size = 20),
opts.GraphNode(name = '浙',symbol_size = 13),
]
links_data = [
opts.GraphLink(source = '辽',target = '鲁',value = 28),
opts.GraphLink(source = '辽',target = '冀',value = 13),
opts.GraphLink(source = '辽',target = '云',value = 15),
opts.GraphLink(source = '鲁',target = '辽',value = 14),
opts.GraphLink(source = '辽',target = '京',value = 11),
opts.GraphLink(source = '鲁',target = '京',value = 15),
opts.GraphLink(source = '京',target = '冀',value = 5),
opts.GraphLink(source = '京',target = '豫',value = 3),
opts.GraphLink(source = '冀',target = '辽',value = 44),
opts.GraphLink(source = '冀',target = '京',value = 45),
opts.GraphLink(source = '冀',target = '云',value = 18),
opts.GraphLink(source = '蒙',target = '冀',value = 16),
opts.GraphLink(source = '冀',target = '浙',value = 11),
opts.GraphLink(source = '鲁',target = '云',value = 25),
opts.GraphLink(source = '鲁',target = '辽',value = 14),
opts.GraphLink(source = '鲁',target = '冀',value = 13),
opts.GraphLink(source = '豫',target = '苏',value = 14),
opts.GraphLink(source = '云',target = '鲁',value = 10),
opts.GraphLink(source = '蒙',target = '冀',value = 16),
opts.GraphLink(source = '蒙',target = '鲁',value = 20),
]
c = Graph(init_opts = opts.InitOpts(width = '600px',height = '400px'))
c.add("",nodes_data,links_data,repulsion = 4500)
c.set_global_opts(title_opts = opts.TitleOpts(title = "Graph - Example"))
c.render_notebook()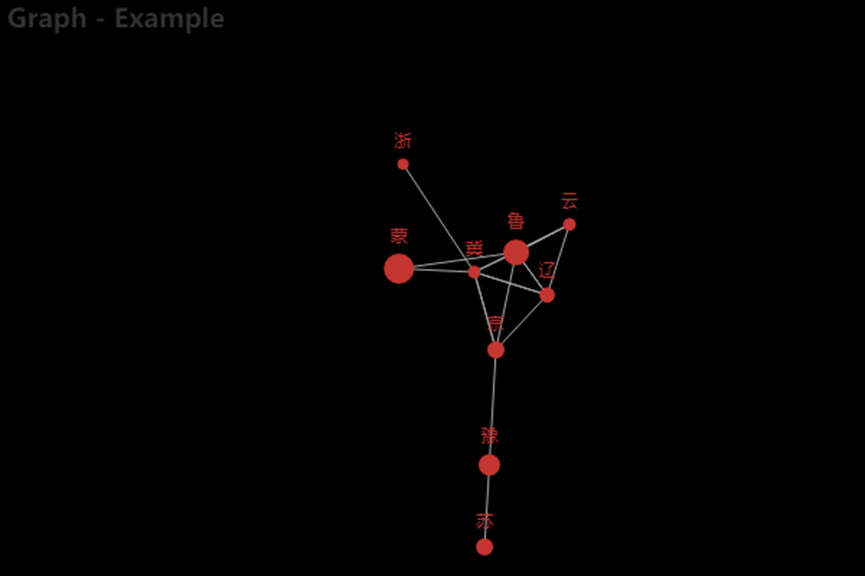
3.6.22、部分蔬菜产地路线和数量图
from pyecharts.charts import Geo
from pyecharts.globals import ChartType,SymbolType
c = (Geo(init_opts = opts.InitOpts(width = '600px',height = '400px'))
.add_schema(maptype = "china")#类型是中国
.add("蔬菜产地",[("山东",28),("天津",3),("北京",45),("云南",18),
("山东",58),("河南",14),("浙江",11),("辽宁",13)],
type_ = ChartType.EFFECT_SCATTER,color = "green")
.add("地方",[("辽宁","山东"),("云南","天津"),("河北","北京"),
("河北","云南"),("河北","山东"),("河北","河南"),
("河北","浙江"),("河北","辽宁")],
type_ = ChartType.LINES,
effect_opts = opts.EffectOpts(symbol = SymbolType.ARROW,symbol_size = 6,color = "blue"),
linestyle_opts = opts.LineStyleOpts(curve = 0.2))#设置曲度
.set_series_opts(label_opts = opts.LabelOpts(is_show = False))#去掉主要航线标签
.set_global_opts(title_opts = opts.TitleOpts(title = "部分蔬菜产地路线和数量")))
c.render_notebook()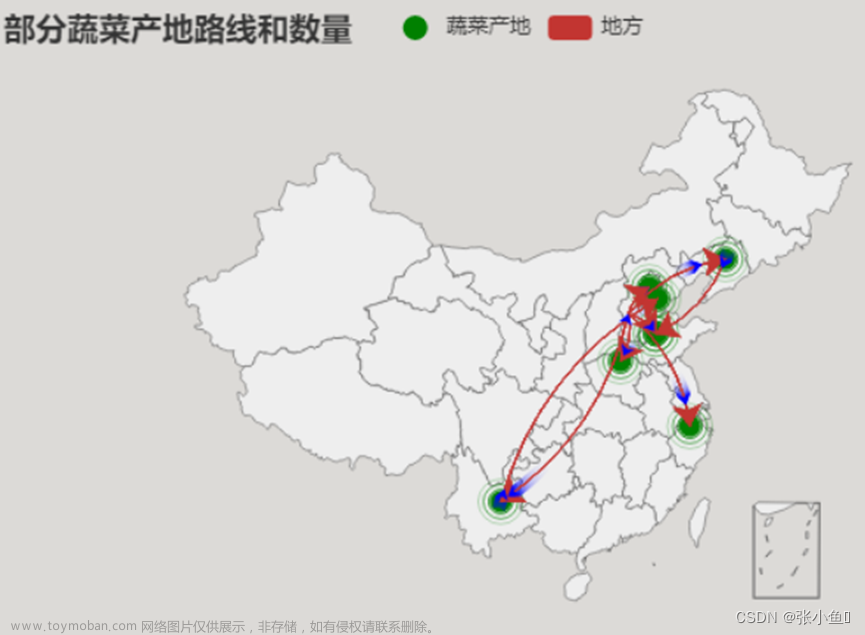
四、设计遇到的问题以及难点:
4.1关键技术与难点:
(1)、如何爬取大量数据且保证数据的有效性
(2)、数据处理的方法,相关函数的应用,图像的制作
(3)、选定所要制作图像的数据
(4)、对所得结果的综合性分析
4.2 处理数据与绘制图像
(1)、有些数据在使用时出来的图像效果不明显
解决方法:选择合适的数据进行分析
(2)、对一些方法的使用不够熟练,导致设计的程序一直不过
解决方法:在前面学习过的知识进行深入理解,在网络上查看博主写的相关函数参数介绍,正确使用之后程序调试通过
(3)、前期对于绘制怎样的图像没有头绪
解决方法:参考网络上博主的图形分析,以及所学绘图知识,慢慢搭建起自己的图形
(4)、最后完成数据分析之后,依旧觉得自己爬取分析的数据量有点少,应该在设计之前再多参考一下网上可以爬取的数据。
五、设计的总结与体会
在这次的课程设计当中,让我对于数据可视化这门课程有了更加深入的认识与理解,也真正体会到了数据可视化在生活当中的应用,真正体会到了什么是“一图胜千言”。用我们目前掌握的绘图库,可以绘制出来多种多样的图,让我影响深刻的图是漏斗图,饼图,词云,桑基图,玫瑰图,节点图,以及价格变化图,每张图都能一目了然的反映数据不能直接反映的问题。文章来源:https://www.toymoban.com/news/detail-480330.html
这次课程设计主要运用了我们本学期在数据可视化上学到的绘图与数据分析等模块,对于学到的知识应该学以致用,要不断的训练,才能更好地学习和掌握它。通过本次的课程设计,我也发现我还有许多不足之处。首先对一些函数的参数使用不熟练,以及数据的绘图方面还有一些欠缺的地方。我相信,通过这次的课程设计,我对于自己的欠缺知识有了更多的发现,我会在以后的学习中不断完善自己的编程能力。文章来源地址https://www.toymoban.com/news/detail-480330.html
到了这里,关于数据可视化课程设计——北京新发地官网数据分析与可视化展示【内容在jupyter notebook里面展示】包含数据爬取与可视化分析详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!