背景介绍
Netflix是最受欢迎的媒体和视频流平台之一。他们的平台上有超过 8000 部电影或电视节目。截至 2021 年年中,他们在全球拥有超过 2 亿订阅者。
博主看美剧也较为多,像《怪奇物语》、《性爱自修室》等高分美剧都是网飞的。
对于网飞的影视剧,我们可以分析其电影和电视剧的成分占比,发行年份、国家,影视剧类型,收视率,简介关键词等,进行一定程度的描述性统计及其可视化。从而可以得到哪些类型影视剧更受欢迎,哪些国家发行影视剧更多等等结论。
注:(本文不涉及高级复杂的数学模型,主要的核心是数据的描述性分析和可视化。)
关于数据集介绍
此表格数据集来源kaggle,包含 Netflix 上可用的所有电影和电视节目的列表,以及演员、导演、评级、发行年份、持续时间等详细信息。
不方便的同学可以参考这个获取数据集:网飞数据。
数据读取和清洗
导入数据分析常用的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号下面读取数据集转化为pandas数据框对象,删除所有值都为空白的列,把第一列节目标号设置为索引,查看数据前五行
df=pd.read_csv('netflix_titles.csv',encoding='ANSI').dropna(how='all',axis=1).set_index('show_id')
df.head()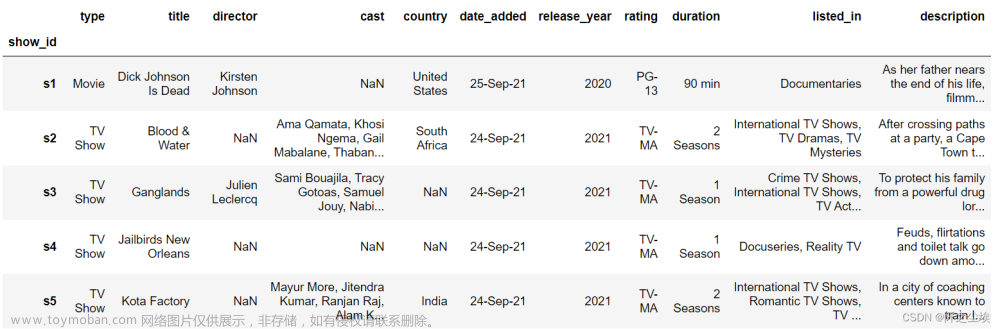
可以看到主要都是文本类型数据。
数据变量介绍和分析
变量信息介绍
‘type’为影视剧类型,即属于电影还是电视剧,分类型变量
‘title’为影视剧名称,文本型变量
‘director' 为导演名字,文本变量
‘cast’为所有演员名称,文本变量
‘ country’为发行制作国家,分类变量
‘date_added’该影视剧在 Netflix 上添加的日期,时间变量
‘release_year’该影视剧实际发布年份,时间变量
‘rating’电影/节目的电视评级,分类变量
‘duration’总持续时间, 分类变量
‘listed_in’影视剧节目类型,多组分类变量
‘description’影视剧简介,文本变量
查看数据的所有变量信息
df=df.infer_objects()
print(df.shape)
df.info()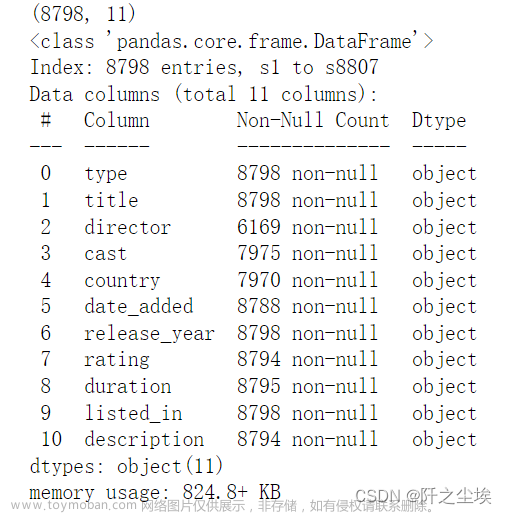
从上面数据信息可以看到该数据总共有8798条,11个变量, 有些变量存在一定的缺失值,下面对缺失值进行处理,
数据清洗
对缺失值进行可视化
#观察缺失值
import missingno as msno
msno.matrix(df)
可以看出导演这一列出现缺失值较多,演员和发行国家也存在一些缺失值。 由于每个影视剧的导演和演员都是第一无二的,而且是文本型数据,所以这里不能采用均值或者是众数进行填充,我们使用‘无数据’代替空值。
发行国家采用已有数据里面发行影视剧最多的国家进行填充, 其他列存在缺失值的样本可以进行删除。
填充修改
df['country'] = df['country'].fillna(df['country'].mode()[0])
df['cast'].fillna('No Data',inplace = True)
df['director'].fillna('No Data',inplace = True)
df.dropna(inplace=True)去除重复值
df.drop_duplicates(inplace=True)将时间变量转化为时间格式
便于后面分析,这里将影视剧添加到网飞版块时间的年月作为分类变量提取出来
df["date_added"] = pd.to_datetime(df['date_added'])
df['year_added'] = df['date_added'].dt.year
df['month_name_added']=df['date_added'].dt.month_name()
df['release_year']=df['release_year'].astype('int')再次查看数据信息
df.info()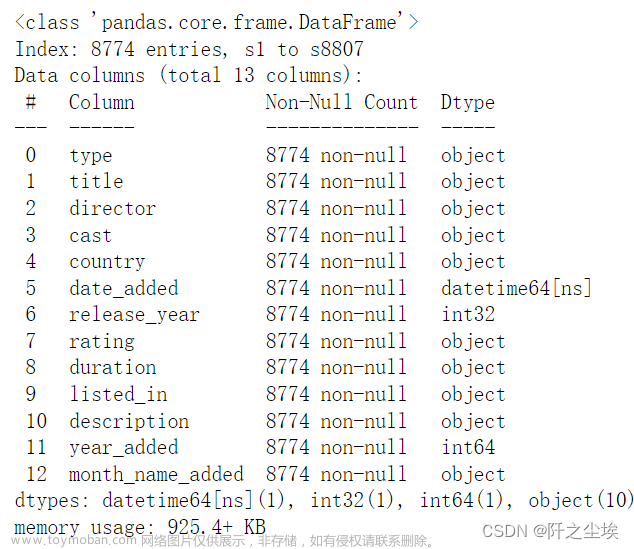
最终剩余8774条样本数据,变量都无缺失值,变量类型都正确,可以进行下面的分析和可视化
分析及其可视化
网飞影视剧中电影和电视剧的各自占比分析
plt.figure(figsize=(2,2),dpi=180)
p1=df.type.value_counts()
plt.pie(p1,labels=p1.index,autopct="%1.3f%%",shadow=True,explode=(0.2,0),colors=['royalblue','pink']) #带阴影,某一块里中心的距离
plt.title("网飞影视剧中电影和电视剧的各自占比")
plt.show()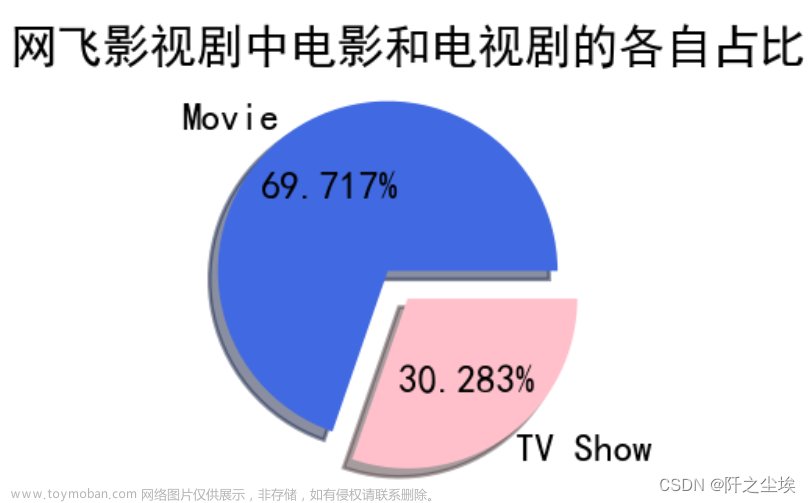
可以看出网飞影视剧中电影数量占比更多,将近七层,电视剧占比30%左右。
网飞影视剧中发行国家分析
import squarify
p2=df.country.value_counts()[:15]
fig = plt.figure(figsize = (8,4),dpi=256)
ax = fig.add_subplot(111)
plot = squarify.plot(sizes = p2, # 方块面积大小
label = p2.index, # 指定标签
#color = colors, # 指定自定义颜色
alpha = 0.8, # 指定透明度
value = p2, # 添加数值标签
edgecolor = 'white', # 设置边界框
linewidth =0.1 # 设置边框宽度
)
# 设置标题大小
ax.set_title('网飞影视剧数量发行量排名前15的国家',fontsize = 22)
# 去除坐标轴
ax.axis('off')
# 去除上边框和右边框刻度
ax.tick_params(top = 'off', right = 'off')
# 显示图形
plt.show()
可以看到,由于网飞是美国的公司,在其本土上的影视作品数量最多,几乎占据了所有影视作品的一半,其次是印度、英国、日本、韩国、加拿大,这五个国家的网飞影视剧也较多。
(只选取了前15的国家,因为国家太多了图就会很乱)
网飞影视剧发行量前10的国家电影和电视剧数量对比分析
def check0(txt):
if txt in p2.index[:10]:
a=True
else:
a=False
return a
df_bool=df.country.astype('str').apply(check0)p3=pd.crosstab(df[df_bool].type,df[df_bool].country,normalize='columns').T.sort_values(by='TV Show')
m =np.arange(len(p3))
plt.figure(figsize = (8,4),dpi=256)
plt.bar(x=m, height=p3.iloc[:,0], label=p3.columns[0], width=0.3,alpha=0.5, hatch='.',color='orange')
plt.bar(x=m , height=p3.iloc[:,1], label=p3.columns[1], bottom=p3.iloc[:,0],width=0.3,alpha=0.5,hatch='*',color='lime')
plt.xticks(range(len(p3)),p3.index,fontsize=10,rotation=30)
plt.legend()
plt.ylabel('频率')
plt.title("网飞影视剧发行量前10的国家电影和电视剧数量对比")
plt.show()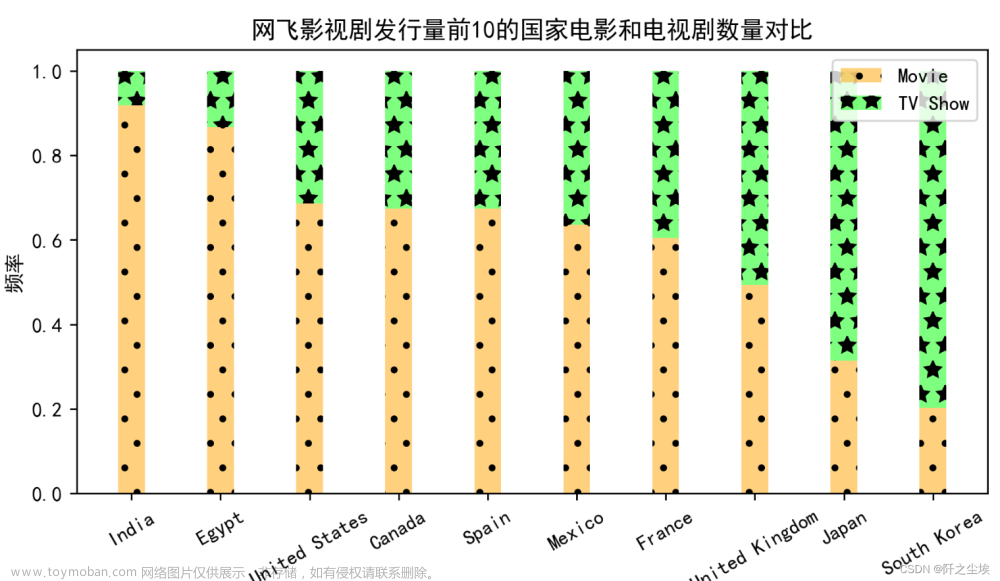
从网飞发行量前十的国家来看,印度的网飞影视剧的电影占比非常高,其次是埃及,美国。
电视剧占比较高的是韩国、日本、英国。
说明网飞在印度,埃及,美国地区制作拍摄影视剧是更偏向与电影。而在韩国,日本,英国更偏向于电视剧发行。
(只选取了前10的国家,因为国家太多了图就会很乱,国家名称都堆叠在一起放不下去)
影视剧评级分析
p4=df.rating.value_counts()
plt.figure(figsize = (6,3),dpi=256)
sns.barplot(x=p4.index,y=p4)
plt.ylabel('数量')
plt.xlabel('评价')
plt.xticks(fontsize=10,rotation=45)
plt.title("网飞所有影视剧不同评级数量对比")
plt.show()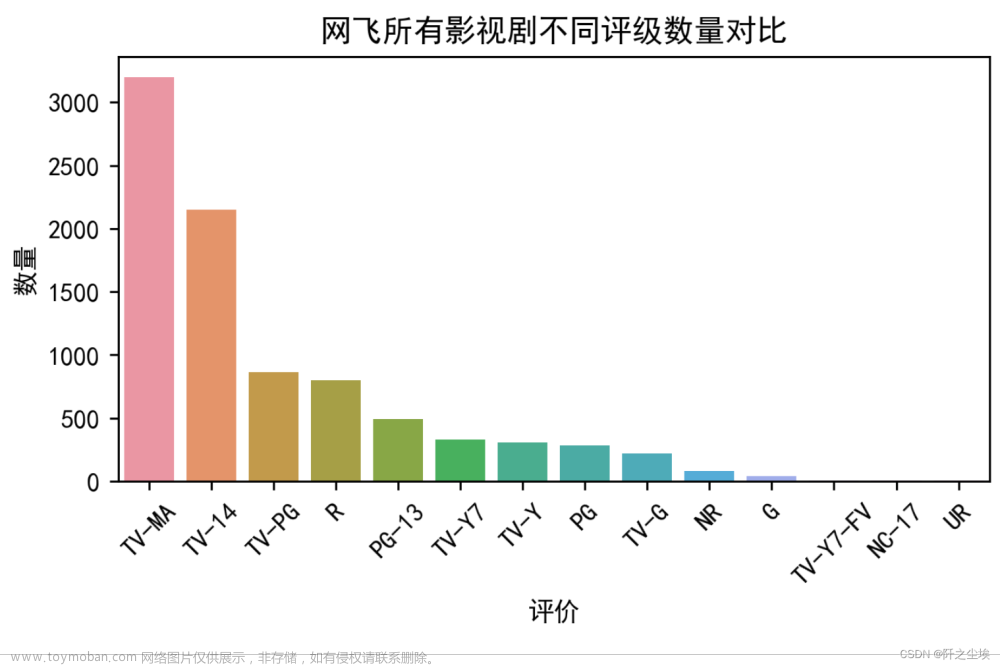
可以看到绝大多数的评价都是TV-MA和TV-14,即适合成年人的影视剧和合适14岁以上影视剧的评级。
df_bar=pd.crosstab(df.type,df.rating).T.sort_values(by='Movie',ascending=False).unstack().reset_index().rename(columns={0:'number'})
plt.subplots(figsize = (10,4),dpi=128)
sns.barplot(x=df_bar.rating,y=df_bar.number,hue=df_bar.type,palette = "copper")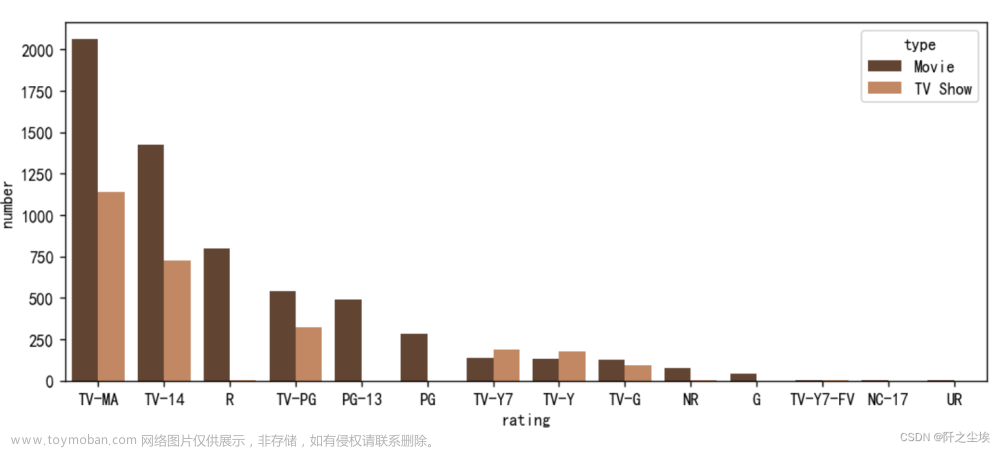
可以看到评级是TV-MA,TV-14和TV-PG的电影和电视剧都有,评级为R和PG的都是电影。
不同发行国家的影视剧评级分析
df_heatmap=df[df_bool].groupby('country')['rating'].value_counts().unstack().sort_index().fillna(0).astype(int).T#.sort_values(by='Movie',ascending=False).T
for col in df_heatmap.columns:
df_heatmap[col]=df_heatmap[col]/df_heatmap[col].sum()
corr = plt.subplots(figsize = (8,6),dpi=256)
corr= sns.heatmap(df_heatmap,annot=True,square=True,annot_kws={'size':6,'weight':'bold', 'color':'royalblue'},fmt='.2f',cmap='cubehelix_r')
plt.title('不同发行国家的网飞影视剧评级对比')
plt.show()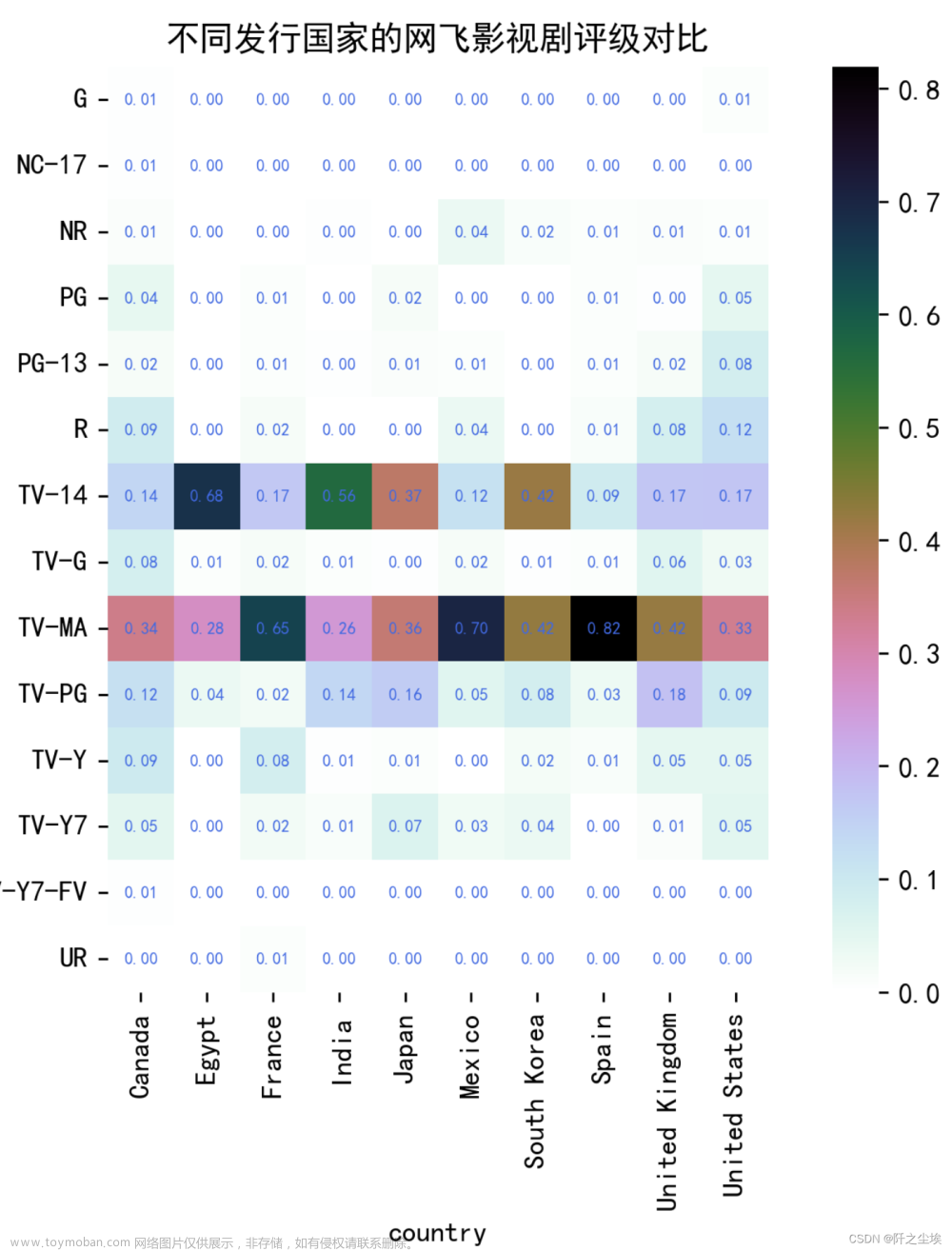
从上图可以直观的看出绝大多数的网飞影视剧评级都是TV-MA和TV-14,这与前面的结论一致。
从不同发行国家的角度来看,加拿大,法国,墨西哥,西班牙,英国,美国制作发行的网飞影视剧数量更多偏向于适合成年人观看的。
埃及、印度、日本、韩国制作发行的网飞影视剧有较大的频率被评价为适合14岁以上观看的。
这与传统观念一致,欧美等西方国家的影视剧会更加开放一点,而印度日本韩国亚洲国家的影视剧则会更加保守一点。
影视剧上映年份分析
plt.figure(figsize=(8,3.5),dpi=128)
colors=['tomato','orange','royalblue','lime','pink']
for i, mtv in enumerate(df['type'].value_counts().index):
mtv_rel = df[df['type']==mtv]['year_added'].value_counts().sort_index()
plt.plot(mtv_rel.index, mtv_rel, color=colors[i], label=mtv)
plt.fill_between(mtv_rel.index, 0, mtv_rel, color=colors[i], alpha=0.8)
plt.legend()
plt.ylabel('网飞发行影视剧数量')
plt.xlabel('年份')
plt.title('网飞在不同年份上映影视剧数量')
plt.show()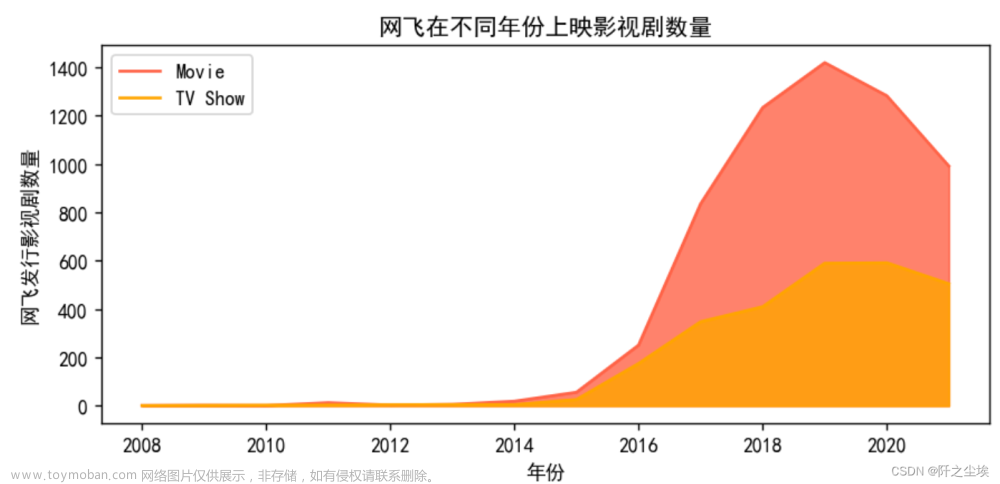
可以看出网飞从2014年开始,影视剧数量开始达到一个爆发式的增长状况,尤其在2019年上映的影视剧作品最多。
19年之后受到疫情等影响上映影视作品数量又呈现慢慢下降趋势。
影视剧上映月份分析
plt.figure(figsize=(5,5),dpi=128)
colors=['tomato','orange','royalblue','lime','pink','brown']
p5=df.month_name_added.value_counts()
plt.pie(p5,labels=p5.index,autopct="%1.3f%%",shadow=True,explode=(0.2,0.1,0.08,0.06,0.04,0.02,0,0,0,0,0,0),colors=colors) #带阴影,某一块里中心的距离
plt.title('网飞影视剧上映月份分析')
plt.show()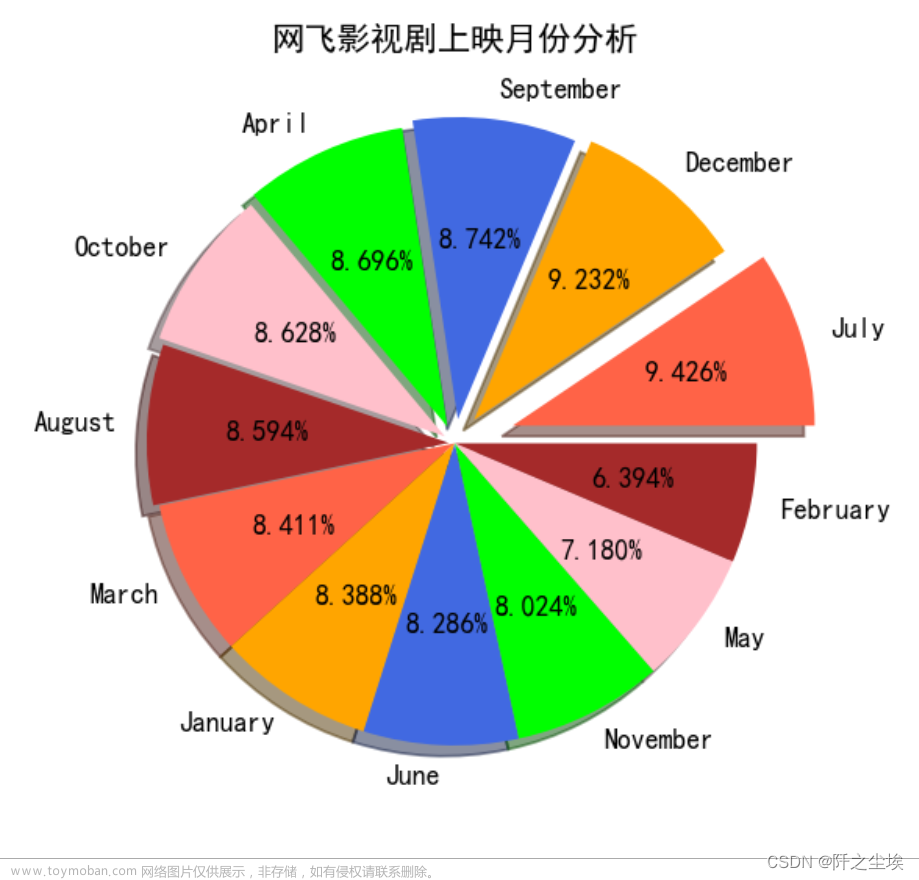
可以看出网飞影视剧数量上映的月份较为均匀,其中七月和十二月上映的电视剧较多,正好也对应了西方的暑假和寒假,假期上映电视剧较多。
上映影视剧最少的是二月和三月。
上映影视剧的年龄分析
df_age=df.assign(age=df.year_added-df.release_year)[['type','age']]
plt.figure(figsize=(3,4),dpi=128)
sns.boxplot(x='type',y='age',width=0.8,data=df_age,orient="v")
plt.show()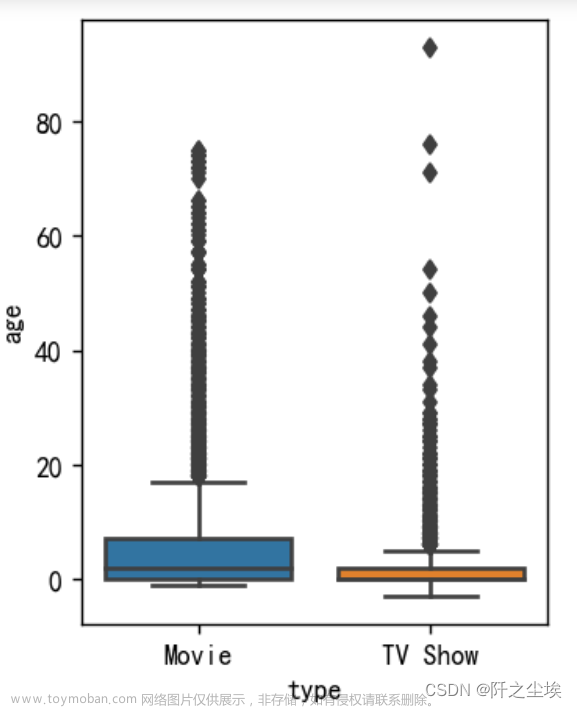
可以看出绝大部分的电影或是电视剧的上映时间和发行时间相差不大,中位数在2到3年左右,电影会稍微偏大点,这也反应了好电影比电视剧能一直流传的特点
电影电视剧的异常值都较多,极大值偏多,主要可能是网飞上映收录了不少以前的经典电视剧和电影。
影视剧类型分析
p6=df.assign(kind=df.listed_in.str.split(',')).explode('kind')['kind'].value_counts()[:15]
plt.figure(figsize=(10,4),dpi=128)
sns.barplot(y=p6.index,x=p6,orient="h")
plt.xlabel('影片数量')
plt.ylabel('影视剧类型')
plt.xticks(fontsize=10,rotation=45)
plt.title("网飞不同影视剧类型数量对比")
plt.show()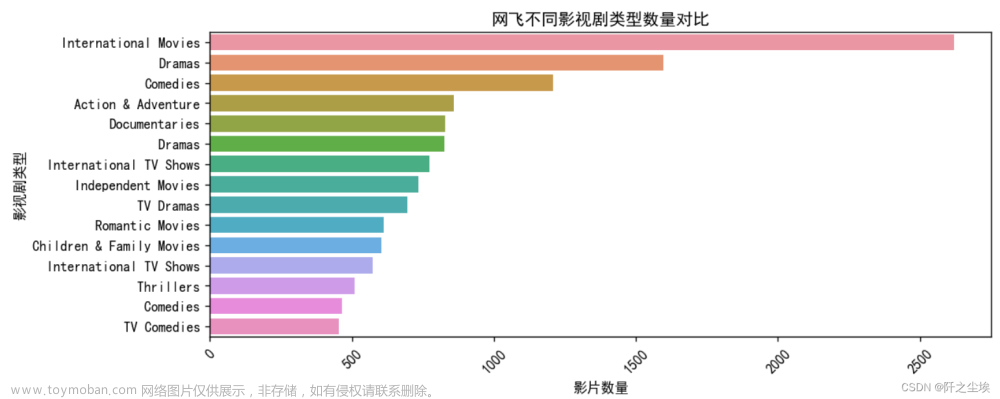
可以看清楚的看到网飞的影视剧最多的类型是国际电影,然后是戏剧,喜剧,动作冒险片,纪录片
只看美国的影视剧类型
p7=df.assign(kind=df.listed_in.str.split(',')).explode('kind').where(lambda d:d.country=='United States').dropna()['kind'].value_counts()[:12]
plt.figure(figsize=(5,5),dpi=128)
plt.pie(p7,labels=p7.index,autopct="%1.2f%%",shadow=True,explode=(0.15,0.1,0.08,0.06,0.04,0.02,0,0,0,0,0,0),colors=['c', 'b', 'g', 'tomato', 'm', 'y', 'lime', 'w','orange','pink','grey','tan'])
plt.title('在美国制作发行的网飞影视剧类型数量对比')
plt.show()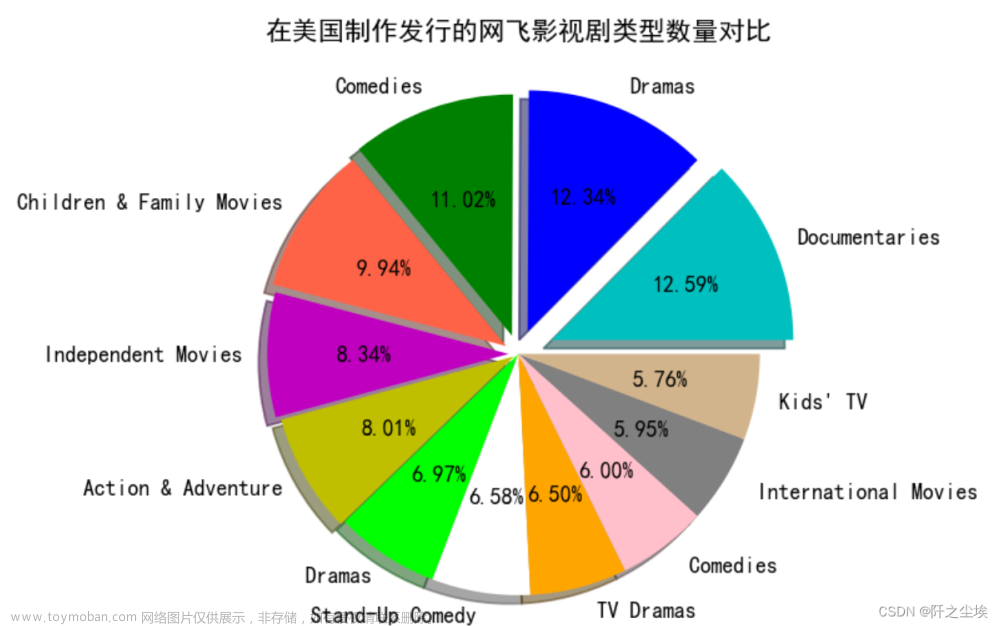
从上饼图得知在美国网飞上映的影视剧中,纪录片类型的最多,其次是戏剧,喜剧,家庭片,独立电影等。
网飞影视剧的导演和演员分析
p8=df.assign(directo=df.director.str.split(',')).explode('directo')['directo'].value_counts()[1:11]
p9=df.assign(cas=df.cast.str.split(',')).explode('cas')['cas'].value_counts()[1:11]
plt.subplots(1,2,figsize=(12,5),dpi=128)
plt.subplot(121)
sns.barplot(y=p8.index,x=p8,orient="h")
plt.ylabel('导演姓名')
plt.xlabel('导演影视剧的数量',fontsize=14)
plt.title("(a)网飞影视剧导演数量前十的导演")
plt.subplot(122)
sns.barplot(y=p9.index,x=p9,orient="h")
plt.ylabel('演员名字')
plt.xlabel('出演影视剧的数量',fontsize=14)
plt.title("(b)网飞影视剧出演数量前十的演员")
#plt.legend()
plt.tight_layout()
plt.show()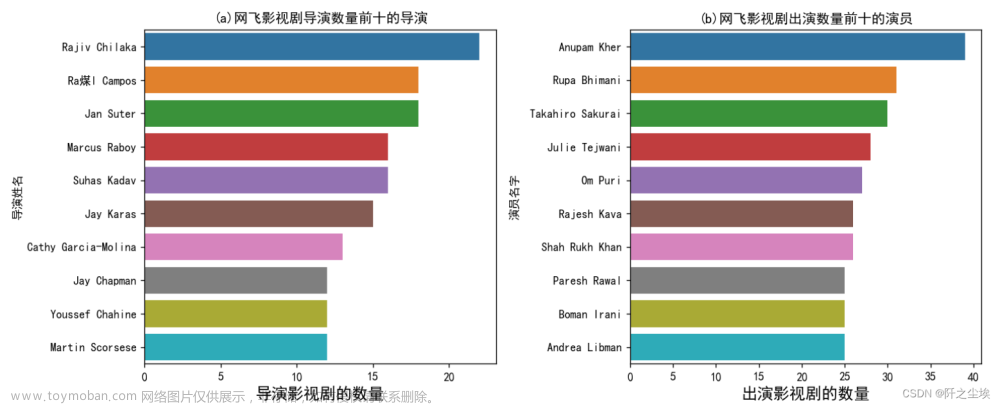
从上图得知网飞的影视剧数量前十名的导演,和出演数量前十名的演员。(只能看到名字我也不认识他们.....) ((只选取了前10,因为人名太多了图就会显得很乱))
网飞的影视剧名称的词云图
背景使用网飞的logo

from wordcloud import WordCloud
import random
from PIL import Image
import matplotlib
# Custom colour map based on Netflix palette
mask = np.array(Image.open('wf.png'))
cmap = matplotlib.colors.LinearSegmentedColormap.from_list("", ['#221f1f', '#b20710'])
text = str(list(df['title'])).replace(',', '').replace('[', '').replace("'", '').replace(']', '').replace('.', '')
wordcloud = WordCloud(background_color = 'white', width = 500, height = 200,colormap=cmap, max_words = 150, mask = mask).generate(text)
plt.figure( figsize=(9,5),dpi=1028)
plt.imshow(wordcloud, interpolation = 'bilinear')
plt.axis('off')
plt.tight_layout(pad=0)
plt.show() 
可以看到网飞影视剧标题用词数量最高的是'LOVE','World','Day','Life','Girl'等词汇。
网飞的影视剧简介的词云图
text2=str(list(df['description'])).replace(',', '').replace('[', '').replace("'", '').replace(']', '').replace('.', '')
wordcloud = WordCloud(background_color = 'white', width = 500, height = 200,colormap='coolwarm', max_words =30).generate(text2)
plt.figure( figsize=(8,4),dpi=512)
plt.imshow(wordcloud, interpolation = 'bilinear')
plt.axis('off')
plt.tight_layout(pad=0)
plt.show()
可以看到网飞影视剧简介用词频率最高的是'life','family','love','find','new'等词汇。
总结
通过分析网飞的八千多部影视剧的数据,我们能得到如下的一些结论:
1、网飞影视剧中电影数量占比更多,将近七层,电视剧占比30%左右
2、由于网飞是美国的公司,在其本土上的影视作品数量最多,几乎占据了网飞所有影视作品的一半, 其次是印度、英国、日本、韩国、加拿大,这五个国家的网飞影视剧也较多。
3、网飞在印度,埃及,美国地区制作拍摄影视剧是更偏向与电影。而在韩国,日本,英国更偏向于电视剧发行。
4、网飞绝大多数的影视剧评级都是TV-MA和TV-14,即适合成年人的影视剧和合适14岁以上影视剧的评级。
5、网飞影视剧的发行国家和影视剧的评级有关,欧美等西方国家的影视剧会更加开放一点,而印度日本韩国亚洲国家的影视剧则会更加保守一点。
6、2014年开始,影视剧数量开始达到一个爆发式的增长状况,尤其在2019年上映的影视剧作品最多。19年之后受到疫情等影响上映影视作品数量又呈现慢慢下降趋势。
7、网飞影视剧数量上映的月份较为均匀,其中七月和十二月上映的电视剧较多,正好也对应了西方的暑假和寒假,假期上映电视剧较多。上映影视剧最少的是二月和三月。
8、网飞的大部分的电影或是电视剧的上映时间和发行时间相差不大,电影会稍微偏大点,反应了好电影比电视剧能一直流传的特点。电影电视剧的异常值都较多,极大值偏多,主要可能是网飞上映收录了不少以前的经典电视剧和电影
9、网飞的影视剧最多的类型是国际电影,然后是戏剧,喜剧,动作冒险片,纪录片。
10、在美国网飞上映的影视剧中,纪录片类型的最多,其次是戏剧,喜剧,家庭片,独立电影等。
11、得知网飞的影视剧数量前十名的导演,和出演数量前十名的演员。
12、网飞影视剧标题用词数量最高的是'LOVE','World','Day','Life','Girl'等词汇。
13、网飞影视剧简介用词频率最高的是'life','family','love','find','new'等词汇
本文由于没有用很复杂的数学模型,得到的结论不算很高级,但是也很有效有意义了。excel可做不出来这效果...大家可以核心地学学这些画图的方法吧,毕竟漂亮的图像和有效地结论才是可视化的意义。文章来源:https://www.toymoban.com/news/detail-480377.html
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制代码可私信)文章来源地址https://www.toymoban.com/news/detail-480377.html
到了这里,关于Python数据分析案例12——网飞影视剧数据分析及其可视化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!