数据库的三个阶段:人工管理阶段、文件系统阶段、数据库系统阶段
数据库管理系统:DBMS
常见的关系型数据库:Oracle、DB2、mysql
常见的非关系型数据库:MongoDB、redies
sql的四部分:
DML(update、delete、insert)
DDL(create、drop、alter、truncate)
DQL(select查询语句)
DCL(对数据进行变更)
MySQL数据库的常见操作:
查看所有数据库:show databases;
查看以a开头的数据库:show databases like 'a%';
创建数据库:create database if not exists 数据库名;
删除数据库:drop database if exists 数据库名;
注:在数据库的语法规定里是不区分大小写,但通常关键字大写,数据库名、表名、字段名小写。
查询数据:
提示:使用select语句进行查询数据,语法格式如下
SELECT
{* | <字段列名>}
[
FROM <表 1>, <表 2>…
[WHERE <表达式>
[GROUP BY <group by definition>
[HAVING <expression> [{<operator> <expression>}…]]
[ORDER BY <order by definition>]
[LIMIT[<offset>,] <row count>]
]
下面我们来分条解析使用select 的语法格式:
-
{*|<字段列名>}包含星号通配符的字段列表,表示所要查询字段的名称。 -
<表 1>,<表 2>…,表 1 和表 2 表示查询数据的来源,可以是单个或多个。 -
WHERE <表达式>是可选项,如果选择该项,将限定查询数据必须满足该查询条件。 -
GROUP BY< 字段 >,该子句告诉 MySQL 如何显示查询出来的数据,并按照指定的字段分组。 -
[ORDER BY< 字段 >],该子句告诉 MySQL 按什么样的顺序显示查询出来的数据,可以进行的排序有升序(ASC)和降序(DESC),默认情况下是升序。 -
[LIMIT[<offset>,]<row count>],该子句告诉 MySQL 每次显示查询出来的数据条数
查询表中所有字段或指定字段,字段去重distinct
所有字段:
- 使用“*”通配符查询所有字段,语法格式:SELECT * FROM 表名; 给所有的字段内容去重在*前面加distinct即可。
- 在select后面列出表的所有字段名,用 英文的逗号 , 分隔开。 在第一个字段名前面加distinct即可。
指定字段:
- 在select后跟指定字段名称即可;去重在字段名前加distinct。
表名很长时,可以在标明后面 通过 AS 关键字 为表指定一个别名;字段也是 语法一样,可以给字段也指定别名。
表名 AS 别名;
字段名 AS 别名;limit:可以限制文件的输出条数和输出位置
LIMIT 初始位置,输出条数 --下表是从0开始LIMIT 输出条数 --默认从第一条开始LIMIT 输出条数 OFFSET 初始位置order by:对查询结果通过某一字段排序(可以通过字段名排序)
ORDER BY <字段名> [ASC|DESC] --ASC是默认的升序的 如果不写,默认ASC , desc是降序where 条件查询语句
- 带比较运算符和逻辑运算符的查询条件
- 带 BETWEEN AND OR关键字的查询条件
- 带 IS NULL 关键字的查询条件
- 带 IN 关键字的查询条件
- 带 LIKE 关键字的查询条件
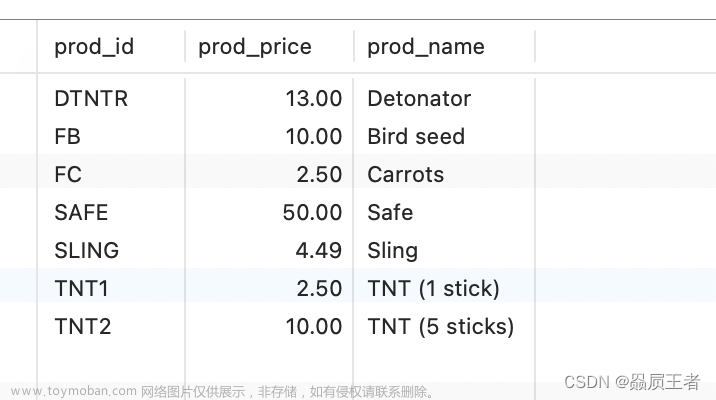
--查询日本2018年的电影
SELECT * FROM 表名
WHERE 字段名='日本'AND 字段名='2018';--查询在 xian上映或者在中国大陆上映且类型为喜剧/奇幻/古装的影片信息
SELECT * FROM cinema_later
WHERE city='xian'OR (region='中国大陆'AND tag='喜剧/奇幻/古装');--模糊查询
--查询以人结尾,前面有任意字符的title
SELECT *FROM cinema_later
WHERE title LIKE '%人';
--查询包含有人字的title
SELECT * FROM cinema_later
WHERE title LIKE '%人%';
--查询人字前面有固定字符(两个下划线表示),但以任意字符结尾的
SELECT * FROM cinema_later
WHERE title LIKE '__人%';
--默认不区分 加binary按照区分大小写字母查询,
SELECT * FROM cinema_later
WHERE city LIKE BINARY 'C%';--范围区间查询between
-- 5000到8000之间,且上映城市为xian的
SELECT * FROM cinema_later
WHERE (wish_count BETWEEN 5000 and 8000)AND city='xian';--查询英文片名为null的影片
SELECT * FROM north_american_box_office
WHERE yingwenpianming IS NULL
--查询英文片名不为null的影片
SELECT * FROM north_american_box_office
WHERE yingwenpianming IS not NULL--查询当日票房为100或200或300的
SELECT *FROM north_american_box_office
WHERE dangripiaofang IN(100,200,300);group by 分组
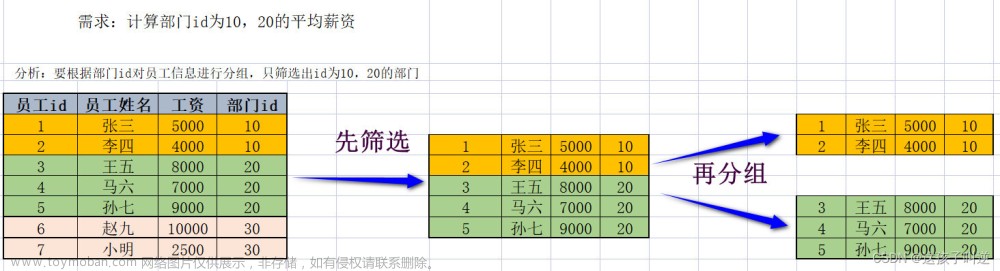
group by单独使用时,后面跟字段名即可。GROUP BY 关键字也可以和 GROUP_CONCAT() 函数一起使用。这样可以把分组的某一字段的每个字段值都显示。
SELECT 分组的字段名, GROUP_CONCAT(传入需要全部显示的字段名)
FROM 表名
GROUP BY 分组的字段名;在数据统计时,GROUP BY 关键字经常和聚合函数一起使用。聚合函数包括: COUNT(),SUM(),AVG(),MAX() 和 MIN()。
-
COUNT()用来统计记录的条数; -
SUM()用来计算字段值的总和; -
AVG()用来计算字段值的平均值; -
MAX()用来查询字段的最大值; -
MIN()用来查询字段的最小值。
SELECT sex,COUNT(sex) FROM tb_students_info GROUP BY sex; --统计指定的字段的数量WITH POLLUP 关键字用来在打印所有分组记录的最后加上一条记录,这条记录是上面所有记录的总和,即统计记录数量。 GROUP BY sex WITH ROLLUP;
having 可以用来过滤分组的一些信息,类似where,支持where里所有的操作。但也有差异
- where用于过滤数据行,having用于过滤分组
- where查询不可以使用聚合函数,having可以使用聚合函数。
- where语句是在分组前进行过滤,而having是在分组后进行过滤。
- where是根据数据库文件过滤,而having是根据查询结果进行过滤。(having查询的结果必须select有查询)
- where查询中不可以使用字段别名,但having可以使用字段别名。
表连接:
表连接分为三种:交叉连接、内连接、外连接
交叉连接相当于两个表的笛卡尔积,和内连接不加过滤条件是一样的效果。交叉用的较少,因为效率不高。使用的关键字是cross join 也可以省略。使用语法如下
SELECT <字段名> FROM <表1> CROSS JOIN <表2> [WHERE子句]
或者
SELECT <字段名> FROM <表1>, <表2> [WHERE子句] 内连接:通过关键字inner join 来连接两张表。再通过on来设置内连条件(通过条件来连接对应的数据行,有对应匹配关系),如果不加on设置条件,则也相当于计算两个表的笛卡尔积。且多个表连接时,在from后面继续使用inner join on即可实现多表连接。
SELECT *
FROM resource AS b
INNER JOIN resource_type AS a
ON a.type_id=b.resource_type--多表查询
SELECT *
FROM material_record_info AS a
INNER JOIN material_info AS b1
ON a.m_id=b1.material_id
INNER JOIN user_info AS b2
ON a.u_id=b2.user_id外连接: 外连接会先将表分为基表和参考表,再以基表为依据返回满足和不满足条件的记录,外连接分为左连接和右连接。
左外连接和右外连接的区别是:左外连接即基表在关键字left outer join的左边,右外连接基表在关键字left outer join的右边。
那么基表有什么意义和作用呢?就是在进行条件匹配时,基表没有匹配到对应数据的数据行也会被返回,在没有匹配到对应数据的行里用null来填充。简单来说就是基表的所有数据行均会被返回。
外连接的使用语法和内连接很类似,只是在关键字前加了限定词left或者right
SELECT *
FROM resource_type AS a
LEFT OUTER JOIN resource AS b
ON a.type_id=b.resource_type子查询:
子查询也可以实现类似于表连接的多表查询,但也有区别,子查询是将一个查询语句嵌套在另一条查询语句里。其中,连接子查询的操作符可以是 in、not in、exists、not exists等关键字。子查询可以在select、update、delete里使用。
--查大于80分的教师信息 子查询
SELECT *
FROM teacher AS t
INNER JOIN course AS c
ON t.t_id=c.t_id
WHERE c.c_id IN(
SELECT c_id
from score student_db
GROUP BY c_id
HAVING AVG(score>80)
)-- exists:如果符合条件,外集合返回表所有内容;加上and判断条件,就只返回符合两个条件的信息
SELECT *
FROM user_info AS a
WHERE EXISTS(
SELECT *
FROM material_record_info as b
WHERE b.u_id=7
)AND user_id=7;子查询和表连接的区别:
一般来说,表连接都可以用子查询来替代,反之不然,有点子查询不能用表连接替换。子查询比较灵活,直观,会使sql语句更容易阅读和编写,适合用于筛选数据。而表连接更适合查看数据表的连接。
select查询语句的执行顺序:
除了select查询语句的语法顺序我们需要掌握,select语句在内存的执行顺序我们也需要掌握。大题一共可以分为10步:文章来源:https://www.toymoban.com/news/detail-480544.html
- From:计算两个表的笛卡尔积,都到一个虚拟表V1,这是所有select语句最先执行的操作,其操作都需要在V1的基础上。
- On:从V1中筛选出符合条件的数据,形成虚拟表V2。
- Join:将该join的数据补充到V2,形成V3。
- Where:执行筛选(不能使用聚合函数),得到V4。
- Group By:对数据进行分组,得到V5.
- Having:对分组后的数据进行筛选(可以用聚合函数),筛选结果为V6。
- Select:得到返回列的数据V7。
- Distinct:去重,过滤掉重复数据,得到V8。
- Order By:排序,得到V9。
- limit:返回需要的行数。
注意:文章来源地址https://www.toymoban.com/news/detail-480544.html
- GROUP BY 条件中,每个列必须是有效列,不能是聚合函数
- NULL 值也会作为一个分组返回
- 除了聚合函数,SELECT 子句中的列必须在 GROUP BY 条件中
到了这里,关于数据库的基础学习1:select语句的查询的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!