基于pytorch实现VGG16模型
前言
最近在看经典的卷积网络架构,打算自己尝试复现一下,在此系列文章中,会参考很多文章,有些已经忘记了出处,所以就不贴链接了,希望大家理解。
完整的代码在最后。
本系列必须的基础
python基础知识、CNN原理知识、pytorch基础知识
本系列的目的
一是帮助自己巩固知识点;
二是自己实现一次,可以发现很多之前的不足;
三是希望可以给大家一个参考。
目录结构
1. VGG16模型介绍:
VGG是2014发布的,在图像分类上的ImageNet比赛上为当时的亚军,冠军是GoogLeNet。
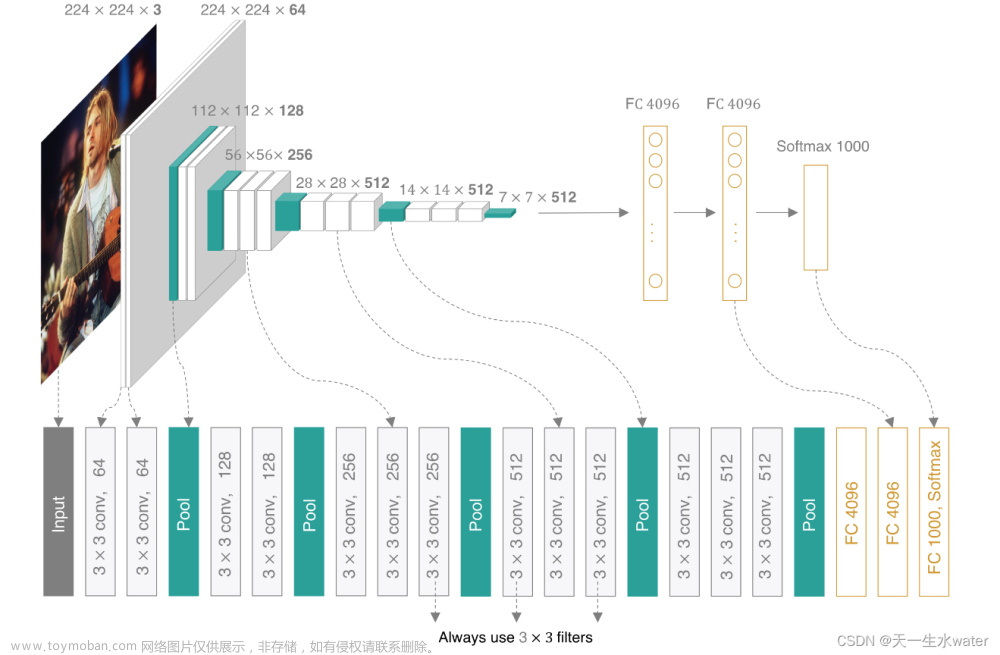
在VGG论文中,主要应用的模型是VGG16和VGG19,其中数字表示层数。
其中VGG16具体的架构为:

上面可以简记为:2+pool+2+pool+3+pool+3+pool+3+pool+3FC。
2. VGG16模型构建:
代码参考于pytorch官方实现的版本
首先,导入需要的模块:
# 导包
import torch
from torch import nn
其次,把pytorch实现模型的基本结构写出来:
# 创建AlexNet模型
class My_VGG16(nn.Module):
def __int__(self):
super(My_VGG16, self).__int__()
# 准备定义模型
# 前向算法
def forward(self,x):
pass
然后,我们先来定义前面的特征提取层,即卷积–池化—卷积–池化…的层:
# 特征提取层
self.features = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=1,padding=1),
nn.Conv2d(in_channels=64,out_channels=64,kernel_size=3,stride=1,padding=1),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=2, stride=2),
)
上面代码基本没啥难点,就是按照VGG16的标准架构,一层一层写出来的,就不写注释了(有什么问题可以留言)。
然后,我们来实现全连接的部分:
# 分类层
self.classifier = nn.Sequential(
# 全连接的第一层,输入肯定是卷积输出的拉平值,即7*7*512
# 输出是由VGG决定的,为4096
nn.Linear(in_features=7*7*512,out_features=4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(in_features=4096,out_features=4096),
nn.ReLU(),
nn.Dropout(0.5),
# 最后一层,输出1000个类别,也是我们所说的softmax层
nn.Linear(in_features=4096,out_features=1000)
)
上面代码中,不要忘记加上全连接层必备的激活函数和VGG采取的正则化手段dropout即可。
最后,我们定义我们的前向算法:
def forward(self,x):
x = self.features(x)
# 不要忘记在卷积--全连接的过程中,需要将数据拉平,之所以从1开始拉平,是因为我们
# 批量训练,传入的x为[batch(每批的个数),x(长),x(宽),x(通道数)],因此拉平需要从第1(索引,相当于2)开始拉平
# 变为[batch,x*x*x]
x = torch.flatten(x,1)
result = self.classifier(x)
return result
3. 总结:
VGG16的构建和AlexNet几乎差不多,非常的简单。当然,和AlexNet一样,我也没有收集数据进行训练,不过大家可以自行尝试,简单点可以使用MNIST数据集,或者可以去网上找到ImageNet的开源数据集,收集一小部分来用。文章来源:https://www.toymoban.com/news/detail-480649.html
完整代码文章来源地址https://www.toymoban.com/news/detail-480649.html
# author: baiCai
# 导包
import torch
from torch import nn
from torchvision.models import VGG
# 创建模型
class My_VGG16(nn.Module):
def __init__(self):
super(My_VGG16, self).__init__()
# 特征提取层
self.features = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=1,padding=1),
nn.Conv2d(in_channels=64,out_channels=64,kernel_size=3,stride=1,padding=1),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 分类层
self.classifier = nn.Sequential(
# 全连接的第一层,输入肯定是卷积输出的拉平值,即6*6*256
# 输出是由AlexNet决定的,为4096
nn.Linear(in_features=7*7*512,out_features=4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(in_features=4096,out_features=4096),
nn.ReLU(),
nn.Dropout(0.5),
# 最后一层,输出1000个类别,也是我们所说的softmax层
nn.Linear(in_features=4096,out_features=1000)
)
def forward(self,x):
x = self.features(x)
# 不要忘记在卷积--全连接的过程中,需要将数据拉平,之所以从1开始拉平,是因为我们
# 批量训练,传入的x为[batch(每批的个数),x(长),x(宽),x(通道数)],因此拉平需要从第1(索引,相当于2)开始拉平
# 变为[batch,x*x*x]
x = torch.flatten(x,1)
result = self.classifier(x)
return result
到了这里,关于pytorch实战3:基于pytorch复现VGG16的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!