Meta AI 开源万物可分割 AI 模型,11亿+掩码数据集可提取
SAM Demo:https://segment-anything.com/
开源地址:https://github.com/facebookresearch/segment-anything
论文地址:https://ai.facebook.com/research/publications/segment-anything/
SA-1B数据集:https://ai.facebook.com/datasets/segment-anything/
根据 Meta AI 官方博客,Meta AI 宣布推出了一个名为“分割一切模型”(SAM)的 AI 模型,该模型能够根据文本指令等方式实现图像分割,而且万物皆可识别和一键抠图。
图像分割是计算机视觉领域的一项核心任务,在科学图像分析、照片编辑等各类场景中拥有广泛应用。Meta AI 表示,推出 Segment Anything 项目的目的是为了实现分割技术的大众化。除通用 Segment Anything 模型(SAM)之外,他们还发布了 Segment Anything 1-Billion(SA-1B)掩码数据集。作为有史以来体量最大的分割数据集,Segment Anything 能够支持广泛的应用场景,并助力计算机视觉基础模型的进一步研究。
项目演示
在图像中指定要分割的内容的提示,可以实现各种分割任务,而无需额外的训练。

SAM 可以接受来自其他系统的输入提示,例如,根据 AR / VR 头显传来的用户视觉焦点信息,来选择对应的物体。Meta AI 团队通过发展可以理解现实世界的 AI,为未来元宇宙之路铺平道路。

或者,利用来自物体检测器的边界框提示,实现文本到物体的分割。

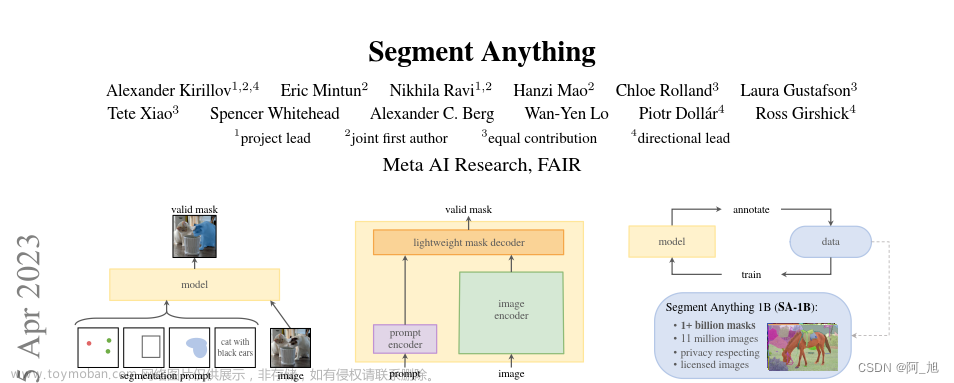
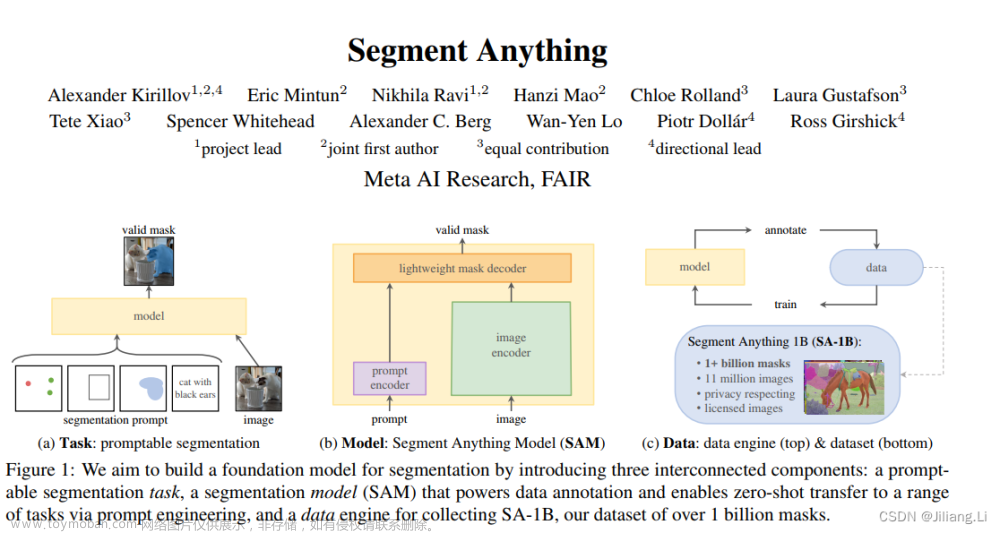
SAM 的工作原理:提示分割
SAM 是一种基础模型,可以使用“提示”技术对新数据集和任务执行零样本和少样本学习。经过训练,SAM 能够根据任何提示返回有效的分割掩码,包括前景 / 背景点、粗框或掩码、自由格式文本等一切能够指示图像内分割内容的信息。即使提示不够明确且可能指代多个对象,输出也应合理有效。Meta AI 团队通过这项任务对模型进行预训练,引导其通过提示解决常规的下游分割任务。
SAM 模型需要在网络浏览器的 CPU 上实时运行,这样标注者才能与 SAM 实时交互并高效进行标注。在工作原理层面,图像编码器会为图像生成一次性嵌入,而轻量级编码器则将所有提示实时转换为嵌入向量。之后,将这两个信息源组合在一个负责预测分割掩码的轻量级解码器内。在计算图像嵌入之后,SAM 能够在 50 毫秒内根据网络浏览器中的任意提示生成相应分割。
SAM 模型遵循了基础模型的思路,包括三个主要方面:简单且可扩展的架构,可以处理多模态提示:文本、关键点、边界框;直观的标注流程,与模型设计紧密相连;一个数据飞轮,允许模型自举到大量未标记的图像。12SAM 模型已经学会了“物体”的一般概念,即使在未知物体、不熟悉的场景(例如水下和显微镜下)以及模糊的案例中也能表现出色。2SAM 模型是 Meta 发布的史上首个图像分割基础模型,将 NLP 领域的 prompt 范式引进 CV,让模型可以通过 prompt 一键抠图。
此外,SAM 还能够泛化到新任务和新领域,从业者并不需要自己微调模型了。最强大的是,Meta 实现了一个完全不同的 CV 范式,你可以在一个统一框架 prompt encoder 内,指定一个点、一个边界框、一句话,直接一键分割出物体。文章来源:https://www.toymoban.com/news/detail-481168.html
对此,腾讯 AI 算法专家金天表示,「NLP 领域的 prompt 范式,已经开始延展到 CV 领域了。而这一次,可能彻底改变 CV 传统的预测思路。这一下你可以真的可以用一个模型,来分割任意物体,并且是动态的!」 英伟达 AI 科学家 Jim Fan 对此更是赞叹道:我们已经来到了计算机视觉领域的「GPT-3 时刻」!文章来源地址https://www.toymoban.com/news/detail-481168.html
到了这里,关于SegmentAnything 模型 (SAM):万物可分割 AI 模型,11亿+掩码数据集可提取的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[医学分割大模型系列] (3) SAM-Med3D 分割大模型详解](https://imgs.yssmx.com/Uploads/2024/04/857154-1.png)