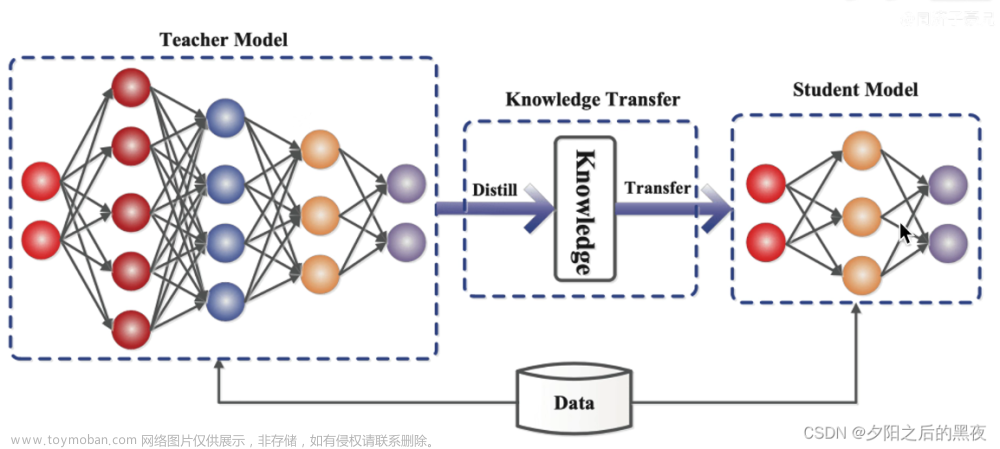
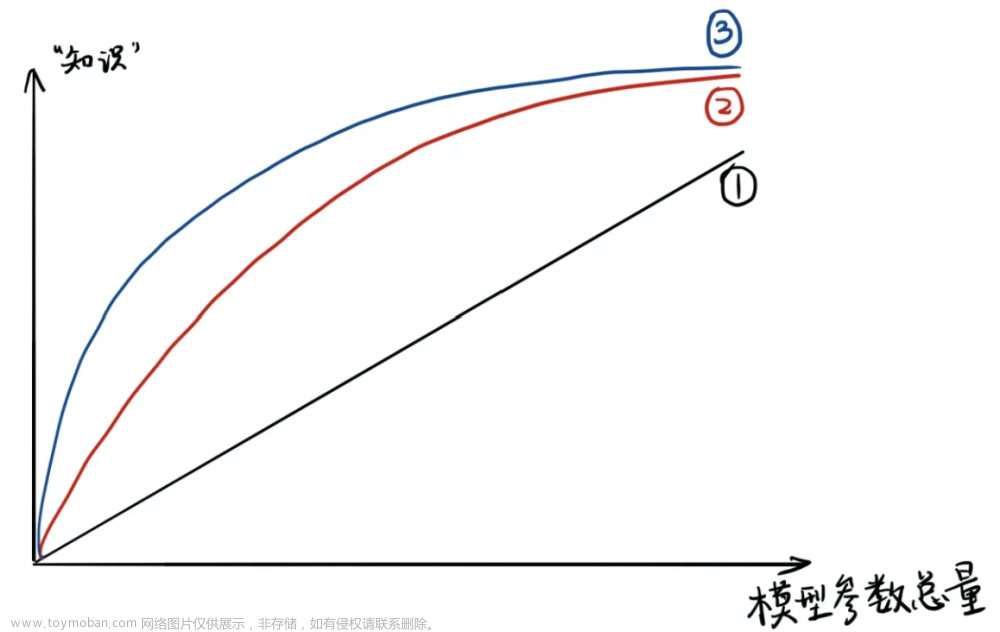
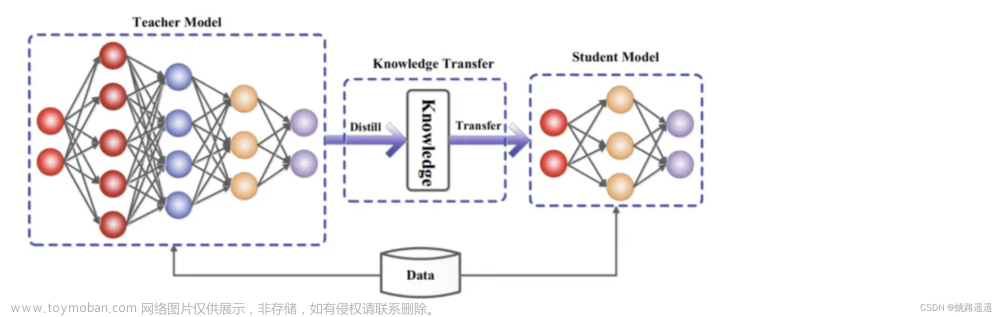
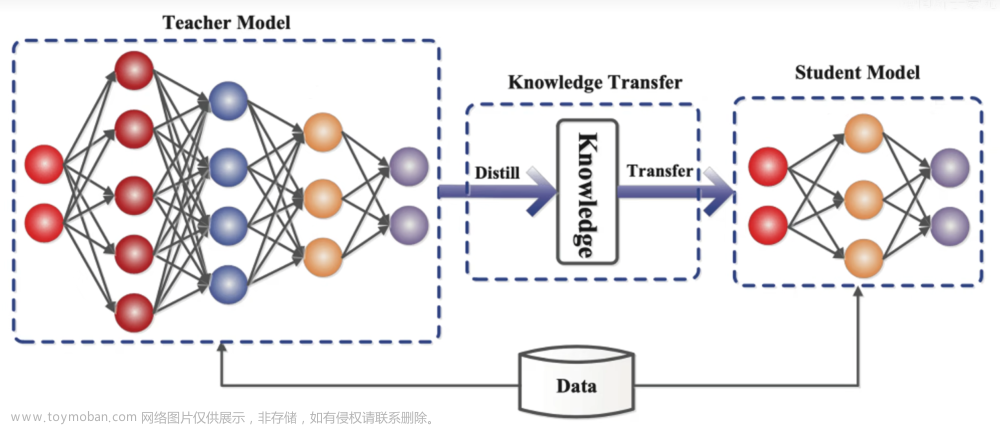
DiffKD文章来源:https://www.toymoban.com/news/detail-481223.html
摘要文章来源地址https://www.toymoban.com/news/detail-481223.html
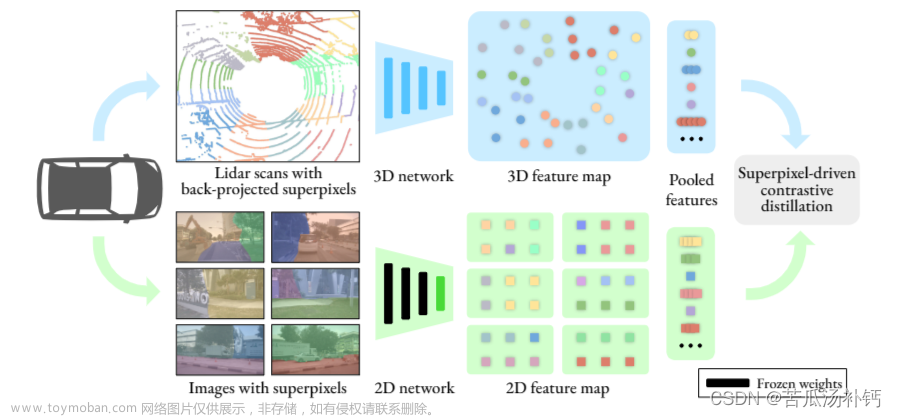
The representation gap between teacher and student is an emerging topic in knowledge distillation (KD).
To reduce the gap and improve the performance, current methods often resort to complicated training schemes, loss functions, and feature alignments, which are task-specific and feature-specific.
In this paper, we state that the essence of these methods is to discard the noisy information and distill the valuable information in the feature, and propose a novel KD method dubbed DiffKD, to explicitly denoise and match features using diffusion models.
Our approach is based on the observation that student features typically contain more noises than teacher features due to the smaller capacity of student model.
To address this, we propose to denoise student features using a diffusion model trained by teacher features.
This allows us to perform better distillation betwe
To reduce the gap and improve the performance, current methods often resort to complicated training schemes, loss functions, and feature alignments, which are task-specific and feature-specific.
In this paper, we state that the essence of these methods is to discard the noisy information and distill the valuable information in the feature, and propose a novel KD method dubbed DiffKD, to explicitly denoise and match features using diffusion models.
Our approach is based on the observation that student features typically contain more noises than teacher features due to the smaller capacity of student model.
To address this, we propose to denoise student features using a diffusion model trained by teacher features.
This allows us to perform better distillation betwe
到了这里,关于[读论文][backbone]Knowledge Diffusion for Distillation的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!