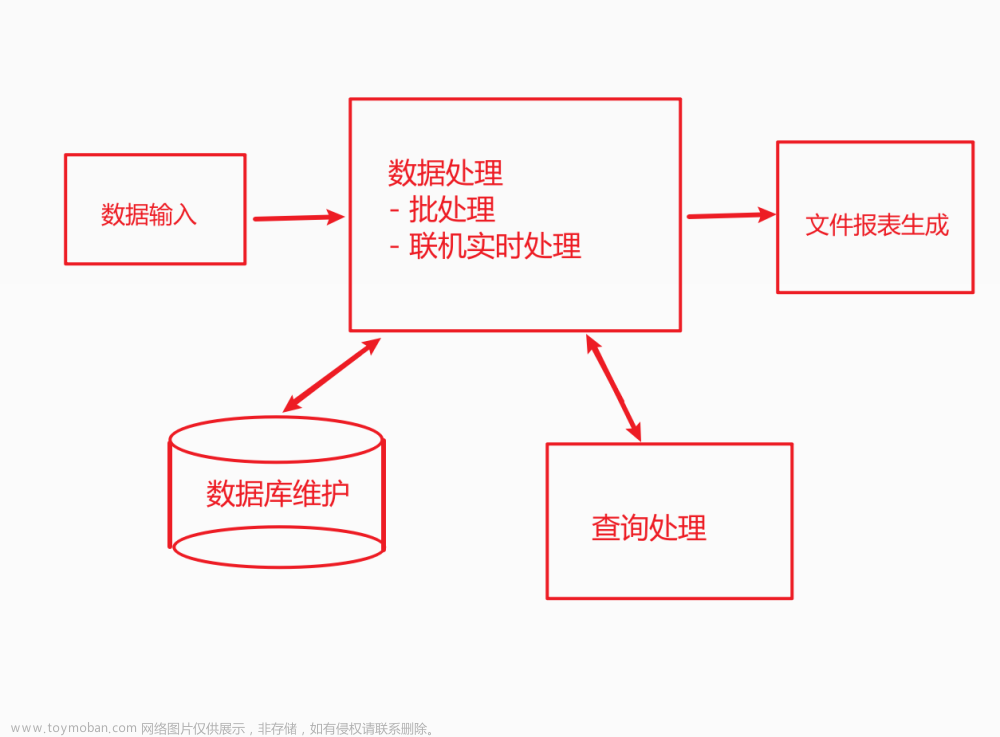
实现内容:
(本文中用到的文件名为:hyatt-k)
利用文件读取方法对给定邮件数据集中的文本文件进行预处理,并按照图1中的词项词典构造流程生成词项词典。

针对给定的邮件数据集和生成的词项词典,建立词项文档关联矩阵(如图1-1所示)

针对给定的邮件数据集和生成的词项词典,按照1-3流程,建立倒排索引


实现步骤:
1.首先,把邮件读到文件里:
有这一步的原因是没有办法直接解析邮件文件,需要读取邮件到word文件中,解析文本文件。
import shutil
from email.parser import Parser
import pandas as pd
import os,jieba,glob,re
# import content_standard
# filter = [""]
def findAllFile(dirname):
for maindir, subdir, file_name_list in os.walk(dirname):
print(file_name_list)
for filename in file_name_list:
apath = os.path.join(maindir, filename)
yield apath
def main():
base = 'E:\datas\information\junior1.0\信息检索技术\信息检索技术实验相关材料\hyatt-k'
# 这里的文件是自己需要解析的邮件文件,路径需要存放到定义地址
# f = open('E:\datas\information\junior1.0\信息检索技术\exercise1\dict1.docx', 'w', encoding='utf-8', errors='ignore')
for i in findAllFile(base):
writepath = i + '.doc'
ff = open(writepath, 'w')
with open(i, encoding='utf-8', errors='ignore') as fq:
email = fq.read()
email_text = Parser().parsestr(email)
want_text = email_text.get_payload()
print("start write")
# for line in currentfile:
# f.writelines(line)
# want_text = want_text.strip('\n')
ff.writelines(want_text)
print("Success write")
ff.close()
if __name__ == '__main__':
main()
运行结果(部分):

可见,读入邮件成功!
写入文档:

2.利用文件读取方法对给定邮件数据集中的文本文件进行预处理:
a.文本预处理:
当拿到一个文本后,首先从文本正则化(text normalization) 处理开始。常见的文本正则化步骤包括:
将文本中出现的所有字母转换为小写或大写
将文本中的数字转换为单词或删除这些数字
删除文本中出现的标点符号、重音符号以及其他变音符号
删除文本中的空白区域
扩展文本中出现的缩写
删除文本中出现的终止词、稀疏词和特定词
文本规范化(text canonicalization)
import re
import string
import xlsxwriter
from pprint import pprint
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
# 列表去重
def unique(word_list):
return list(dict.fromkeys(word_list))
# 移除停用词
def stop_word(token):
stopped_word = [w for w in token if w not in stopwords.words('english')]
return stopped_word
# 词干提取
def stem_extracting(stopped_tokens):
p_stemmer = PorterStemmer()
texts = [p_stemmer.stem(i) for i in stopped_tokens]
return texts
def incidence_matrix(text, docID):
# 1.清除英文标点符号
punctuation_string = string.punctuation
lines = re.sub('[{}]'.format(punctuation_string), " ", text)
# 2.将英文文本内容切片 将其他非字母字符转化为空格
FILTER_PUNTS = re.compile("[^\u4E00-\u9FA5|^a-z|^A-Z]")
lines = FILTER_PUNTS.sub(" ", lines.strip())
lsplit = lines.split()
# 3.大小写转换
for num in range(len(lsplit)):
lsplit[num] = lsplit[num].lower()
# 4.移除停用词 词干提取
lsplit = stem_extracting(stop_word(lsplit))
# 5.拼写校正
# lsplit = Normalization.spell_correction(lsplit)
# 6.去重并转字典
lsplit_dic = dict.fromkeys(lsplit)
lsplit_dic1 = lsplit_dic
# 7.记录文档号
for word in lsplit_dic.keys():
lsplit_dic[word] = [docID]
return lsplit_dic1此处演示结果省略
b.多文件夹读文件:
使用glob包。它是一个简单的文件匹配包,用来查找符合特定规则的文件路径名,支持使用简单的通配符进行配匹配,包括: * ? []。
在这一步时,一定注意,文件的路径一定要和定义好的文件搜索路径一致,否则将会报错。

改正方法:直接把nltk_data文件夹放在search in提供的路径里面。
# 多文件夹读文件
def findAllFile(dirname):
global total
total = 0
for maindir, subdir, file_name_list in os.walk(dirname):
# print(file_name_list)
for filename in file_name_list:
total = total + 1
apath = os.path.join(maindir, filename)
yield apath
def read_file(base):
result = {}
count = 0
for i in findAllFile(base):
if i.endswith('.doc'):
with open(i, 'r') as file_to_read:
# 以只读形式打开该文件
lines = file_to_read.read()
count = count + 1
lsplot = incidence_matrix(lines, count) # 词典
result = dic_zip(result, lsplot)
# 关闭文件读取
file_to_read.close()
return result3.生成词项词典:
Python 中3种创建字典数据的方法
1.直接使用 {} 创建字典
2.通过字典 (dict)函数来创建字典
3.使用字典推导式 (dict comprehensions)的方法创建字典。
此处选用字典函数。
4.建立词项文档关联矩阵:
词项-文档矩阵,简写为TF-IDF(term frequency times inverse document frequency)
矩阵中的每个元素值代表了相应行上的词项对应于相应列上的文档的权重,即这个词对于这篇文章来说的重要程度。
一个词对于一篇文章是否重要,体现在两个方面:
一个词项在一个文档中出现次数越多,他相对于文档的重要性就越大,这个指标就是我们的TF值
TF = 词项在该文档中出现的次数/这篇文档所有的词项数
若词项在整个语料库中出现的次数越多,那么对于某一篇文章而言这个词就越没有意义,即越不重要。我们用逆文档频率idf来表示这个词在整个语料库中的重要程度,故,出现越多的词,idf值会越低,出现越少的词,idf值会越高
IDF = log(N/d)
N为所有文档的总数;d为出现过某个单词的文档的总数。
在现实中,词项在语料中的频率往往呈指数型。
一个常用词出现的次数往往是一个次常用词出现次数的几十倍,这样常用词的权重会非常低(如“的”这样的词N/D几乎可能几乎等于1),故我们对逆文档频率取对数log,如此,文档频率的差别就从乘数变成了加数级了。
综上所述,我们在计算词项在一个文档中的重要程度,要考虑以上两个因素,用TF-IDF值来共同衡量:TF-IDF = TF * IDF
代码同5一起见下
结果如下:

5.建立倒排索引:
如何建立倒排索引?步骤如下:文章来源:https://www.toymoban.com/news/detail-481716.html
- 用分词系统将文档自动切分成单词序列,每个文档就转换为由单词序列构成的数据流;
- 对每个不同单词赋予唯一的单词编号(ID),并记录每个单词对应的文档频率(文档集合中,包含某个单词的文档数量,占文档总数量的比率)、包含该单词的对应文档编号(DocID)、该单词在各对应文档中的词频(TF)(在某个文档中出现的次数)、该单词出现在某个文档中的位置(POS)等。
-
def write_dic(a_dic): # 文档频率可用于做查询优化 i = 1 file_write = open("results.txt", "w") tplt = "{0:^10}\t{1:{3}^10}\t{2:^40}" wb = xlsxwriter.Workbook('results.xlsx') # 创建一个工作簿 ws = wb.add_worksheet() # 创建一个工作表 for j in range(0, total): ws.write(0, j + 1, j + 1) # print(tplt.format("词项", "文档频率", "倒排记录", chr(12288))) for word in a_dic.keys(): # 倒排索引生成 file_write.write(tplt.format(str(word), len(a_dic[word]), str(a_dic[word]), chr(12288)) + '\n') # print(tplt.format(str(word), len(a_dic[word]), str(a_dic[word]), chr(12288))) ws.write(i, 0, str(word)) # print (str(word)) for frequence in range(0, len(a_dic[word])): ws.write(i, a_dic[word][frequence], 1) i = i + 1 # print(a_dic[word]) file_write.close() wb.close() def main(): # 读取filename下的英文文本文件 将每一行作为单独的文本 # 建立倒排索引。 base = 'E:\datas\information\junior1.0\信息检索技术\信息检索技术实验相关材料\hyatt-k' matrix = dic_sort(read_file(base)) write_dic(matrix) if __name__ == '__main__': main()结果如下:
 文章来源地址https://www.toymoban.com/news/detail-481716.html
文章来源地址https://www.toymoban.com/news/detail-481716.html总结:性能扩展性等方面可能存在的不足和可能的改进之处。例如出现多个重复数据,如:a,aa,aaa。
到了这里,关于信息检索(基础知识一)——词项-文档关联矩阵及倒排索引构建的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!