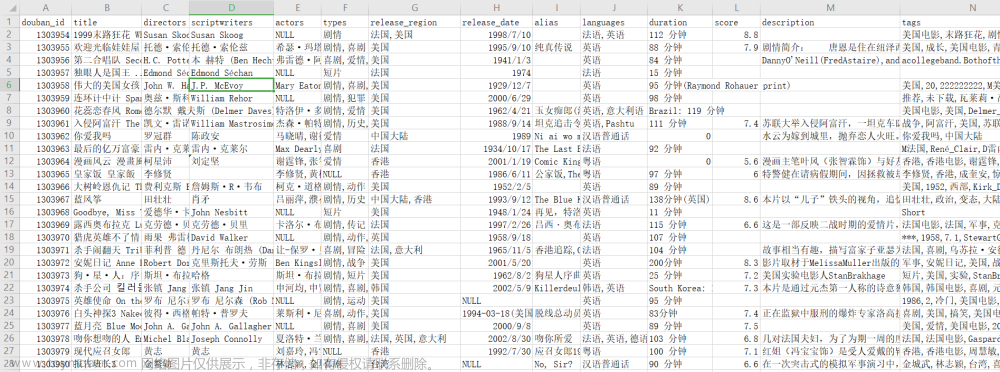
根据电影数据,使用pyecharts进行可视化分析。
数据介绍
import pandas as pd
data=pd.read_csv('./电影.csv')
data.head()
前5行数据如下:
需要安装的python库
pip install pandas
pip install pyecharts
数据清洗
查看缺失值
data.isnull().sum()
有部电影没有给出编剧和主演,因此没有爬取到,这不影响数据的分析及可视化。
之前数据介绍时可以看到,获取的数据各字段目前没有需要清洗的。这个环节就跳过吧。(想加个表情,没找到在哪加。)
数据可视化
上映年份及电影数量
Year=data['上映年份'].value_counts().reset_index()
Year.rename(columns={"index":"上映年份","上映年份":"电影数量"},inplace=True)
Year.head()

我是在jupyter notebook中运行的,如果你在其他编辑器中运行,更改代码最后一行bar.render_notebook()为bar.render("xxx.html"),运行成功会生成一个xxx.html的文件,你打开应该就能看到可视化图表。后续代码同理。
导入pyecharts
from pyecharts.charts import Bar,Pie,Line
import pyecharts.options as opts
bar = (
Bar(init_opts=opts.InitOpts(height='700px', theme='light'))
.add_xaxis(
Year['上映年份'].tolist()[::-1])
.add_yaxis(
"电影数量",
Year['电影数量'].tolist()[::-1],
label_opts=opts.LabelOpts(is_show=False),
)
.set_series_opts(itemstyle_opts=opts.ItemStyleOpts(
border_color='#5C3719', ))
.set_global_opts(
title_opts=opts.TitleOpts(
title='上映年份及电影数量',
subtitle='截止2023年3月',
title_textstyle_opts=opts.TextStyleOpts(
font_family='Microsoft YaHei',
font_weight='bold',
font_size=22,
),
pos_top='1%'),
legend_opts=opts.LegendOpts(is_show=True),
xaxis_opts=opts.AxisOpts(
# name='电影数量',
is_show=True,
max_=int(Year['电影数量'].max()),
axislabel_opts=opts.LabelOpts(
font_family='Microsoft YaHei',
font_weight='bold',
font_size='14' #标签文本大小
)),
yaxis_opts=opts.AxisOpts(
# name='上映年份',
is_show=True,
axislabel_opts=opts.LabelOpts(
#interval=0,#强制显示所有y轴标签,需要可以加上
font_family='Microsoft YaHei',
font_weight='bold',
font_size='14' #标签文本大小
)),
tooltip_opts=opts.TooltipOpts(
is_show=True,
trigger='axis',
trigger_on='mousemove|clike',
axis_pointer_type='shadow',
),
toolbox_opts=opts.ToolboxOpts(is_show=True,
pos_left="right",
pos_top="center",
feature={"saveAsImage":{}}
)
).reversal_axis())
bar.render_notebook()

这里我没设置显示全部Y轴标签,代码中给出了强制显示所有Y轴标签的注释。根据图表得出,2010年上映的电影数量最多,为14部电影。
导演及电影数量TOP10
Director=data['导演'].value_counts()[0:11].reset_index()
Director.rename(columns={"index":"导演","导演":"电影数量"},inplace=True)
Director.head()

pie = (
Pie(init_opts=opts.InitOpts(theme='light'))
.add(
series_name='电影类型',
data_pair=[list(z) for z in zip(Director['导演'].to_list(), Director['电影数量'].to_list())],
radius=["40%", "75%"],
)
# .set_colors(["blue", "green", "yellow", "red", "pink", "orange", "purple"])
.set_global_opts(
title_opts=opts.TitleOpts(
title="导演及电影数量",
subtitle='TOP10',
title_textstyle_opts=opts.TextStyleOpts(
font_family='Microsoft YaHei',
font_weight='bold',
font_size=22,
),
),
legend_opts=opts.LegendOpts(
pos_left="left",
pos_top="center",
orient='vertical',
is_show=True
),
toolbox_opts=opts.ToolboxOpts(
is_show=True,
pos_left="right",
pos_top="center",
feature={"saveAsImage":{}}
)
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render_notebook()

这个只取了TOP10的数据,如果你想取更多的数据,更改
Director=data['导演'].value_counts()[0:11].reset_index()
[0:10]表示从索引0取到索引9,你可以自己更改。
编剧及电影数量TOP10
Screenwriter=data['编剧'].value_counts()[0:11].reset_index()
Screenwriter.rename(columns={"index":"编剧","编剧":"电影数量"},inplace=True)
Screenwriter.head()

c = (
Pie(init_opts=opts.InitOpts(theme='light'))
.add(
"",
[list(z) for z in zip(Screenwriter['编剧'].to_list(), Screenwriter['电影数量'].to_list())],
radius=["30%", "75%"],
rosetype="radius",
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="编剧及电影数量",
subtitle='TOP10',
),
legend_opts=opts.LegendOpts(
pos_left="left",
pos_top="center",
orient='vertical',
is_show=True,
)
)
)
c.render_notebook()

电影片长及数量
Film_length=data['片长'].value_counts().sort_index().reset_index()
Film_length.rename(columns={"index":"片长","片长":"电影数量"},inplace=True)
Film_length

c = (
Bar()
.add_xaxis(Film_length['片长'].to_list())
.add_yaxis(
"电影数量", Film_length['电影数量'].to_list(),
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(title_opts=opts.TitleOpts(title="电影片长及数量"))
)
c.render_notebook()

电影的片长,这个最短45分钟,最长238分钟,主要集中在98-132分钟左右。我觉得电影的质量和它的时长是没有关系的,主要还是内容吧。
电影评分及数量
Douban_score=data['豆瓣评分'].value_counts().sort_index(ascending=False).reset_index()
Douban_score.rename(columns={"index":"豆瓣评分","豆瓣评分":"电影数量"},inplace=True)
Douban_score

Line()
.set_global_opts(
title_opts=opts.TitleOpts(title="电影豆瓣评分及数量"),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
.add_xaxis(xaxis_data=Douban_score['豆瓣评分'])
.add_yaxis(
series_name="电影数量",
y_axis=Douban_score['电影数量'],
symbol="emptyCircle",
is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=False),
itemstyle_opts=opts.ItemStyleOpts(
color="red"),
markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(type_="max",name="最大值")]
)
)
)
c.render_notebook()

可以看出豆瓣评分最多的分值是8.9分,总共41部电影得到了此分值。每个人的喜好不同,你觉得很好的电影,别人觉得或许没那么好。这也体现出一直保持在高评分电影的可贵。文章来源:https://www.toymoban.com/news/detail-481746.html
本文先写到这里,后面我再更新吧,关于pyecharts的配置有很多,具体可以根据官网文档把图表更改成自己需要的样式。文章来源地址https://www.toymoban.com/news/detail-481746.html
到了这里,关于pyecharts实现电影数据分析可视化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!