1. 简介
ChatGLM 6B是清华大学和智谱合作的一个62亿参数的大语言模型。基于清华的GLM模型开发。和Meta的LLaMA模型还不是一种模型。
由于LLaMA缺乏中文语料,中文能力不佳。在中文大模型中,ChatGLM 6B参数较小,运行硬件要求较低。而表现可谓出色。所以这里作为一个基础模型先让他运行起来看看有多大的能力。
2. 准备环境
在这里我们一般使用miniconda来做python的包管理。
新建一个Python3.10环境,环境名叫chatglm-6b
conda create -n chatglm-6b python=3.10激活这个环境,从此之后都在这个环境chatglm-6b中操作
conda activate chatglm-6b文章来源地址https://www.toymoban.com/news/detail-482452.html
3. 下载代码
执行下列命令
git clone https://github.com/THUDM/ChatGLM-6B这里没有什么花哨的地方,下载下来就可以了。
4. 安装Python依赖
python环境切到chatglm-6b, 在上面克隆下来的ChatGLM-6B代码目录中执行下列命令
pip install -r requirements.txt根据ChatGLM-6B的官方文档,需要安装Pytorch Nightly(似乎不安装nightly也可以)。所以我们在装完上面的依赖包之后,删除torch,重新安装pytorch nightly。
安装方法:链接
执行命令
pip uninstall torch
pip install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu
然后,我们看下下载下来的pytorch是不是支持m1的gpu加速
执行python进入python命令行
输入命令
import torch; torch.backends.mps.is_available()输出True即为可以用M1的GPU加速。但是这里int4量化后的版本不支持MPS GPU加速。而非量化的版本虽然支持MPS GPU加速,但是如果没有32G内存的话,内存不足导致执行速度非常的慢。所以在用int4量化后的模型后,有没有MPS GPU加速都会使用CPU推理。
Python 3.10.11 (main, Apr 20 2023, 13:58:42) [Clang 14.0.6 ] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch; torch.backends.mps.is_available()
True
>>>
安装icetk
奇怪的是运行web_demo.py需要icetk包,但是没有写在requirements.txt里
补上
pip install icetk这样就把包依赖安装好了。
5. 使用模型推理
5.1. 使用int4量化模型
Mac M1上如果没有32G及32G以上内存,一般还是int4量化模型会快一点。
5.1.1. 下载模型到本地
先运行huggingface.co下的ChatGLM 6B 4int量化后的模型。这个模型推理需要6G内存,finetune需要7G内存。对于小内存用户来说是最小硬件需求的模型。
huggingface.co克隆git repo需要git-lfs
所以先运行
git lfs install如果没有装过git-lfs,可以看这个链接安装git-lfs
克隆int4量化model
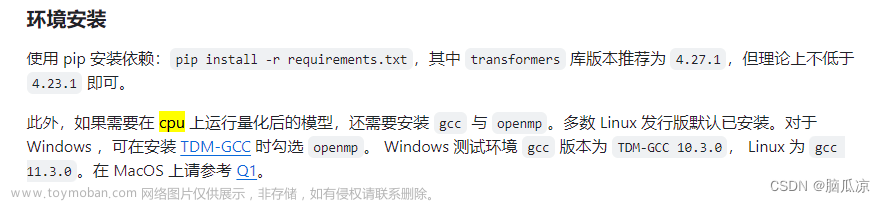
git clone https://huggingface.co/THUDM/chatglm-6b-int4Mac上没有CUDA可以用,而量化模型是基于CUDA开发的。所以M1/M2的MPS GPU加速也不可用,这里只能用CPU推理。CPU推理需要安装g++和openmp
由于本机安装的g++版本是14.x,所以可以按照链接的指示安装openmp
然后把THUDM/chatglm-6b-int4拷贝到代码的ChatGLM-6B下。所以在本地克隆下来的代码目录下,模型放在
代码目录/THUDM/chatglm-6b-int4下
5.1.2. 修改代码
打开web_demo.py,修改代码。
把下面代码
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()改为
tokenizer = AutoTokenizer.from_pretrained("./THUDM/chatglm-6b-int4/", trust_remote_code=True)
model = AutoModel.from_pretrained("./THUDM/chatglm-6b-int4/", trust_remote_code=True).float()5.1.3. 执行推理
执行命令
python web_demo.py输出
Arguments: (RuntimeError('Unknown platform: darwin'),)
No compiled kernel found.
Compiling kernels : ...
Compiling clang -O3 -fPIC -pthread -Xclang -fopenmp -lomp -std=c99 /Users/heye/.cache/huggingface/modules/transformers_modules/quantization_kernels_parallel.c -shared -o ...
Load kernel : ...
Setting CPU quantization kernel threads to 4
Using quantization cache
Applying quantization to glm layers
Running on local URL: http://127.0.0.1:7860自动弹出浏览器:http://127.0.0.1:7860/
就可以用了。
可以试试输入几个问题
1. 方程和函数有什么区别
2.
6. 性能
由于用CPU推理,一个词一个词往外蹦,每个词耗时大约是3-4秒。
如果在Windows下用GPU推理的话速度大约会提升十倍。
量化和非量化版本在表现上差异很少。这点比LLaMA要好很多。LLaMA的7Bint4量化版本表现比较差。
7. 评价
这个模型部署的坑非常少,清大的工程能力可谓出色。整体完成度很高。文章来源:https://www.toymoban.com/news/detail-482452.html
到了这里,关于在MacM1上运行ChatGLM-6B推理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!