.Net 使用OpenAI开源语音识别模型 Whisper
前言
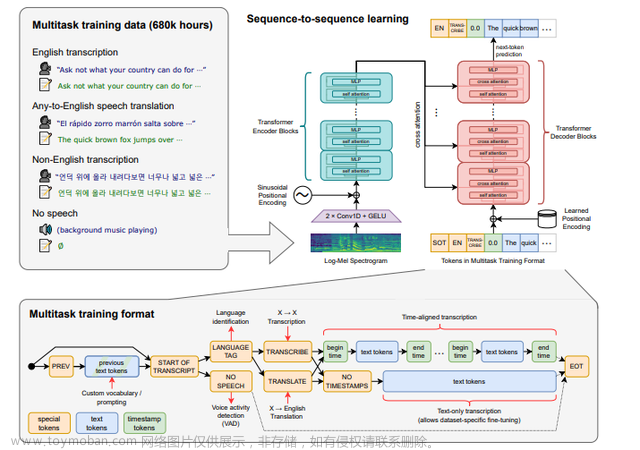
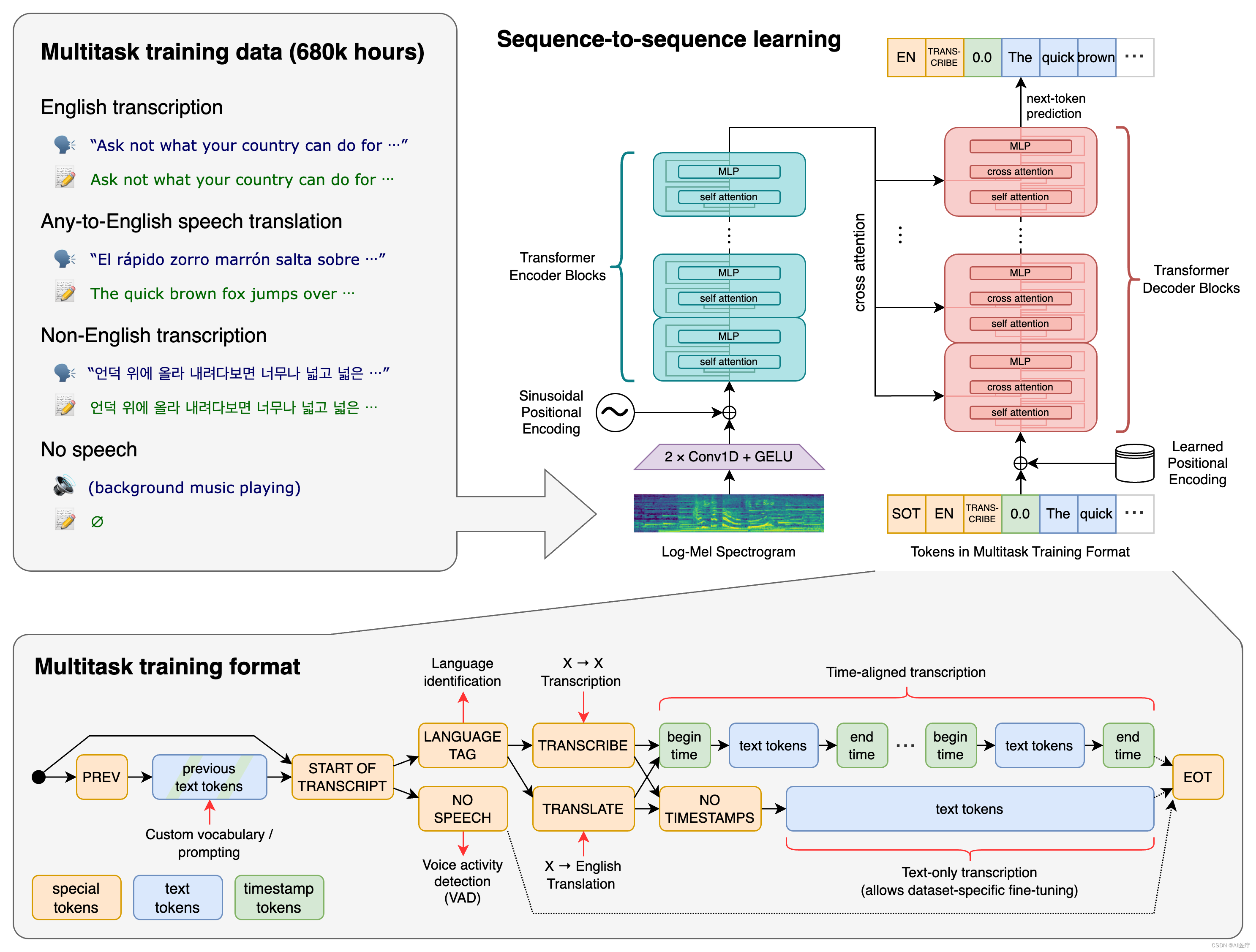
Open AI在2022年9月21日开源了号称其英文语音辨识能力已达到人类水准的 Whisper 神经网络,且它亦支持其它98种语言的自动语音辨识。 Whisper系统所提供的自动语音辨识(Automatic Speech Recognition,ASR)模型是被训练来运行语音辨识与翻译任务的,它们能将各种语言的语音变成文本,也能将这些文本翻译成英文。
whisper的核心功能语音识别,对于大部分人来说,可以帮助我们更快捷的将会议、讲座、课堂录音整理成文字稿;对于影视爱好者,可以将无字幕的资源自动生成字幕,不用再苦苦等待各大字幕组的字幕资源;对于外语口语学习者,使用whisper翻译你的发音练习录音,可以很好的检验你的口语发音水平。 当然,各大云平台都提供语音识别服务,但是基本都是联网运行,个人隐私安全总是有隐患,而whisper完全不同,whisper完全在本地运行,无需联网,充分保障了个人隐私,且whisper识别准确率相当高。
Whisper是C++写的,sandrohanea 对其进行了.Net封装。
本文旨在梳理我在.net web 项目中使用开源语音识别模型Whisper的过程,方便下次翻阅,如对您有所帮助不胜荣幸~
.Net Web 项目版本为:.Net 6.0
安装Whisper.net包
首先我们在Core项目中安装Whisper.net包。在NuGet包管理器中搜索并安装【Whisper.net】和【Whisper.net.Runtime】包,如下图所示:
注意,我们要找的是【Whisper.net】和【Whisper.net.Runtime】,不是、【WhisperNet】、【Whisper.Runtime】。

下载模型文件
前往Hugging Face下载Whisper的模型文件,一共有 ggml-tiny.bin、ggml-base.bin、ggml-small.bin、ggml-medium.bin、ggml-large.bin 5个模型,文件大小依次变大,识别率也依次变大。此外,【xxx.en.bin】是英文模型,【xxx.bin】支持各国语言。
我们将模型文件放到项目中即可,我这里是放到Web项目的wwwroot下:

新建Whisper帮助类
WhisperHelper.cs

using Whisper.net;
using System.IO;
using System.Collections.Generic;
using Market.Core.Enum;
namespace Market.Core.Util
{
public class WhisperHelper
{
public static List<SegmentData> Segments { get; set; }
public static WhisperProcessor Processor { get; set; }
public WhisperHelper(ASRModelType modelType)
{
if(Segments == null || Processor == null)
{
Segments = new List<SegmentData>();
var binName = "ggml-large.bin";
switch (modelType)
{
case ASRModelType.WhisperTiny:
binName = "ggml-tiny.bin";
break;
case ASRModelType.WhisperBase:
binName = "ggml-base.bin";
break;
case ASRModelType.WhisperSmall:
binName = "ggml-small.bin";
break;
case ASRModelType.WhisperMedium:
binName = "ggml-medium.bin";
break;
case ASRModelType.WhisperLarge:
binName = "ggml-large.bin";
break;
default:
break;
}
var modelFilePath = $"wwwroot/WhisperModel/{binName}";
var factory = WhisperFactory.FromPath(modelFilePath);
var builder = factory.CreateBuilder()
.WithLanguage("zh") //中文
.WithSegmentEventHandler(Segments.Add);
var processor = builder.Build();
Processor = processor;
}
}
/// <summary>
/// 完整的语音识别 单例实现
/// </summary>
/// <returns></returns>
public string FullDetection(Stream speechStream)
{
Segments.Clear();
var txtResult = string.Empty;
//开始识别
Processor.Process(speechStream);
//识别结果处理
foreach (var segment in Segments)
{
txtResult += segment.Text + "\n";
}
Segments.Clear();
return txtResult;
}
}
}
ModelType.cs
不同的模型名字不一样,需要用一个枚举类作区分:

using System.ComponentModel;
namespace Market.Core.Enum
{
/// <summary>
/// ASR模型类型
/// </summary>
[Description("ASR模型类型")]
public enum ASRModelType
{
/// <summary>
/// ASRT
/// </summary>
[Description("ASRT")]
ASRT = 0,
/// <summary>
/// WhisperTiny
/// </summary>
[Description("WhisperTiny")]
WhisperTiny = 100,
/// <summary>
/// WhisperBase
/// </summary>
[Description("WhisperBase")]
WhisperBase = 110,
/// <summary>
/// WhisperSmall
/// </summary>
[Description("WhisperSmall")]
WhisperSmall = 120,
/// <summary>
/// WhisperMedium
/// </summary>
[Description("WhisperMedium")]
WhisperMedium = 130,
/// <summary>
/// WhisperLarge
/// </summary>
[Description("WhisperLarge")]
WhisperLarge = 140,
/// <summary>
/// PaddleSpeech
/// </summary>
[Description("PaddleSpeech")]
PaddleSpeech = 200,
}
}
后端接受音频并识别
后端接口接受音频二进制字节码,并使用Whisper帮助类进行语音识别。

关键代码如下:
public class ASRModel
{
public string samples { get; set; }
}
/// <summary>
/// 语音识别
/// </summary>
[HttpPost]
[Route("/auth/speechRecogize")]
public async Task<IActionResult> SpeechRecogizeAsync([FromBody] ASRModel model)
{
ResultDto result = new ResultDto();
byte[] wavData = Convert.FromBase64String(model.samples);
model.samples = null; //内存回收
// 使用Whisper模型进行语音识别
var speechStream = new MemoryStream(wavData);
var whisperManager = new WhisperHelper(model.ModelType);
var textResult = whisperManager.FullDetection(speechStream);
speechStream.Dispose();//内存回收
speechStream = null;
wavData = null; //内存回收
result.Data = textResult;
return Json(result.OK());
}
前端页面上传音频
前端主要做一个音频采集的工作,然后将音频文件转化成二进制编码传输到后端Api接口中
前端页面如下:

页面代码如下:
@{
Layout = null;
}
@using Karambolo.AspNetCore.Bundling.ViewHelpers
@addTagHelper *, Karambolo.AspNetCore.Bundling
@addTagHelper *, Microsoft.AspNetCore.Mvc.TagHelpers
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>语音录制</title>
<meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<environment names="Development">
<link href="~/content/plugins/element-ui/index.css" rel="stylesheet" />
<script src="~/content/plugins/jquery/jquery-3.4.1.min.js"></script>
<script src="~/content/js/matomo.js"></script>
<script src="~/content/js/slick.min.js"></script>
<script src="~/content/js/masonry.js"></script>
<script src="~/content/js/instafeed.min.js"></script>
<script src="~/content/js/headroom.js"></script>
<script src="~/content/js/readingTime.min.js"></script>
<script src="~/content/js/script.js"></script>
<script src="~/content/js/prism.js"></script>
<script src="~/content/js/recorder-core.js"></script>
<script src="~/content/js/wav.js"></script>
<script src="~/content/js/waveview.js"></script>
<script src="~/content/js/vue.js"></script>
<script src="~/content/plugins/element-ui/index.js"></script>
<script src="~/content/js/request.js"></script>
</environment>
<environment names="Stage,Production">
@await Styles.RenderAsync("~/bundles/login.css")
@await Scripts.RenderAsync("~/bundles/login.js")
</environment>
<style>
html,
body {
margin: 0;
height: 100%;
}
body {
padding: 20px;
box-sizing: border-box;
}
audio {
display:block;
}
audio + audio {
margin-top: 20px;
}
.el-textarea .el-textarea__inner {
color: #000 !important;
font-size: 18px;
font-weight: 600;
}
#app {
height: 100%;
}
.content {
height: calc(100% - 130px);
overflow: auto;
}
.content > div {
margin: 10px 0 20px;
}
.press {
height: 40px;
line-height: 40px;
border-radius: 5px;
border: 1px solid #dcdfe6;
cursor: pointer;
width: 100%;
text-align: center;
background: #fff;
}
</style>
</head>
<body>
<div id="app">
<div style="display: flex; justify-content: space-between; align-items: center;">
<center>{{isPC? '我是电脑版' : '我是手机版'}}</center>
<center style="margin: 10px 0">
<el-radio-group v-model="modelType">
<el-radio :label="0">ASRT</el-radio>
<el-radio :label="100">WhisperTiny</el-radio>
<el-radio :label="110">WhisperBase</el-radio>
<el-radio :label="120">WhisperSmall</el-radio>
<el-radio :label="130">WhisperMedium</el-radio>
<el-radio :label="140">WhisperLarge</el-radio>
<el-radio :label="200">PaddleSpeech</el-radio>
</el-radio-group>
</center>
<el-button type="primary" size="small" onclick="window.location.href = '/'">返回</el-button>
</div>
<div class="content" id="wav_pannel">
@*{{textarea}}*@
</div>
<div style="margin-top: 20px"></div>
<center style="height: 40px;"><h4 id="msgbox" v-if="messageSatuts">{{message}}</h4></center>
<button class="press" v-on:touchstart="start" v-on:touchend="end" v-if="!isPC">
按住 说话
</button>
<button class="press" v-on:mousedown="start" v-on:mouseup="end" v-else>
按住 说话
</button>
</div>
</body>
</html>
<script>
var blob_wav_current;
var rec;
var recOpen = function (success) {
rec = Recorder({
type: "wav",
sampleRate: 16000,
bitRate: 16,
onProcess: (buffers, powerLevel, bufferDuration, bufferSampleRate, newBufferIdx, asyncEnd) => {
}
});
rec.open(() => {
success && success();
}, (msg, isUserNotAllow) => {
app.textarea = (isUserNotAllow ? "UserNotAllow," : "") + "无法录音:" + msg;
});
};
var app = new Vue({
el: '#app',
data: {
textarea: '',
message: '',
messageSatuts: false,
modelType: 0,
},
computed: {
isPC() {
var userAgentInfo = navigator.userAgent;
var Agents = ["Android", "iPhone", "SymbianOS", "Windows Phone", "iPod", "iPad"];
var flag = true;
for (var i = 0; i < Agents.length; i++) {
if (userAgentInfo.indexOf(Agents[i]) > 0) {
flag = false;
break;
}
}
return flag;
}
},
methods: {
start() {
app.message = "正在录音...";
app.messageSatuts = true;
recOpen(function() {
app.recStart();
});
},
end() {
if (rec) {
rec.stop(function (blob, duration) {
app.messageSatuts = false;
rec.close();
rec = null;
blob_wav_current = blob;
var audio = document.createElement("audio");
audio.controls = true;
var dom = document.getElementById("wav_pannel");
dom.appendChild(audio);
audio.src = (window.URL || webkitURL).createObjectURL(blob);
//audio.play();
app.messageSatuts = false;
app.upload();
}, function (msg) {
console.log("录音失败:" + msg);
rec.close();
rec = null;
});
app.message = "录音停止";
}
},
upload() {
app.message = "正在上传识别...";
app.messageSatuts = true;
var blob = blob_wav_current;
var reader = new FileReader();
reader.onloadend = function(){
var data = {
samples: (/.+;\s*base64\s*,\s*(.+)$/i.exec(reader.result) || [])[1],
sample_rate: 16000,
channels: 1,
byte_width: 2,
modelType: app.modelType
}
$.post('/auth/speechRecogize', data, function(res) {
if (res.data && res.data.statusCode == 200000) {
app.messageSatuts = false;
app.textarea = res.data.text == '' ? '暂未识别出来,请重新试试' : res.data.text;
} else {
app.textarea = "识别失败";
}
var dom = document.getElementById("wav_pannel");
var div = document.createElement("div");
div.innerHTML = app.textarea;
dom.appendChild(div);
$('#wav_pannel').animate({ scrollTop: $('#wav_pannel')[0].scrollHeight - $('#wav_pannel')[0].offsetHeight });
})
};
reader.readAsDataURL(blob);
},
recStart() {
rec.start();
},
}
})
</script>
引用
whisper官网
测试离线音频转文本模型Whisper.net的基本用法
whisper.cpp的github
whisper.net的github文章来源:https://www.toymoban.com/news/detail-482489.html
whisper模型下载文章来源地址https://www.toymoban.com/news/detail-482489.html
到了这里,关于.Net 使用OpenAI开源语音识别模型Whisper的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!