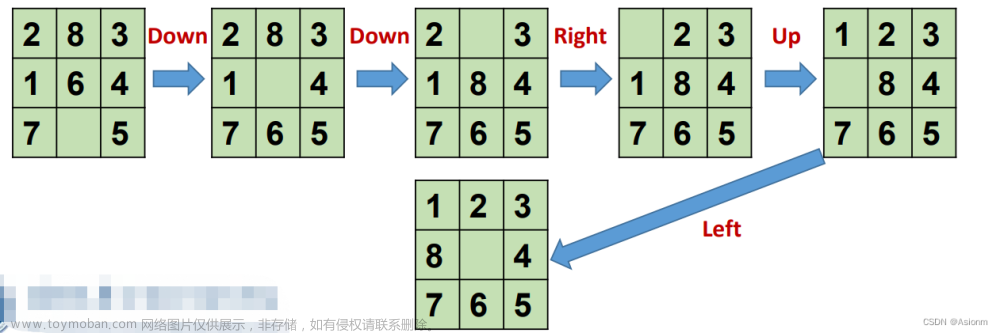
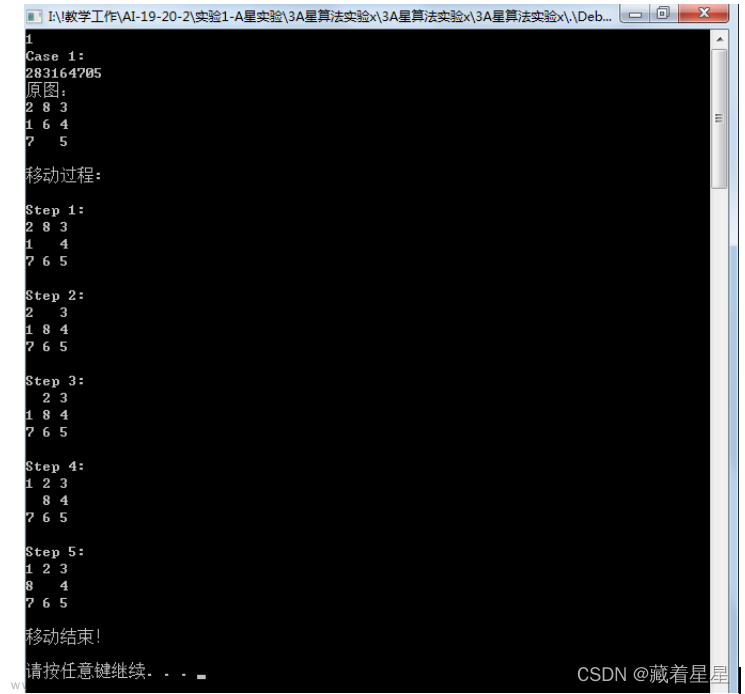
实验四:深度学习算法及应用-基于YOLOV3-DarkNet50的篮球检测模型
项目文档工程:https://github.com/mindspore-ai/mindspore-21-days-tutorials/tree/main/
前言
这个实验要求做一个深度学习项目,做头歌的或者自己在华为云找一个都行,然后在华为云一眼就相中了这个篮球检测模型的项目(篮球爱好者狂喜),通过这次实验也学习到了许多东西,了解了一些课上没有讲到的内容,但是因为源码的代码量太多而且接口也很多,所以对源码并不是很熟悉
一、实验目的
-
了解深度学习的基本原理;
-
能够使用深度学习开源工具;
-
应用深度学习算法求解实际问题。
二、实验要求
-
解释深度学习原理;
-
采用深度学习框架完成课程综合实验,并对实验结果进行分析;
-
回答思考题。
三、实验平台
华为云平台(推荐使用昇腾 910、ModelArts、OCR 识别、图像识别等完成综合实验)
https://www.huaweicloud.com/
四、实验内容与步骤
1.问题描述
主要内容是使用yolo算法对一张篮球比赛的图片进行推理,分析出图片中的篮球队员及其动作(可能是进攻、防守、走路、跑步、盖帽、摔跤等等),并给出对应的概率
2.算法原理
主要流程如下:

- 准备篮球比赛相关的数据集
- 选择YOLOv3模型
- 调用MindSpore API执行流程
即通过给定的数据集和开发好的网络模型,通过Model API进行一次封装,通过train和predict接口进行训练和推理的功能,最终模型会预测出一个结果。
此次实验的算法原理如下,主要分为三个步骤:
1)数据准备
首先从网络中获取mp4视频,通过OpenCV逐帧获取图片并保存起来。
获取原始图片后,还需要进行加工。即进行数据集标注。
接着再对图片进行预处理:
- 对图片随机进行裁剪,生成十个候选框

- 筛选纠正候选框输出唯一值

- 对输出值进行图片随机裁剪

- 对图片进行随机翻转操作(50%)

- 色彩扰动,对图片的对比度和曝光度进行处理,提高图片鲁棒性

- Normalize归一化操作,将不均匀的区域均匀化

- HWC2CHW操作,对图片尺寸进行转换

2)模型开发
目标检测

目标检测 = 图像分类 + 位置检测
目标检测分类:
Two-stage目标检测:

One-stage目标检测:

对于特征提取一般使用Backbone网络,对于目标定位和目标分类一般使用head网络
此次实验使用的YOLOv3算法就是一个One-stage目标检测算法,其特点是检测精度较低,检测速度较快
使用YOLOv3如何提升小目标检测准确率?
原因分析:随着Backbone网络层数越来越多,输出特征图的尺寸越小,更适合大目标检测的场景。

解决思路:
- 引入多尺度预测,将大尺寸特征图用于小目标检测,使用小尺寸特征图进行大目标检测;
- 为解决大尺寸特征图识别率低的问题,通过FPN算法实现特征融合,同时支持大、中、小目标的检测场景。

如图将小尺寸的特征融合到大尺寸的特征中,使得大尺寸的特征信息更丰富,从而解决大尺寸特征图识别率低的问题
新问题:如何在增加YOLOv3 Backbone网络层数的同时,仍不影响网络的精度?(过拟合问题)
答:引入残差块

YOLOv3算法检测流程:
步骤1:提取图像特征
首先是经过预处理的图片

接着做一次卷积运算,通道量会从3个变成32个

再进行卷积运算,特征量进一次增加,但图像尺寸降低

接着不断进行卷积操作,最后依次得到三种尺寸的特征图,用于后续的特征融合
-
一个256个特征,尺寸为52*52的大特征图
-
一个512个特征,尺寸为26*26的中特征图
-
一个1024个特征,尺寸为13*13的小特征图
步骤2:输出特征图预处理

对于10可分为三种:
- 位置偏移量(4维),用于Bounding box检测
- 检测置信度(1维),用于Bounding box筛选
- 类别(5维)
步骤3:基于Anchor box预测Bounding box

Anchor box:预设的一组边框集合,提升Bounding box预测准确率。
选择合适的Anchor box:
- 尺寸:不同于Faster-RCNN手动设置的方式,YOLOv3使用K-means聚类算法自动生成
- 数量:均衡检测精度和网络复杂度因素,选用9个Anchor box。
接着基于Anchor box求得Bounding box位置

步骤4:筛选Bounding box输出预测结果
统计Bounding box个数:
13
∗
13
∗
3
+
26
∗
26
∗
3
+
52
∗
52
∗
3
=
10674
13*13*3+26*26*3+52*52*3=10674
13∗13∗3+26∗26∗3+52∗52∗3=10674
置信度筛选:
- 置信度<0.01:丢弃
- 置信度>=0.01:进入候选
进行NMS算法:

- 结果大于等于0.5,说明重合过多,丢弃
- 结果小于0.5,输出结果
注意事项:
- 置信度和NMS的阈值都是人为设置的,比较依赖用户经验
- 首先执行置信度筛选操作,可大幅减少NMS计算过程的运算复杂度
3)训练/推理
Ascend环境信息:
- 硬件环境:ModelArts云服务(Ascend 910单卡)
- 框架版本:MindSpore v0.5
GPU环境信息:
- 硬件环境:GPU (Nvidia Tesla V100单卡)
- 框架版本:MindSpore v1.0
具体流程见看下面的实验步骤
3.实验步骤
1)上传测试数据集和运行脚本到OBS服务
进入华为云的OBS服务平台后,点击桶列表,再点击右上角创建桶

只需填写桶名称,将存储策略改成单AZ存储即可

上传篮球比赛图片、ckpt文件和源代码到新建的 obs 桶中,将提前给好的文件夹中的所有文件到新建的 obs 桶中:

上传全部完成之后如下:

- ckpt_files存放预训练模型
- log存放日志
- yolov3存放python程序
- basketball-dataset存放数据集
- output存放推理的结果图片
2)在ModelArts服务上执行模型推理任务
进入 ModelArts 界面之后,点击左侧“训练管理”,在下拉菜单中点击“训练作业”,进入训练作业界面后,点击中上方的“创建”按钮

创建任务的参数配置参考如下:

创建任务成功后会进行训练

训练完成后:

检测的原图为(今年NBA总决赛的截图):

预测结果如下:

可以看到,可能和图片清晰度和模型的准确度等关系有关,导致最后的结果并没有将所有人物都框出来。
下面是完成进阶版本,即将预测的对象从图片换成视频,即预测一个打篮球视频中各个人物的动作。

主要思想如上,与预测图片的步骤相比多了两部:
- 将篮球视频解码成许多篮球图片,再对这些图片进行预测
- 将图片合成生成视频
首先是将视频逐帧分解成图片的代码,参考
"""从视频逐帧读取图片"""
import glob
import cv2
import numpy as np
cv2.__version__
# 读取视频文件
cap = cv2.VideoCapture('./input.mp4')
# 获取视频帧率(30p/60p)
frame_rate = round(cap.get(5))
# 获取视频帧数
frame_num = cap.get(7)
# type(frame_num)
# 由于frame_num是foat型,需要int()转换
# 逐帧获取图片
for i in range(int(frame_num)):
ret, frame = cap.read()
cv2.imwrite('images\match_snapshot%d.jpg' % i, frame)
np.shape(frame)
cap.release()
cv2.destroyAllWindows()
运行后结果如下:

得到将近600多张图片
接着还需要对 predict.py 进行修改,因为其只预测了一张图片,修改就是加一个for循环即可

接着将文件全部上传至OBS桶中,然后进行预测
预测完成,将输出得到的图片全部放入本地目录下:

然后在图片目录下新建 jpg2video.py 文件:
# 要转换的图片的保存地址,按顺序排好,后面会一张一张按顺序读取。
import glob
import cv2
# import numpy as np
# cv2.__version__
convert_image_path = 'images-out'
frame_rate = 30
# 帧率(fps),尺寸(size),size为图片的大小,本文转换的图片大小为1920×1080,
# 即宽为1920,高为1080,要根据自己的情况修改图片大小。
size = (960, 544)
fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', 'V') # mp4
# cv2.VideoWriter_fourcc('I', '4', '2', '0')
videoWriter = cv2.VideoWriter('output.mp4', fourcc,
frame_rate, size)
for img in glob.glob(convert_image_path + "/*.jpg"):
read_img = cv2.imread(img)
videoWriter.write(read_img)
videoWriter.release()
最后生成的结果预测效果也并不是很好,很多人物都没有预测到

4.思考题
深度算法参数的设置对算法性能的影响?
- 网络架构:YOLO算法有几个版本(如YOLOv1、YOLOv2、YOLOv3等),每个版本的网络架构可能有所不同,对于不同的任务和数据集,选择适当的网络架构是至关重要的。
- 特征提取器的深度:YOLO算法中使用的特征提取器通常是基于卷积神经网络(CNN)的,网络的深度可以通过增加卷积层或堆叠更多的残差块等方式来调整。增加网络深度可能会增加模型的表达能力,但也可能增加训练和推理的计算成本。
- 输入分辨率:输入图像的分辨率也会对算法性能产生影响。较高的分辨率可以提供更多的细节信息,但同时也会增加计算量。因此,在实际应用中需要权衡分辨率与计算资源之间的关系。
- 学习率和学习策略:学习率是控制模型参数更新的速度的重要参数。选择合适的学习率和学习策略,如学习率衰减、动量等,可以加速模型的训练收敛,并提高算法性能。
- 正则化和优化器:正则化技术如L1或L2正则化可以帮助防止过拟合。选择合适的优化器(如Adam、SGD等)和正则化方法可以改善模型的泛化能力。
- 数据增强:数据增强是通过对训练数据进行随机变换来增加数据多样性。适当的数据增强可以提高模型的鲁棒性和泛化能力。
- 批量大小:批量大小是指每次训练时使用的样本数量。较大的批量大小可以提高训练的效率,但也可能导致内存消耗增加。选择适当的批量大小可以在保持训练效果的同时,兼顾计算资源的利用。
五、实验总结
在进行实验过程中,我使用YOLO算法对篮球比赛的图片进行推理,并成功地分析出了图片中的篮球队员及其动作,如进攻、防守、走路、跑步、盖帽、摔跤等等。通过这次实验,我学到了许多宝贵的经验和知识。
首先,我认识到YOLO算法在目标检测任务中的强大能力。YOLO算法通过将整个图像划分为多个网格,并在每个网格上预测边界框和类别信息,能够实现实时目标检测。这种单阶段的检测算法具有较高的速度和准确性,非常适用于处理篮球比赛这样的动态场景。
其次,我了解到数据集对算法性能的重要性。为了训练和评估算法,我使用了包含篮球比赛图像和相应标注的数据集。这个数据集的质量和多样性对于训练出准确的模型起着至关重要的作用。在未来的工作中,我会更加关注数据集的收集和标注过程,以获得更好的结果。
此外,实验过程中我还注意到了一些参数调优的技巧。例如,合理选择网络架构、调整输入分辨率、调节学习率和优化器等,都可以对算法性能产生显著影响。通过不断调整这些参数,我逐渐找到了适合我的任务和数据集的最佳配置。
最重要的是,这次实验加深了我对深度学习目标检测算法的理解。我进一步掌握了YOLO算法的工作原理,包括特征提取、边界框预测和类别分类等关键步骤。这不仅对篮球比赛的图像分析有帮助,也为我在其他领域的目标检测任务提供了基础。文章来源:https://www.toymoban.com/news/detail-482639.html
每个网格上预测边界框和类别信息,能够实现实时目标检测。这种单阶段的检测算法具有较高的速度和准确性,非常适用于处理篮球比赛这样的动态场景。
其次,我了解到数据集对算法性能的重要性。为了训练和评估算法,我使用了包含篮球比赛图像和相应标注的数据集。这个数据集的质量和多样性对于训练出准确的模型起着至关重要的作用。在未来的工作中,我会更加关注数据集的收集和标注过程,以获得更好的结果。
此外,实验过程中我还注意到了一些参数调优的技巧。例如,合理选择网络架构、调整输入分辨率、调节学习率和优化器等,都可以对算法性能产生显著影响。通过不断调整这些参数,我逐渐找到了适合我的任务和数据集的最佳配置。
最重要的是,这次实验加深了我对深度学习目标检测算法的理解。我进一步掌握了YOLO算法的工作原理,包括特征提取、边界框预测和类别分类等关键步骤。这不仅对篮球比赛的图像分析有帮助,也为我在其他领域的目标检测任务提供了基础。
总的来说,这次实验是一次宝贵的学习经历。通过实践应用YOLO算法进行篮球比赛图像分析,我不仅提升了对目标检测算法的理解,还掌握了一些实际操作技巧。这将对我的未来研究和实际应用中的计算机视觉任务产生积极的影响。文章来源地址https://www.toymoban.com/news/detail-482639.html
到了这里,关于HNU人工智能实验四-基于YOLOV3-DarkNet50的篮球检测模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!