声明:文章参考数学建模清风的网课编写。
简介
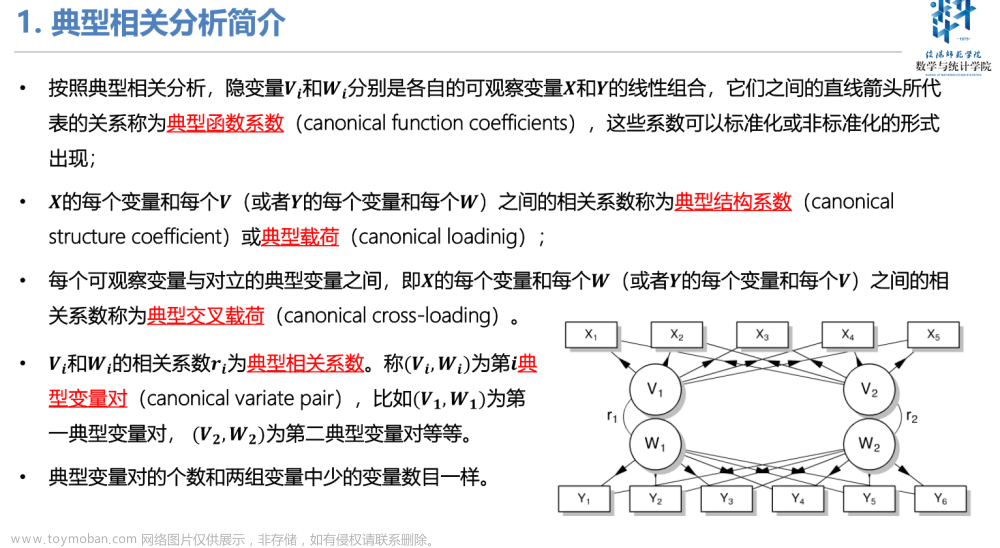
典型相关分析由Hotelling提出,其基本思想和主成分分析非常相似。用于解决两组变量间的相关性分析问题。
其主要思想为:面对一组变量时我们可能无从下手,于是我们决定从一组变量中“选代表”。那么原问题的两组变量之间的相关性分析问题可以转化为两组变量代表之间的相关性分析。此处的代表就是原组中数据的“综合”,即组内变量的线性组合(注意:一个代表可能不能完全反映组内情况,所以通常有多个代表)。
基本步骤
首先在每组变量中找出变量的线性组合(确定代表),使得两组的线性组合之间具有最大的相关系数(两组代表相关性很大,这是分析的目的和出发点);然后选取和最初挑选的这对线性组合不相关的线性组合(其它代表不能和第一个代表所代表的信息冗余了),使其配对,并选取相关系数最大的一对;如此继续下去,直到两组变量之间的相关性被提取完毕为止(选出所有代表)。
被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。典型相关系数度量了这两组变量之间联系的强度。
SPSS典型相关分析操作
- SPSS依次点击:分析->相关->典型相关:

- 选择要分析的两组变量:

- 点击第二步中的确定开始分析。
输出结果分析
-
进行典型相关分析前要假设两组数据服从联合正态分布(论文中说明即可,算是一个小点)。
-
确定典型相关变量数(代表个数)。对两组变量进行相关性检验(参照典型相关性表进行分析):

根据P值确定显著性 α \alpha α,进一步选择要保留的相关变量数。如表:变量1的P值为0.064 < 0.1( α \alpha α此时取0.1。因为取0.05或0.01都会无法拒绝原假设,也就说明相关性不显著,那么就没有数据可以选了!),拒绝原假设,我们可以称典型相关变量1的相关性在90%(1 - α \alpha α)的置信水平上显著。根据此表,变量2、3都不能满足常选用的置信水平(90%、95%和99%)故舍弃。 -
对保留的典型相关变量进行分析:


表格解释:表格中的第i列表示对应集合的第i个典型相关变量线性组合系数。分析:根据第二步,我们确定出只选择变量1,查第二步表知:两表变量1的相关系数为0.796。相关性较强,且为正相关。查标准化典型相关系数表1知:集合1的体重和腰围对变量1的贡献很大;查标准化典型相关系数表2知:集合2的起坐次数和跳跃次数对变量1的贡献很大。文章来源:https://www.toymoban.com/news/detail-482962.html
-
最终结果说明:
首先注意:变量1的相关系数为0.796。相关性较强,且为正相关。
以第三步表一中的腰围为例:由于变量1是正相关,且典型相关系数度量了这两组变量之间联系的强度。腰围的减少会对应着表二中系数值为正的变量(引体向上次数,起坐次数)值增加,会对应着表二中系数值为负的变量(跳跃次数)值减少,具体变化量由系数决定。文章来源地址https://www.toymoban.com/news/detail-482962.html
到了这里,关于【数模】典型相关分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!