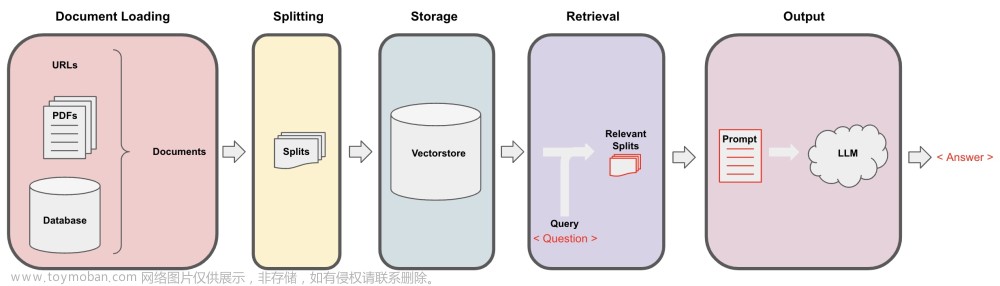
2 key approaches

Information retrieval-based QA

基于信息检索的问答(Information Retrieval-based QA)系统是一种利用信息检索技术来寻找答案的问答系统。 这种类型的问答系统的工作流程通常如下:
-
问题理解:首先,系统需要理解用户的问题,这可能涉及到词性标注、命名实体识别、依存关系解析 等自然语言处理技术。
-
文档检索:然后,系统使用信息检索技术(例如倒排索引、TF-IDF、BM25等)在大规模的文档集合(例如Wikipedia、Web页面等)中检索到与问题相关的文档或者段落。
-
答案抽取:最后,系统在检索到的文档或者段落中抽取出可能的答案。这可能涉及到更细致的文本处理和理解,例如实体链接、关系抽取、语义角色标注等。
Question Processing 问题处理

在基于信息检索的问答系统中,问题处理(Question Processing)是第一步,也是非常重要的一步。它涉及对用户问题的理解和转化,以便于系统能够有效地在文档集合中进行检索。
以下是问题处理过程中可能包含的几个步骤:
-
词法分析(Lexical Analysis):这是问题处理的第一步,包括词汇化(tokenization,即把问题分割成单词或者标记)和词形归一化(lemmatization,即把单词转化为它的基本形式,例如将复数转化为单数,将动词转化为原形等)。
-
句法分析(Syntactic Analysis):这一步可能包括词性标注(Part-of-Speech Tagging,即为每个单词标注词性,如名词、动词、形容词等)和句法解析(Parsing,即生成问题的句法结构或者依存关系)。
-
语义分析(Semantic Analysis):这一步涉及到理解问题的含义,可能包括命名实体识别(Named Entity Recognition,即识别出问题中的实体,如人名、地名等)、实体链接(Entity Linking,即把问题中的实体链接到知识库中的实体)和关系抽取(Relation Extraction,即理解问题中的实体之间的关系)。
-
问题分类(Question Classification):这一步涉及到确定问题的类型,例如它是一个事实型问题(如“奥巴马的出生地在哪里?”)还是一个描述型问题(如“描述一下奥巴马的教育背景”)等。问题的类型可以帮助系统确定应该使用什么样的策略来寻找答案。
-
关键词抽取(Keyword Extraction):这一步涉及到抽取问题中的关键词,这些关键词可以用于后续的文档检索。
经过这些步骤,问题处理模块应该能够生成一个对问题的内部表示,这个表示可以用于后续的文档检索和答案抽取步骤。这可能是一种结构化的表示(例如一个包含实体、关系和关键词的图)或者一种分布式的表示(例如一个向量,由词嵌入模型如Word2Vec或BERT生成)。
Answer Types

Retrieval 文档检索

在基于信息检索的问答系统中,检索(Retrieval)步骤是从大规模的文档集合中找出可能包含答案的文档或段落。这个步骤通常使用信息检索技术,例如倒排索引、向量空间模型、TF-IDF、BM25等。
以下是信息检索过程中可能包含的一些步骤:
-
倒排索引(Inverted Indexing):倒排索引是一种数据结构,用于存储每个词出现在哪些文档中。这使得我们可以快速地找到包含某个或某些词的所有文档。
-
查询扩展(Query Expansion):查询扩展是指将用户的查询(即问题)扩展为更多的查询词,以增加检索的召回率。查询扩展可以使用同义词、词干还原、相关词等方法。
-
文档排序(Document Ranking):文档排序是根据文档与查询的相关度进行排序。这可以使用诸如TF-IDF、BM25等模型,也可以使用更复杂的学习排名(Learning to Rank)方法。
-
文档抽取(Document Snippet Extraction):在找到可能相关的文档后,可能需要进一步抽取出包含答案的具体段落或句子。
-
向量表示(Vector Representation):对查询和文档进行向量化表示,以便进行相关性比较和排名。这可以通过词袋模型、TF-IDF、词嵌入等方法实现。
-
目前主要是神经网络在作为
retrieval
Answer Extraction 答案提取


- 使用神经网络来提取答案是目前的主流方法


使用神经网络进行答案抽取一般会采用深度学习的阅读理解模型,这些模型通常在给定一段文本(通常称为篇章)和一个问题的情况下,能够抽取出篇章中的一个跨度作为问题的答案。以下是使用神经网络进行答案抽取的一些主要步骤:
-
数据准备:首先,你需要一个带有问题、篇章和答案的数据集。一般来说,答案将是篇章中的一个跨度,这个跨度的开始和结束位置会被标注出来。
-
模型选择:接着,你需要选择一个阅读理解模型。许多阅读理解模型都是基于Transformer结构的,如BERT、RoBERTa、ALBERT等。这些模型能够很好地理解问题和篇章的语义,并且能够处理长距离的依赖关系。
-
模型训练:然后,你需要训练你的模型。模型的输入将是问题和篇章,输出将是答案的开始和结束位置。训练目标是最小化模型预测的开始和结束位置与真实答案的开始和结束位置之间的差异。
-
答案抽取:在模型训练完成后,你可以使用它来抽取答案。给定一个问题和一个篇章,模型将预测出答案的开始和结束位置,然后你可以抽取出篇章中对应的文本跨度作为答案。
-
模型优化:如果模型的性能不满意,你可以尝试使用更复杂的模型、更大的数据集、不同的训练策略等方法来优化模型。



一个常见的方法是使用双向长短期记忆网络(Bi-LSTM)来完成阅读理解任务,下面是一种可能的步骤:
-
输入准备:将问题和篇章合并,通常在它们之间插入特殊的分隔符,例如"[SEP]",然后使用词嵌入(例如GloVe或Word2Vec)将每个词转换为向量表示。 如果词嵌入在训练过程中被更新,那么它们通常被初始化为预训练的词嵌入。
-
双向LSTM层:将词嵌入输入到双向LSTM层。双向LSTM由两个独立的LSTM组成,一个从左到右处理输入,一个从右到左处理输入。每个LSTM在每个时间步都会输出一个隐藏状态,对应于这个时间步之前(对于从左到右的LSTM)或之后(对于从右到左的LSTM)的上下文信息。
-
合并隐藏状态:将从左到右和从右到左的LSTM在每个时间步的隐藏状态合并,通常通过连接(concatenation)。这样,每个时间步的输出将包含关于这个时间步的词和它在篇章中的上下文的信息。
-
开始和结束位置的预测:将合并后的隐藏状态输入到两个单独的全连接层(或者其他类型的分类器),一个用于预测答案的开始位置,一个用于预测答案的结束位置。 每个全连接层的输出大小等于输入的长度(即篇章的长度),并通过softmax函数转换为概率分布。

在BERT的基础上进行阅读理解任务的一般步骤如下:
-
输入准备:BERT需要特定的输入格式。一般来说,将问题和篇章合并,中间用一个特殊的分隔符"[SEP]“隔开。在输入的最开始添加一个特殊的开始符号”[CLS]“。对于阅读理解任务,输入就形如”[CLS] question [SEP] passage"。然后,使用BERT的预训练词嵌入,将每个词转换为向量表示。
-
BERT编码器:将词向量输入到BERT编码器。BERT编码器是一个由多层Transformer组成的网络。每层Transformer都包含一个自注意力机制(Self-Attention)和一个前馈神经网络。每个Transformer层的输出都会被输入到下一层。
-
开始和结束位置的预测:BERT的输出是每个输入词的高维向量表示,这些向量同时考虑了词的语义和其上下文信息。为了预测答案的开始和结束位置,通常会在BERT的输出上添加两个独立的线性分类器,一个用于预测开始位置,另一个用于预测结束位置。
Knowledge-based QA


知识库问答(Knowledge-based QA,简称KB-QA)是问答系统的一种类型,它的工作原理是在一个结构化的知识库中查找和推理出答案。知识库是一个包含大量实体(entities)和关系(relations)的数据库,实体之间的关系通常以图形的形式表示。
知识库问答的基本步骤通常如下:
-
问题解析:首先,需要将输入的自然语言问题解析成一个形式化的查询。这个步骤可能包括命名实体识别(NER)来确定问题中提到的实体,关系抽取来确定问题中提到的关系,以及其他自然语言处理技术如依存解析、词性标注等来理解问题的结构。
-
查询执行:在解析出形式化查询后,该查询将在知识库中执行,以找出可能的答案。查询执行可能涉及到图搜索、逻辑推理等技术。
-
答案生成:根据查询的结果生成答案。如果有多个可能的答案,那么可能需要一个排序或选择模型来决定最好的答案。
知识库问答系统的主要优点是它们可以提供精确的答案,并且可以处理复杂的问题,如涉及到多步推理的问题。然而,它们也有一些挑战,如知识库的覆盖率(即知识库是否包含所有可能的问题的答案)、知识库的更新频率(即知识库是否包含最新的信息)、问题解析的准确性等。
Semantic Parsing 语义解析


Hybrid QA

混合问答(Hybrid QA)是一种结合了多种问答技术和方法的问答系统。它的目标是通过综合不同技术的优点来提供更全面、准确和灵活的答案。
混合问答系统通常结合了以下技术和方法:
-
基于规则的方法:利用人工定义的规则和模式来解析和回答特定类型的问题。这些规则可以是手动编写的,也可以通过机器学习算法学习得到。基于规则的方法通常适用于问题模式比较固定的场景,例如常见的事实型问题。
-
基于统计的方法:利用大规模数据集进行训练的统计模型来预测和生成答案。这些模型可以是基于概率图模型、序列模型、注意力机制等的深度学习模型。基于统计的方法可以处理更复杂的问题,但通常需要大量的标注数据和计算资源。
-
知识库查询:利用结构化的知识库来查找和推理答案。这种方法涉及到查询语言(如SPARQL)和知识库中的实体和关系的查询操作。知识库查询可以提供准确和精确的答案,特别适用于涉及实体和关系的问题。
-
信息检索:利用大规模文本集合进行信息检索,找到与问题相关的文档或段落。信息检索技术如倒排索引、TF-IDF、BM25等可以用于从文本中检索出可能的答案候选。


IBM Watson的混合问答(Hybrid QA)方法是一种结合了基于规则和基于机器学习的技术来构建问答系统的方法。它在处理复杂的问题时利用了规则引擎的灵活性,并结合了机器学习模型的能力来处理更开放和多样的问题。
下面是IBM Watson混合问答方法的一般步骤:
-
知识图谱构建:IBM Watson首先会构建一个知识图谱,其中包含了大量的结构化知识,例如实体、关系、属性等。这些知识以图的形式存储,并通过关系连接实体。
-
规则引擎:IBM Watson使用规则引擎来处理一些具体规则和模式,这些规则可以用于回答一些常见或特定类型的问题。规则引擎可以根据问题的特征和上下文来生成相应的答案。
-
机器学习模型:对于更开放和多样的问题,IBM Watson还使用了机器学习模型来进行答案抽取和生成。这些模型可以基于深度学习、自然语言处理或其他相关技术。模型的训练使用大规模的标注数据,以学习问题和答案之间的关联。
-
答案合并和排名:IBM Watson将规则引擎和机器学习模型的结果进行合并,并根据一定的准则进行答案的排名。这可能涉及到对答案的可信度、置信度和相关性进行评估和比较。
-
反馈和迭代:IBM Watson会收集用户的反馈和问题,用于改进系统的性能。通过用户的反馈,系统可以进行调整和迭代,以提供更准确和满意的答案。文章来源:https://www.toymoban.com/news/detail-483261.html
Evaluation

 文章来源地址https://www.toymoban.com/news/detail-483261.html
文章来源地址https://www.toymoban.com/news/detail-483261.html
到了这里,关于NLP——Question Answering 问答模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!