利用colab实现AI绘画自由
最近AIGC真的很火,除了chatGPT外,AI绘画也是热度不减。最近也是决定抽空上手尝试一下,但奈何我的本本太渣,丐版Mac跑跑数据还行,跑Stable Diffusion根本没戏。所以还是决定白嫖谷歌的colab。
网上关于本地部署的教程很多,最火的例如b站的秋葉大神,mac版的也不少,可自行搜索。当然这些前提是你的电脑有较强的显卡。
快速利用colab部署Stable Diffusion WebUI
必备条件:
- 科学上网:需要顺畅访问colab、以及下载相关资源
- 谷歌账号:申请自己的colab、谷歌硬盘的前提条件
1 进入colab,申请免费的GPU。
直接点击右上角的连接,等分配好了资源后,再去笔记本修改为GPU加速。如下图:

2 点击Stable Diffusion WebUI Colab TW进入一键部署链接
该colab一键部署为巴哈社区的一名中国台湾网友提供,一直在持续更新,所以建议直接点击该链接进行部署,可随时享受最新的改进。
当前只需要关注第2步-设置模型即可。
-
设置SD模型(底模型)
点开2旁边的小三角,在2.1【選擇SD模型組合包】中选择
ChilloutMix_Ni_fix即可。这个模型是用来绘制真人的,当然如果你喜欢别的风格也可以选择别的,或者自己填写模型下载链接(这个在后面再说)
-
设置Embedding + Hypernetwork + LoRA
在2.2【LoRA】中勾选你喜欢的LoRA模型,建议都选上。LoRA模型一般在100M+,占的内存不大。其余的先不管,咱先快速上手后再说。

-
执行脚本
依此点击代码执行程序,全部运行即可。

执行过程中,无论什么警告都连击直接运行就行,中途弹出【连接谷歌硬盘】按操作允许即可。下载模型和配置环境需要一段时间,取决于你科学上网的速度,正常情况下10几分钟就可以了。执行到第5步的时候(在脚本5的地方转圈)你可以点开脚本看一下执行进度,如果出现了WebUI的IP,你就可以点击去了,如下图:

中途可能会出现多次断线重连什么的,不用担心,是正常情况。
这个colab会挂载你的谷歌硬盘,将模型和绘制的图片存在硬盘上,方便以后快速运行和保存绘画成果。当然你也可以选择不挂载谷歌硬盘,这个都在后面统一讲。
开始自由绘画
绘画前准备
-
左上角选择你的模型,例如
Chillo...这个模型。 -
选择SD VAE:
Settings->Stable Diffusion->SD VAE。如果你部署时候选择的底模是ChilloutMix_Ni_fix,这里选择"Automatic"即可(个人还是建议选择【vae-ft-mse-840000-ema-pruned.safetensors】这个VAE,在下载CamelliaMix_2.5D模型中时可以获得)。设置完成记得点击Apply settings -
调用可用模型:点击在txt2img的Geneate下面的红色按钮,然后就会出现可用的各类模型


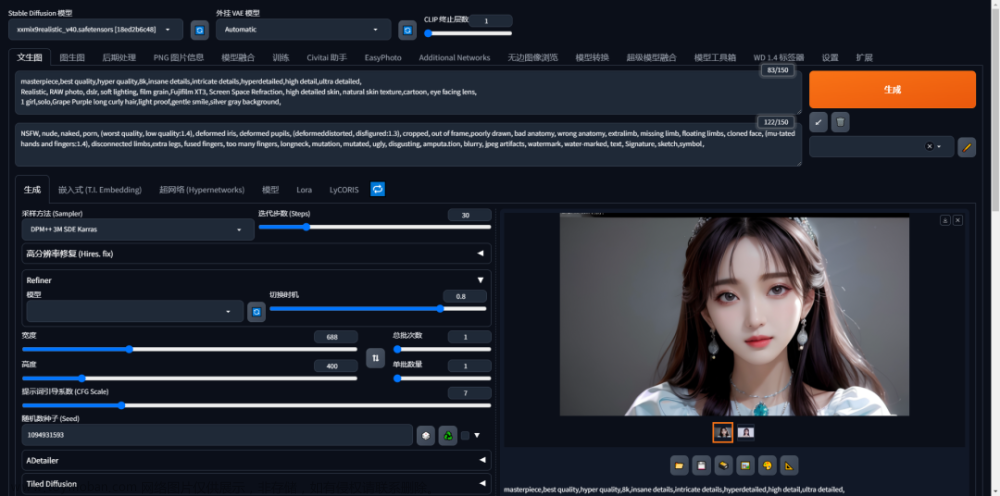
文生图
然后就可以开始自己的创作了,在上面的方框写入正向提示词,下面方框写入反向提示词即可。例如这里简单的写一个beauty girl看看效果,点击Geneate后等待即可。照片默认输出到谷歌硬盘下Stable_Diffusion_WebUI_Colab_TW-outputs里面。
⚠️:由于大部分模型都会生成nsfw的图片,因此在公众环境下(比如上班摸鱼)记得正向提示词添加sfw,反向提示词添加nsfw,避免社死。
如果不绘制了,记得删除实例。因为colab默认允许12小时的GPU运行,超时就会关闭,24小时后才能再度使用,当然你也可以申请多个谷歌账号轮流薅。

一些基础理解
当你开始绘制了自己的第一张图之后,你就需要开始探索如何更好的使用了。建议勾选Restore faces,不建议勾选Hires,因为会造成出图慢。Batch count设置为6,Batch size设置为2,可以一次出12张图。随机种子设置数值大一点。
- 基本参数

-
调用lora
点击lora,选择你需要调用的模型,正向提示词就会出现调用该lora模型的提示词,如下图。模型后面的1是权重,当权重越大(可大于1),越像该lora模型的风格。
实际操作中,如果调用lora过度会显得结果失真扭曲时,可尝试将权重调小。
自定义与进阶
下载喜欢的模型
每个人都有自己喜欢的风格,所以需要一些自定义的底模或者lora模型等,这就需要自己去下载相关的模型了,常见的模型下载地址可以去c站civitai(这个网站有很多模型是NSFW的,在公众场合记得选择safe模式,当然在私密环境下你想怎么玩都可以了~)。
这里可以选择各式各样的模型,其中底模一般为Checkpoint,文件较大(几个G以上)。关于模型的区别,可以详细参考秋葉大神的全部模型种类总结。

不过c站可能出现删模型的情况,有些模型可以在SD models上下载。

下载使用模型有两种方式:
在colab的第2步中对应的位置填写下载链接即可,注意c站的下载链接需要点击进入模型,右键download复制链接。这个下载速度会比较快。
自己手动下载后放置谷歌硬盘的指定位置,大模型放在Stable-diffusion下面。

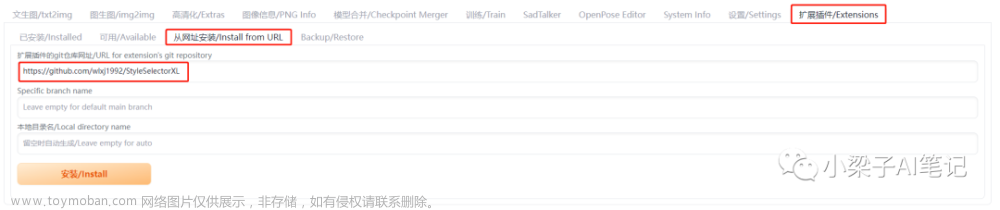
下载扩展
可以在第3步里面填写url,或者手动下载后放在指定位置。可以参考colab原文链接中提到的几个网址

不挂载谷歌硬盘
有的时候,你只是想单纯的尝试一些模型的效果,如果每次模型下载都放到谷歌硬盘,这样存储压力比较大,而且本身只有15G,几个大模型就占满了(虽然你可以手动在谷歌硬盘里删除)。
colab内部有70G以上的空间(看个人分配情况,左下角就能看到磁盘情况),可以下载多个模型,虽然删除实例就会清空,你只要在删除实例前将图片下载下来即可。这个时候图片的位置在drive-MyDrive-Stable_Diffusion_WebUI_Colab_TW-outputs里面。
colab无法直接下载,需要通过脚本。可以在最下方添加如下脚本,就可以将outputs文件夹打包下载下来了,不过下载速度比较慢。
import os, tarfile import os from google.colab import files def make_targz_one_by_one(output_filename, source_dir): tar = tarfile.open(output_filename,"w") for root,dir_name,files_list in os.walk(source_dir): for file in files_list: pathfile = os.path.join(root, file) tar.add(pathfile) tar.close() files.download(output_filename) make_targz_one_by_one('outputs.zip', '/content/drive/MyDrive/Stable_Diffusion_WebUI_Colab_TW/outputs')
实现不挂载也很简单,只需将第1.2步里的这一段注释掉即可。

高质量的prompt
-
参考别人的信息
- c站有很多人分享自己的图片,点击右下角的叹号就能看到图片信息
- 将别人的AI图片拖到webUI里的PNG info
-
参考网站
lexica:一个AI绘画和prompt的搜索引擎
promptoMANIA:智能AI绘画Prompt的在线生成工具
diprompt:真人写实图片信息
无界:咒语生成器
-
借助chatGPT:可以安装【AIPRM for ChatGPT】插件使用,效果一般。应该需要多训练吧
进阶
当你熟练以后,就可以玩一些更加前沿的东西了,例如借助control_net生成指定姿势、炼制自己风格的小模型(炼丹)、图片重绘、精绘、换装等。
当然了,这些我也还不会,所以大家就自己摸索了,网上的资源还是很多的。比较好的就是colab里的巴哈原文,下面推荐了各种类型的教程。
成果分享
接下来,就是展示自己的一些成果了。喜欢的话可以点个赞哈~
3次元:ChilloutMix模型+koreanDollLikeness_v10+taiwanDollLikeness_v10
2.5次元:CamelliaMix_2.5D+koreanDollLikeness_v10+taiwanDollLikeness_v10
2次元:PastalMix模型
总结建议
2次元和2.5次元生成的一般,以后有时间再找好的模型或tag了。
这里给大家一个比较好的咒语,可以帮助大家快速获得高质量的图片。(为了不丢号,把安全词给大伙加上了~)
正向:
((sfw)), <lora:koreanDollLikeness_v10:0.66><lora:taiwanDollLikeness_v10:0.11>, (((2.5D:2.1)))
(8k,RAW photo, best quality, masterpiece:1.2),
(realistic, photo-realistic:1.37), ultra-detailed, film grain, (Fujifilm XT3), ultra high res,
1 girl, solo, cute,
full body, (Kpop idol:1.3), (aegyo sal:1), shiny skin,
(collared shirt:1.1), miniskirt, topless,
twintails, medium hair, floating hair, pigtails, gradient hair,
beautiful detailed eyes, (nose blush), ulzzang, (moe:1.4), grin,
small breasts, cleavage,
(smile:1.1),
((blurry background:1.3)), beautiful street, detailed cafe, a sky full of twinkling stars,
负向:
(((nsfw))),(((NSFW))),EasyNegative,paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2),
lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes,
skin blemishes, age spot, manboobs, backlight,(ugly:1.331),
(duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands,
(poorly drawn hands:1.331), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs,
(disfigured:1.331), (more than 2 nipples:1.331), (missing arms:1.331), (extra legs:1.331),
(fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331),
bad hands, missing fingers, extra digit, (futa:1.1), bad body, NG_DeepNegative_V1_75T,pubic hair, glans
网上有一个比较好的正向提示词的书写风格,参考如下:
画质>>
比较固定,例如最高画质,8k,杰作
风格>>
是照片、动画、写实、幻想
主题>>
主题是一个女孩,还是一只猫
外表>>(从上到下)
衣服(长裙,T恤),
发型(呆毛,双马尾,长发),
发色(棕色),
头部(鼻子,眼睛,耳朵),
颈部(项链),
手臂(露肩),
胸部(中等),
腹部(肚脐),
屁股(蜜桃臀),
腿部(细长,健康),
脚(裸足)
情绪>>
微笑,生气
姿势>>
基础动作(站,坐,跑,走,蹲,趴,跪),
头动作(歪头,仰头,低头),
手动作(手在拢头发,举手),
腰动作(弯腰,鞠躬),
腿动作(二郎腿,盘腿,跪坐),
复合动作(战斗姿态,背对背站)
背景>>
室内,室外,树林,沙滩,星空下,太阳下,天气如何
其他>>
一些具体细节等
参考的参数设置:文章来源:https://www.toymoban.com/news/detail-483550.html
 文章来源地址https://www.toymoban.com/news/detail-483550.html
文章来源地址https://www.toymoban.com/news/detail-483550.html
到了这里,关于利用colab实现AI绘画自由的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!