ChatGPT是继stable diffusion 之后,又一个火出圈的人工智能算法。这火爆程度不仅仅是科研圈子,包括投资圈都为之震惊,大家惊呼人工智能可能真的要取代人类了。网上关于ChatGPT的分析文章已经非常多了,小猿经过高强度的网络冲浪,整理出了AIGC算法演变。

生成模型:让AI也可以有灵魂
AI发展多年,过去解决的多是模态识别的问题,比如最成功的案例就是图像识别了。采用CNN算法,把信息与图能够通过AI训练的方式给训练出来,教会了AI去识别某个模态,在教科书里,被称为判别式模型 (Discriminant Model) 。抽象来看,就是训练一个巨大的神经网络(多层多参数)来实现输入和输出的映射关系。从数学来看,就是学习输入输出的条件概率分布,类似于因果关系。算法的本质是想更准确的控制映射关系。
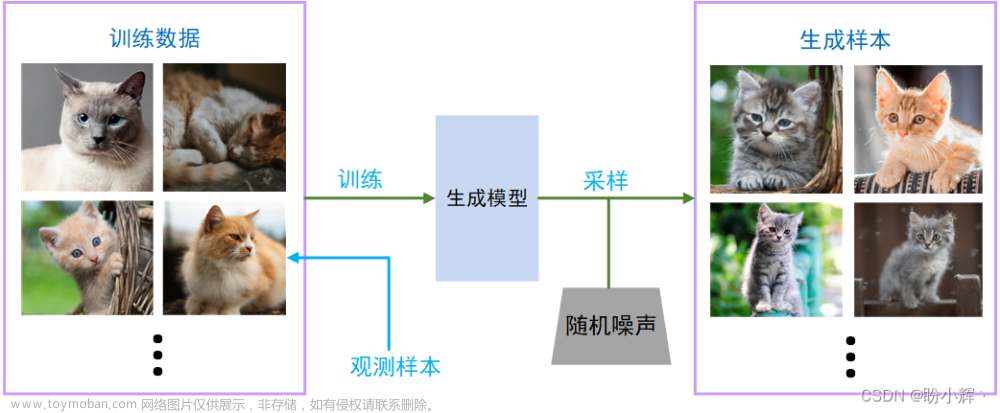
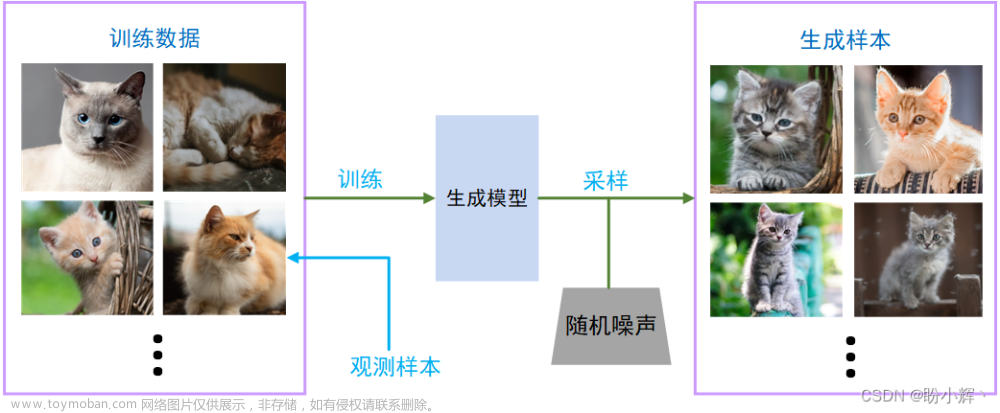
然而,除此之外,还有一种叫生成式模型 (Generative Model), 是学习数据中的联合概率分布,类似于相关性,算法的本质并不是准确控制映射关系,而是在有相关性的基础上学习一个分布。
而生成模型的发展,使得AI变得更多多元,不仅仅可以用于图像识别声音识别这类模态识别问题,还可以实现更多创造性的工作。
Transformer 的横空出世,AIGC(文本)得以飞跃
事实上,在Transformer出来之前,文本也就是NLP的问题一般采用RNN(和语音类似),主要原因是文本有前后序列和语音是类比的。但是这种算法的效果并不好, 也导致NLP过去一直是落后于图像语音的,拿图像来说,CNN算法已经多个变种,已经可以实现非常好的效果,根据Stanford大学的《2022AI Index Report》如下图。Imagenet的图像识别挑战中,图像识别的准确度在2016年就已经超过了人类的标准值了,而最近几年几乎已经达到了峰值。

然而,对于自然语言的推理识别的准确度虽然从Transformer之后,快速提升,但是直到2021年还没有达到人类标准值,当然预计2022年之后肯定是一个大飞跃了。
在2013年,AI研究人员倒腾了一个自然语言处理的处理模型 Word2Vec。顾名思义,“Word2Vec”就是 “word to vector,从词到向量”。研究人员的目标是把一个单词变成一个数学向量,这个数学量在NLP里有个专门的名词,叫做Word Embedding(词嵌入)。
为啥要变成一个向量,出发点也很简单,如果能将每个单词都能表示为数学空间里的一个向量,那理论上,在这个向量空间里比较接近的词,就是意义接近的单词
但问题是利用Word Embedding只能初始化第一层网络参数,和图像处理领域的预训练能有效初始化大多数网络层级不可同日而语。
Transformer: 改变了NLP发展困境
而2017年Google发表的著名文章attention is all you need,提出了transformer模型概念,使得NLP上升了巨大的台阶。Transformer架构的核心是Self-Attention机制,该机制使得Transformer能够有效提取长序列特征,相较于 CNN能够更好的还原全局。文章来源:https://www.toymoban.com/news/detail-483782.html
因为抛弃了传统的RNN模型,彻底规避了RNN不能很好并行计算的困扰,此外,每一步计算不依赖文章来源地址https://www.toymoban.com/news/detail-483782.html
到了这里,关于从ChatGPT说起,AIGC生成模型如何演进的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!