openAI发布了chatgpt,光环一时无两。但是openAI不止有这一个项目,它的其他项目也非常值得我们去研究学习。
今天说说这个whisper项目
https://github.com/openai/whisper
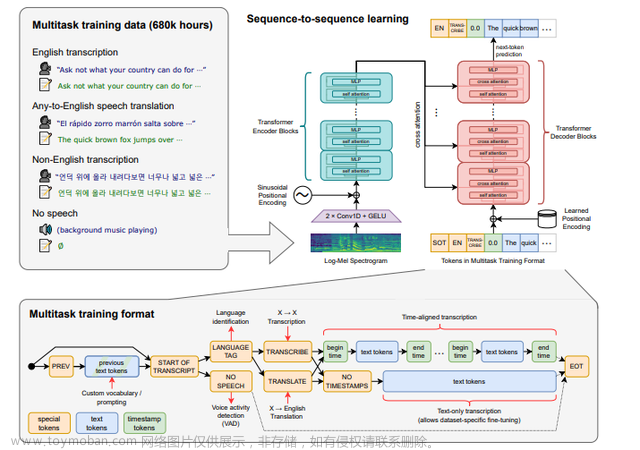
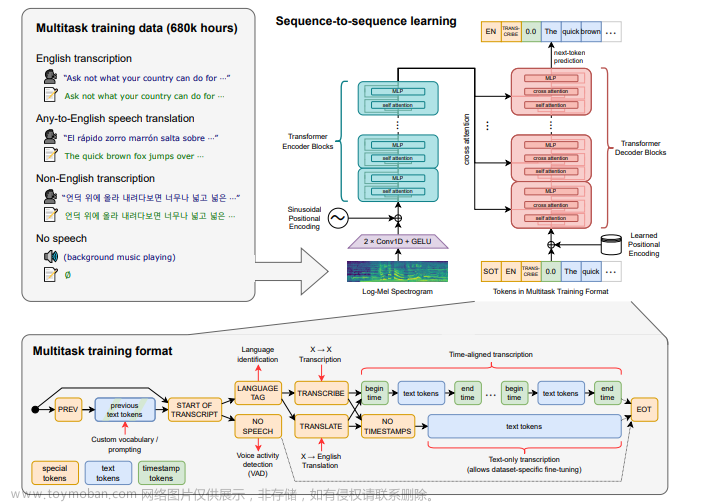
ta是关于语音识别的。它提出了一种通过大规模的弱监督来实现的语音识别的方法。弱监督是指使用不完全或不准确的标签或注释来训练模型的方法。这种方法可以避免手动标注数据的费时费力,同时也可以利用更多的数据来提高模型的性能。
在这个方法中,使用了大量的未标注语音数据和一些已标注的数据来训练一个深度学习模型。这个模型可以自动学习如何从语音信号中提取特征,并将其转换为文本。
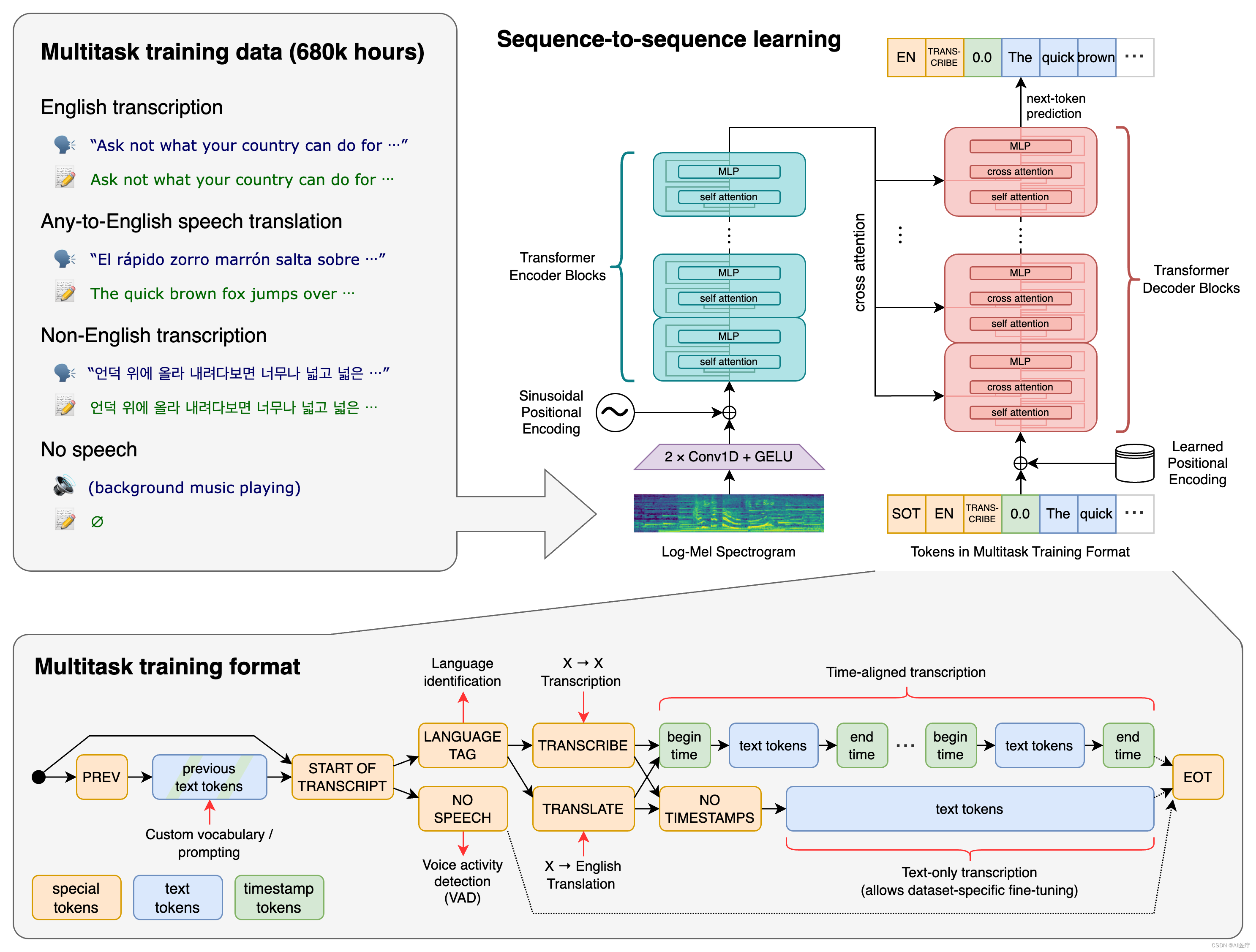
来看看官方的说明:(不管你看不看得懂,反正我是没看懂)
作者用的Python版本为3.9.9,PyTorch版本为1.10.1,但代码库应该与Python 3.8-3.10和最新的PyTorch版本兼容。(我自己试了3.11无法兼容,所以老老实实的用3.9吧)
用法也很简单,简直是调库男孩的最爱。
第一步:安装Python库
python3 -m pip install openai-whisper
第二步安装FFmpeg
# on Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg
# on Arch Linux
sudo pacman -S ffmpeg
# on MacOS using Homebrew (https://brew.sh/)
brew install ffmpeg
# on Windows using Chocolatey (https://chocolatey.org/)
choco install ffmpeg
# on Windows using Scoop (https://scoop.sh/)
scoop install ffmpeg
个人建议在Windows上用Scoop装FFmpeg,Chocolatey太麻烦
第三步,选择使用的模型。
官方说有5种模型,其中4种是English-only模型,但是实测english-only也可以支持中文(只测了base可以支持中文,其他的没测但应该也可以)
虽说支持中文,但是也有不理想的地方,中文的识别错误率(WER (Word Error Rate))还不低,在所有支持语言的大概排中游水平。
第四步,具体使用
有好几种方法:
1、命令行模式
whisper audio.flac audio.mp3 audio.wav --model medium
- 对于非英文语言,加上–language参数,例如日语
whisper japanese.wav --language Japanese
支持的语言类型还挺多的
LANGUAGES = {
"en": "english",
"zh": "chinese",
"de": "german",
"es": "spanish",
"ru": "russian",
"ko": "korean",
"fr": "french",
"ja": "japanese",
"pt": "portuguese",
"tr": "turkish",
"pl": "polish",
"ca": "catalan",
"nl": "dutch",
"ar": "arabic",
"sv": "swedish",
"it": "italian",
"id": "indonesian",
"hi": "hindi",
"fi": "finnish",
"vi": "vietnamese",
"he": "hebrew",
"uk": "ukrainian",
"el": "greek",
"ms": "malay",
"cs": "czech",
"ro": "romanian",
"da": "danish",
"hu": "hungarian",
"ta": "tamil",
"no": "norwegian",
"th": "thai",
"ur": "urdu",
"hr": "croatian",
"bg": "bulgarian",
"lt": "lithuanian",
"la": "latin",
"mi": "maori",
"ml": "malayalam",
"cy": "welsh",
"sk": "slovak",
"te": "telugu",
"fa": "persian",
"lv": "latvian",
"bn": "bengali",
"sr": "serbian",
"az": "azerbaijani",
"sl": "slovenian",
"kn": "kannada",
"et": "estonian",
"mk": "macedonian",
"br": "breton",
"eu": "basque",
"is": "icelandic",
"hy": "armenian",
"ne": "nepali",
"mn": "mongolian",
"bs": "bosnian",
"kk": "kazakh",
"sq": "albanian",
"sw": "swahili",
"gl": "galician",
"mr": "marathi",
"pa": "punjabi",
"si": "sinhala",
"km": "khmer",
"sn": "shona",
"yo": "yoruba",
"so": "somali",
"af": "afrikaans",
"oc": "occitan",
"ka": "georgian",
"be": "belarusian",
"tg": "tajik",
"sd": "sindhi",
"gu": "gujarati",
"am": "amharic",
"yi": "yiddish",
"lo": "lao",
"uz": "uzbek",
"fo": "faroese",
"ht": "haitian creole",
"ps": "pashto",
"tk": "turkmen",
"nn": "nynorsk",
"mt": "maltese",
"sa": "sanskrit",
"lb": "luxembourgish",
"my": "myanmar",
"bo": "tibetan",
"tl": "tagalog",
"mg": "malagasy",
"as": "assamese",
"tt": "tatar",
"haw": "hawaiian",
"ln": "lingala",
"ha": "hausa",
"ba": "bashkir",
"jw": "javanese",
"su": "sundanese",
}
- 加上–task translate参数,会把语音内容翻译成英语
whisper japanese.wav --language Japanese --task translate
- 还有其他问题,可以用help命令
whisper --help
2、Python代码模式
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])
第一次加载模型时,它会联网去拉取模型(也就是上面介绍的五种模型),不同的模型大小不一。拉取完成以后,再用就不用联网了。
tiny------base------small------medium------large,模型规模从小到大,准确率也越来越高,但是所使用的资源也越来越大。根据自己需要选择,一般用small就不错了。
以上,正文结束。
下面说一下我认为的使用场景和槽点
使用场景:
1、提取视频里的音频,转成文字做记录;
2、提取录音笔里的音频,快速查看内容(音频有时候太长了,不如文字阅读速度快)
3、自己做视频或者音频时,想生成字幕也可以用。
优点:
免费、断网可用(环境搭好的情况下),安全无忧,不担心泄露
槽点:
没有实时语音支持、不支持语音合成。文章来源:https://www.toymoban.com/news/detail-484608.html
我其实想做成用本地实时语音转文字,转成文字后,发给ChatGPT,然后ChatGPT返回结果后再合成语音播放出来。但是ta目前做不到实时和语音合成。文章来源地址https://www.toymoban.com/news/detail-484608.html
到了这里,关于openai的whisper语音识别介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!