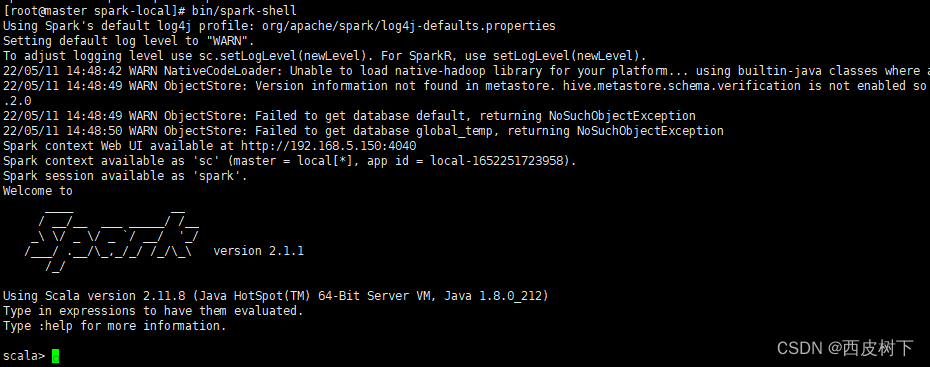
一、安装以及解压缩spark的过程(以下步骤全部都是在master机器上进行的步骤)
安装:文件提取链接:https://pan.baidu.com/s/1XI_mRKY2c6CHlt6--3d7kA?pwd=tlu2
(可以导入至U盘中,再从U盘拷入至虚拟机中,这点在我讲述安装jdk8的文章中有提到过,如果有兴趣,可以去看一下:http://t.csdn.cn/POerk)
- 我把jdk8、hadoop-3.3.4、zookeeper-3.6.2、hbase-2.3.3、spark-3.2.2的解压后的文件放在了“opt”文件里,而它们的压缩包统一放在了“opt”的software文件夹(可以自己创建)中。

- 解压缩spark-3.2.2:





二、配置Spark的环境变量
- bashrc的路径:主文件夹——>其它位置——>计算机——>etc——>bashrc(/etc/bashrc) ;
- workers.template、spark-env.sh template的路径:主文件夹——>其它位置——>计算机——>opt——>spark-3.2.2——>conf(/opt/hbase-2.3.3/conf);
- 第二点的两个文件都需要用文本编辑器打开;
- 这三个文件在关闭之前必须记得保存之后再关闭。
- 在bashrc中增加spark的环境变量(三个虚拟机都需要添加以下内容)
#spark_config export SPARK_HOME=/opt/spark-3.2.2 export PATH=$PATH:$SPARK_HOME/bin
- 修改workers.template的文件名称以及内容
master slave0 slave1

- 修改spark-env.sh template的文件名称以及添加以下内容
export JAVA_HOME=/opt/jdk1.8.0_261 export HADOOP_HOME=/opt/hadoop-3.3.4 export SPARK_MASTER_IP=master export SPARK_MASTER_PORT=7077 export SPARK_DIST_CLASSPATH=$(/opt/hadoop-3.3.4/bin/hadoop classpath) export HADOOP_CONF_DIR=/opt/hadoop-3.3.4/etc/hadoop export SPARK_YARN_USER_ENV="CLASSPATH=/opt/hadoop-3.3.4/etc/hadoop" export YARN_CONF_DIR=/opt/hadoop-3.3.4/etc/hadoop

- 生效bashrc文件(三台虚拟机在修改完bashrc文件后,都需要在终端中对bashrc进行生效)
source /etc/bashrc
三、 master远程发送文件给slave0和slave1
这一步骤在之前的安装jdk、hadoop、zookeeper、hbase都有提到过,如果有兴趣的话,可以去看一下:http://t.csdn.cn/qhTlj
四、启动Spark
- 在启动spark之前,需要启动hadoop、zookeeper和hbase,因为spark也是需要架构在hadoop基础上的。(启动hadoop、zookeeper、hbase可以去查看一下之前的文章:http://t.csdn.cn/qhTlj,我都有提到过);
- 启动路径:/opt/spark-3.2.2/sbin/start-all.sh;
- 启动命令:./start-all.sh;
- 启动spark后,jsp进程master会出现Master与Worker,slave0与slave1出现的是Worker。

五、运行SparkPI
[root@master spark-3.2.2]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 examples/jars/spark-examples_2.12-3.2.2.jar

六、关闭Spark
 文章来源:https://www.toymoban.com/news/detail-485033.html
文章来源:https://www.toymoban.com/news/detail-485033.html
- 以上就是linux安装spark的全部过程了,如遇问题可以留言或者私信。
文章来源地址https://www.toymoban.com/news/detail-485033.html
到了这里,关于Linux安装Spark的详细过程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!