1、激活函数的作用
1.不带激活函数的单层感知机是一个线性分类器,不能解决线性不可分的问题
2.合并后的多个感知器本质上还是一个线性分类器,还是解决不了非线性的问题
3.激活函数是用来加入非线性因素的,提高神经网络对模型的表达能力,解决线性模型所不能解决的问题。
2、常见激活函数
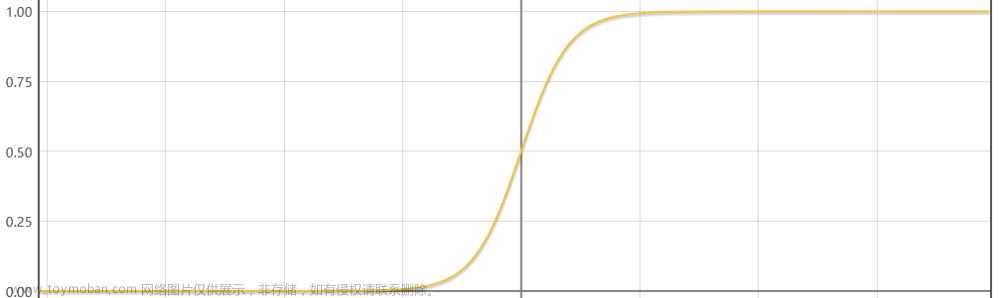
1.sigmiod
f(x)=1/(1+e^-x)
特点:sigmiod的输出范围为[0,1],适用于作为预测概率输出。梯度平滑,避免跳跃的输出值,函数可微,可以找到任意两个点的 sigmoid 曲线的斜率。
缺点:在深度神经网络中梯度反向传递时导致梯度爆炸和梯度消失,其中梯度爆炸发生的概率非常小,而梯度消失发生的概率比较大,其导函数的取值范围在[0,0.25]之间。函数输出不是以 0 为中心的,导致倒数均大于0,这会降低权重更新的效率。Sigmoid 函数执行指数运算,计算机运行得较慢。
2.tanh
f(x)=2/(1+e^-2x)-1
特点:tanh 是一个双曲正切函数。tanh 函数和 sigmoid 函数的曲线相对相似。但是它比 sigmoid 函数更有一些优势。tanh 的输出 区间为[-1,1] ,并且整个函数以 0 为中心,比 sigmoid 函数更好;在 tanh 图中,负输入将被强映射为负,而零输入被映射为接近零。
缺点:它解决了Sigmoid函数的不是zero-centered输出问题,然而,梯度消失(gradient vanishing)的问题和幂运算的问题仍然存在
注意:在一般的二元分类问题中,tanh 函数用于隐藏层,而 sigmoid 函数用于输出层,但这并不是固定的,需要根据特定问题进行调整。
3.relu (dead relu)
f(x)=max(0,x)
特点:
ReLU函数其实就是一个取最大值函数,注意这并不是全区间可导的,但是我们可以取sub-gradient。ReLU虽然简单,但却是近几年的重要成果,有以下几大优点:
1) 解决了gradient vanishing问题 (在正区间)
2)计算速度非常快,只需要判断输入是否大于0
3)收敛速度远快于sigmoid和tanh
缺点:
1)ReLU的输出不是zero-centered
2)Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生: (1) 非常不幸的参数初始化,这种情况比较少见 (2) learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
4.leaky relu (prelu)
f(x)=max(αx,x)
人们为了解决Dead ReLU Problem,提出了将ReLU的前半段设为αx而非0,通常α=0.01。另外一种直观的想法是基于参数的方法,即ParametricReLU:f(x)=max(αx,x),其中α可由方向传播算法学出来。
5.elu
ELU也是为解决ReLU存在的问题而提出,显然,ELU有ReLU的基本所有优点,不会出现dead relu问题,输出均值接近0,zero-centered
6.softmax
f(x)=e^x_i/sum(x_j)
特点:
Softmax 与正常的 max 函数不同:max 函数仅输出最大值,但 Softmax 确保较小的值具有较小的概率,并且不会直接丢弃。我们可以认为它是 argmax 函数的概率版本或「soft」版本。
Softmax 函数的分母结合了原始输出值的所有因子,这意味着 Softmax 函数获得的各种概率彼此相关。
缺点:
在零点不可微。负输入的梯度为零,对于该区域的激活,权重不会在反向传播期间更新,会产生永不激活的死亡神经元。
7.Swish
f(x)=x * sigmoid (x)
特点:
Swish 的设计受到 LSTM 和 highway network 中使用 sigmoid 函数进行门控的启发。我们使用同样的值进行门控来简化门控机制,称为自门控(self-gating)。自门控的优势是它仅需要一个简单的标量输入,而正常的门控需要多个标量输入。该特性令使用自门控的激活函数如 Swish 能够轻松替换以单个标量作为输入的激活函数(如 ReLU),无需改变参数的隐藏容量或数量。
Swish 是一种新型激活函数,公式为: f(x) = x · sigmoid(x)。Swish 具备无上界有下界、平滑、非单调的特性,这些都在 Swish 和类似激活函数的性能中发挥有利影响。我们在实验中使用了专为 ReLU 设计的模型和超参数,然后用 Swish 替换掉 ReLU 激活函数;仅仅是如此简单、非最优的迭代步数仍使得 Swish 持续优于 ReLU 和其他激活函数。我们期待当模型和超参数都专为 Swish 设计的时候,Swish 还能取得进一步的提升。Swish 的简洁性及其与 ReLU 的相似性意味着在任何网络中替代 ReLU 都只是改变一行代码这么简单的事。
8.maxout
Maxout是深度学习网络中的一层网络,就像池化层、卷积层一样等,我们可以把maxout 看成是网络的激活函数层
maxout network的TensorFlow实现 - 简书
9.softplus
f(x)= ln(1+e^x)
特点:softplus其导函数是sigmiod函数,Softplus 函数类似于 ReLU 函数,但是相对较平滑,像 ReLU 一样是单侧抑制。它的接受范围很广:(0, + inf)。
10.softsign函数
f(x)=x/(1+|x|)
Softsign函数是Tanh函数的另一个替代选择。就像Tanh函数一样,Softsign函数是反对称、去中心、可微分,并返回-1和1之间的值。其更平坦的曲线与更慢的下降导数表明它可以更高效地学习,比tanh函数更好的解决梯度消失的问题。另一方面,Softsign函数的导数的计算比Tanh函数更麻烦。
11.gelu
f(x)=xP(X<=x)=xΦ(x)
Φ(x)是正太分布的概率函数,可以简单采用正太分布N(0,1), 也可以使用参数化的正太分布N(μ,σ), 然后通过训练得到μ,σ
论文中提供的正太分布的近似计算如下:
Φ(x)=0.5x(1+tanh[2/π(x+0.044715x3)])
在神经网络的建模过程中,模型很重要的性质就是非线性,同时为了模型泛化能力,需要加入随机正则,例如dropout(随机置一些输出为0,其实也是一种变相的随机非线性激活), 而随机正则与非线性激活是分开的两个事情, 而其实模型的输入是由非线性激活与随机正则两者共同决定的。
GELUs正是在激活中引入了随机正则的思想,是一种对神经元输入的概率描述,直观上更符合自然的认识,同时实验效果要比Relus与ELUs都要好。
优点:
- 似乎是 NLP 领域的当前最佳;尤其在 Transformer 模型中表现最好;
- 能避免梯度消失问题。
缺点:
- 尽管是 2016 年提出的,但在实际应用中还是一个相当新颖的激活函数。
3、激活函数tf实现
1.sigmiod
y=tf.sigmoid(x)2.tanh
y=tf.tanh(x)3.relu (dead relu)
y=tf.nn.relu(x)4.leaky relu (prelu)
y=tf.nn.leaky_relu(x)5.elu
y=tf.nn.elu(x)6.softmax
y=tf.nn.softmax(x)7.Swish
y=tf.nn.swish(x)
8.maxout
def maxout(x, k, m):
d = x.get_shape().as_list()[-1]
W = tf.Variable(tf.random_normal(shape=[d, m, k]))
b = tf.Variable(tf.random_normal(shape = [m, k]))
z = tf.tensordot(x, W, axes=1) + b
z = tf.reduce_max(z, axis=2)
return z9.softplus
y=tf.nn.softplus(x)
10.softsign函数
y=tf.nn.softsign(x)
10.gelu
def gelu(input_tensor):
cdf = 0.5 * (1.0 + tf.erf(input_tensor / tf.sqrt(2.0)))
return input_tesnsor*cdf
参考文献
1、
深度学习领域最常用的10个激活函数,一文详解数学原理及优缺点 | 机器之心
2、sigmoid,softmax,tanh简单实现_dongcjava的博客-CSDN博客
3、神经网络激活函数的作用是什么?_Microstrong0305的博客-CSDN博客_神经网络激活函数的作用
4、BERT中的激活函数GELU:高斯误差线性单元 - 知乎
5、常用激活函数(激励函数)理解与总结_tyhj_sf的博客-CSDN博客_激活函数
6、softsign与tanh的比较_Takoony的博客-CSDN博客_softsign
7、谷歌大脑提出新型激活函数Swish惹争议:可直接替换并优于ReLU?(附机器之心测试) - 知乎
8、机器学习中的数学——激活函数(十二):高斯误差线性单元(GELUs)_von Neumann的博客-CSDN博客
9、GELU 激活函数_alwayschasing的博客-CSDN博客_gelu激活函数
10、tensorflow中常用激活函数和损失函数 - Fate0729 - 博客园文章来源:https://www.toymoban.com/news/detail-485255.html
11、maxout network的TensorFlow实现 - 简书文章来源地址https://www.toymoban.com/news/detail-485255.html
到了这里,关于激活函数简述的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!