过去一周,AI大模型的快速演进仍然在继续上演。今天继续介绍GitHub上的一些实用的大模型开源项目。
1. ChatGLM-6B:Open Source ChatGPT Alternative
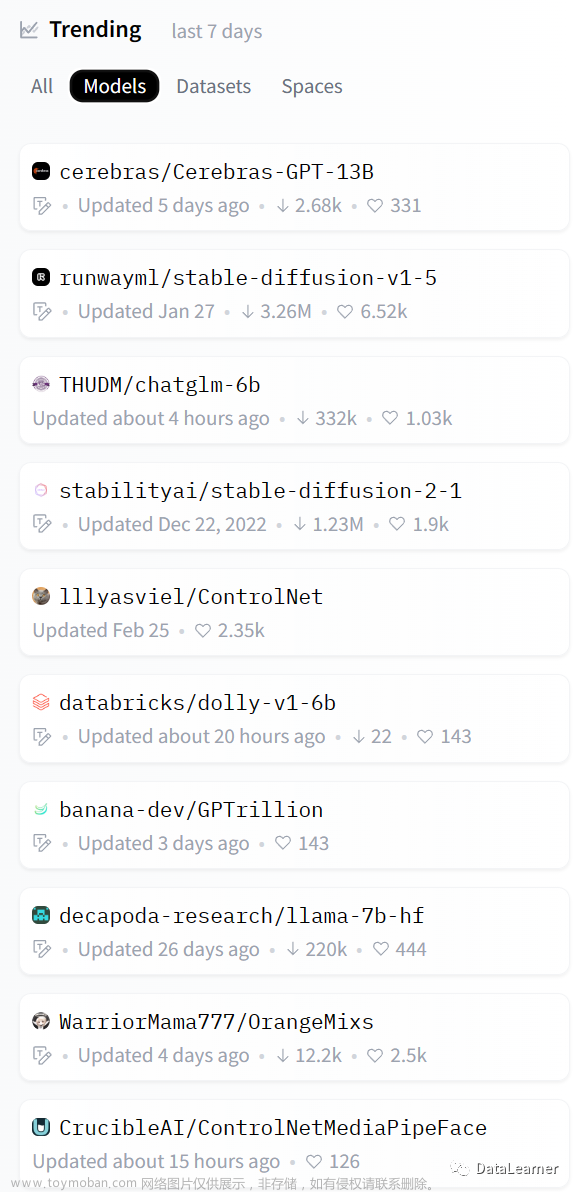
ChatGLM-6B是一个基于GLM架构的开源对话语言模型,支持中英双语,有62亿参数。结合模型量化技术,可以在消费级显卡上本地部署,效果堪比ChatGPT。2023年3月开源,3周时间已经积累超过100万次下载,目前全球接近300万次下载量。
2. CodeGeeX:Open Source Github Copilot Alternative
CodeGeeX是一个基于AI大模型的代码生成神器,拥有130亿参数,支持23种编程语言。CodeGeeX可以根据自然语言或代码片段生成完整的代码,“Ask CodeGeeX”功能可以在IDE中通过对话的方式直接操作代码,开发者普遍认为是Github Copilot的平替产品。CodeGeeX是开源免费的,支持VS Code和IDEAs平台,目前全球安装使用的用户量超过100,000+。
3. Meta open source AI generative music model
这是Meta在GitHub上开源的名为Audiocraft的Python库,可以直接用人工智能生成音乐。其中主要使用了一个名为MusicGen的音乐生成模型。MusicGen是一个基于单阶自回归Transformer的预训练模型,使用32kHz EnCodec tokenizer,并以50Hz采样的方式生成了4个codebooks。
与现有的方法(如MusicLM)不同,MusicGen不需要自监督语义学习,而是一次性生成了所有4个codebooks。在文本生成和文生图之后,看看用文本生成音乐的效果如何。
4. Diffusers发布重要更新
Diffusers v0.17.0正式发布,改进了LoRA、Kandinsky 2.1、Torch编译加速等功能。Diffusers是一个在GitHub上的Diffusion Model预训练模型常用库,广受欢迎,可用于生成图像、音频,甚至是分子的3D结构。
无论是寻找简单的推理解决方案还是训练自己的Diffusion Models,Diffusers作为一个模块化工具包提供支持。
库的设计更注重易用性和可定制性,主要提供以下三个核心组件:
- 先进的Diffusion pipeline,只需几行代码即可进行推理;
- 可互换的noise schedulers,用于不同的Diffusion速度和输出质量;
- 预训练模型可用作构建模块,并与schedulers结合使用,创建自己的端到端Diffusion Systems。
这个项目是由Hugging Face免费开源的,可以使用它来快速训练ControlNet,进一步提高AI绘画的效果和质量。
5. Everything is identifiable
Meta之前在GitHub上开源了一个名为Segment Anything Model的图像分割模型,可以自动实现图像分割。然而,该模型在图像定位方面表现良好,但在图像识别方面的表现却一般。
为此,复旦大学与OPPO的研究人员以及International School of Digital Economy,共同在GitHub上开源了一个基础图像标注模型:Recognize Anything Model (RAM)。采用了一种新的图像标注范式,可以识别各种常见类别。而且用来训练的数据,是通过大规模的图像自动生成文本来进行标注,取代了手动标注。
经过基准评估,RAM的标记能力表现优秀,效果明显优于CLIP和BLIP。有用户认为RAM甚至超过了完全监督的方法,与Google API相当。同时,项目中还包含一个名为Tag2Text的工具,可以批量直接为图像中的指定对象生成标签。如果与Meta的开源SAM模型结合使用,我们可以批量删除图像中的指定对象,进一步提高图像处理效率。文章来源:https://www.toymoban.com/news/detail-486075.html
本文由博客一文多发平台 OpenWrite 发布!文章来源地址https://www.toymoban.com/news/detail-486075.html
到了这里,关于5 Amazing AI Projects, Open Source !的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!