Stable Diffusion v1
stable diffusion是一个潜在的文本到图像的扩散模型,能够在给定任何文本输入的情况下生成照片逼真的图像。
环境配置
https://github.com/CompVis/stable-diffusion.git ( Stable Diffusion v1)
conda env create -f environment.yaml 使用conda创建一个名字为ldm的虚拟环境
conda activate ldm
权重下载
在README.md中,点击权重下载链接时,出现的huggingface页面,有Dataset card、Files and versions和Community,但是找不到ckpt文件。这个时候需要在红色的框中输出"stable-diffusion-v1",转到runwayml/stable-diffusion-v1-5界面。
v1-5用v1-2的权重进行初始化,随后在"laion-aesthetics v2 5+"上以分辨率 512 × 512 512 \times 512 512×512微调了595k步,将文本条件降低了10%,以提高classifier-free guidance sampling。v1-5提供了两个ckpt,v1-5-pruned-emaonly.ckpt,4.27G,使用较少的VRAM,适用于推理。v1-5-pruned.ckpt较重,7.7G,使用更多的VRAM,适合微调。
v1-5-pruned-emaonly.ckpt下载链接: https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt
v1-5-pruned.ckpt下载链接:https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned.ckpt

txt2img
mkdir -p models/ldm/stable-diffusion-v1/
将下载好的v1-5-pruned-emaonly.ckpt模型放到models/ldm/stable-diffusion-v1/文件夹下,并更名为model.ckpt,不然会报找不到model的错误,软链接不行。也可以定义txt2img的ckpt超参数,设定模型的位置。
python scripts/txt2img.py --prompt “a photograph of an astronaut riding a horse” --plms

bug

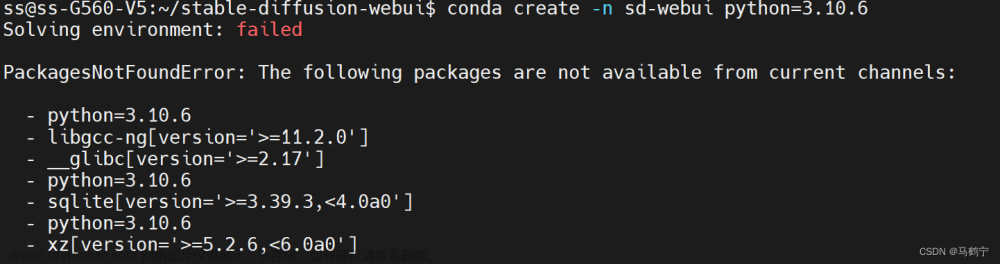
运行txt2img.py时,报上述ImportError错误,受issues_627启发,可能diffusers和transformers的版本太高了,所以降低diffusers和transformers的版本。在environment.yaml中更改diffusers和transformers的版本号,更新conda env update -f environment.yaml,bug消除,正常运行。
diffusers: 0.16.1 —> 0.15.0
transformers: 4.19.2 —>4.28.1
python scripts/txt2img.py --prompt “a photograph of an astronaut riding a horse” --plms
依据提示词"a photograph of an astronaut riding a horse",生成如下六张图片。六张图片中有两张图片宇航员没有骑马,其他四张图片,完成度还不错。
超参数
txt2img的超参数解释如下所示。在推理时,可以通过设定相应的参数得到符合要求的图片。
| 参数 | 用途 |
|---|---|
| prompt | 提示词 |
| outdir | 结果保存文件夹,默认是outputs/txt2img-samples |
| skip_grid | 不保存网格,只保存单个样本。在评估大量样本时很有用 |
| skip_save | 不保存单个样本,用于速度测量 |
| ddim_steps | ddim 采样步骤数 |
| plms | 使用plms采样 |
| laion400m | 使用LAION400M模型 |
| fixed_code | 如果启用,样本见使用相同的起始代码 |
| ddim_eta | ddim eta,默认为0.0,eta=0.0对应于确定性采样 |
| H | 像素空间上的图像高度,默认是512 |
| W | 像素空间上的图像宽度,默认是512 |
| C | 隐藏通道数,默认是4 |
| f | 下采样因子,默认是8 |
| n_samples | 每个给定提示输出的样本数量,又称批次,默认是3 |
| n_rows | 网格中的行,默认是n_samples |
| scale | 无条件制导标度,默认是7.5,eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty)) |
| from-file | 从文件中导入提示词 |
| config | 模型的config文件,默认是"configs/stable-diffusion/v1-inference.yaml" |
| ckpt | 模型checkpoint的位置,默认是"models/ldm/stable-diffusion-v1/model.ckpt" |
| seed | 用于重复取样的种子,默认是42 |
| precision | 以精度进行评估,有"full"和"autocast"两种选择,默认是"autocast" |
当以下面命令行python scripts/txt2img.py --prompt "A classical Chinese Tang Dynasty beauty is drinking tea" --plms --skip_grid运行时,并没有生成上面和宇航员一样的网格图,有四张图片并保存下来。下面是其中生成的最好的照片。典型的唐朝仕女,有茶,但是在喝茶的动作并没有表现出来。
Diffusers
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
下述是上述代码的运行结果展示。

生成结果如下,只生成一个宇航员在火星上,提示词中的horse并没有出现。文章来源:https://www.toymoban.com/news/detail-486082.html
 文章来源地址https://www.toymoban.com/news/detail-486082.html
文章来源地址https://www.toymoban.com/news/detail-486082.html
参考
- CompVis/stable-diffusion
- runwayml/stable-diffusion-v1-5
到了这里,关于【文生图系列】 Stable Diffusion v1复现教程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!