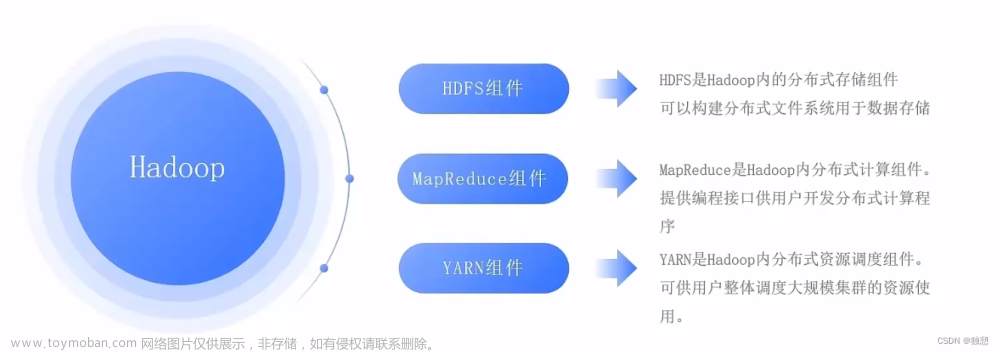
分布式文件系统
分布式文件系统把文件分布存储到多个计算机节点上,通过网络实现文件在多台主机上进行分布式存储的文件系统。
分布式文件系统有两大模式:
- Remote Access Model: 非本地文件不会复制到本地,所以对非本地文件的读取和修改,利用RPC进行。
- Upload/ Download Model:所有非本地文件无论在读取还是修改,都首先会复制到本地。如果在本地进行了修改,则会在关闭了本地的文件后,更新服务器的文件。
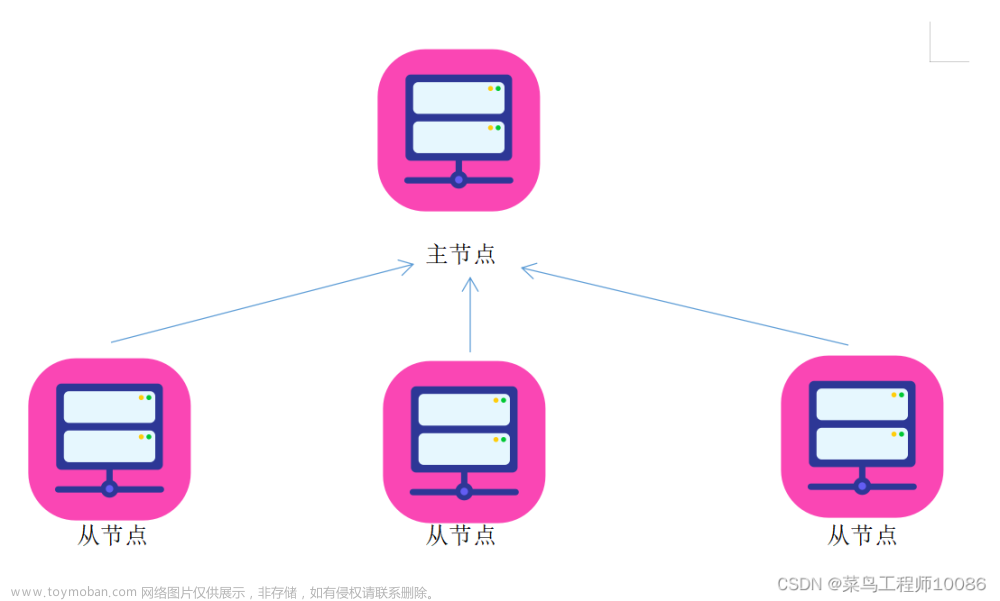
计算机集群结构
目前的分布式文件系统所采用的计算机集群,都是由普通硬件构成的,大大降低了硬件上的开销。
分布式文件系统的结构
分布式文件系统在物理结构上是由计算机集群中的多个节点构成的,这些节点分为两类:
一类叫**“主节点”(Master Node)或者也被称为“名称结点”(NameNode)**
另一类叫**“从节点”(Slave Node)或者也被称为“数据节点”(DataNode)**
分布式文件系统的设计需求
设计目标:透明性、并发控制、可伸缩性、容错及安全需求等。
透明性:
- 包括访问透明性、位置透明性、性能和伸缩透明性
- 访问透明性:用户不需要专门区分哪些是本地文件,哪些是远程文件。用户能够通过相同的操作来访问本地和远程文件资源。
- 位置透明性:不改变路径名的前提下,不管文件副本数量和实际存储位置发生何种变化,对用户而言都是透明的。
- 性能和伸缩透明性:系统中节点的增加和减少以及性能的变化对用户而言是透明的,用户感觉不到什么时候节点加入或退出。
- HDFS 只能提供一定程度的访问透明性,完全的位置透明性、性能和伸缩透明性,HDFS提供的访问的透明性是不完全的。

HDFS简介
HDFS要实现以下目标:
- 兼容廉价的硬件设备
- 流数据访问:一次写入、多次读取
- 大数据集
- 简单的文件模型
- 强大的跨平台兼容性
与之俱来的局限性:
- 不适合低延迟数据访问:几十ms范围的,HDFS以数据以数据呑吐量为目标,可能会提高时间的延迟。
- 无法高效存储大量小文件:namenode将文件系统的元数据保存在内存中,因此文件系统存储的文件总数有限。
- 不支持多用户写入及任意修改文件
HDFS相关概念
块
- 数据磁盘读写的最小单位是块。
- 一个文件被分成多个块,以块作为存储单位。
- 块的大小远远大于普通文件系统,可以最小化寻址开销。
- HDFS默认一个块64MB(1.0)、128M(2.X)。
- 磁盘传输速率为200MB/s时,一般设定block大小为256MB。
- 磁盘传输速率为400MB/s时,一般设定block大小为512MB。
HDFS采用抽象的块概念可以带来以下几个明显的好处:
- 支持大规模文件存储:文件以块为单位进行存储,一个大规模文件可以被分拆成若干个文件块,不同的文件块可以被分发到不同的节点上。
- 简化系统设计:
首先,大大简化了存储管理,因为文件块大小是固定的,这样就可以很容易计算出一个节点可以存储多少文件块;
其次,方便了元数据的管理,元数据不需要和文件块一起存储,可以由其他系统负责管理元数据。 - 适合数据备份:每个文件块都可以冗余存储到多个节点上,大大提高了系统的容错性和可用性。
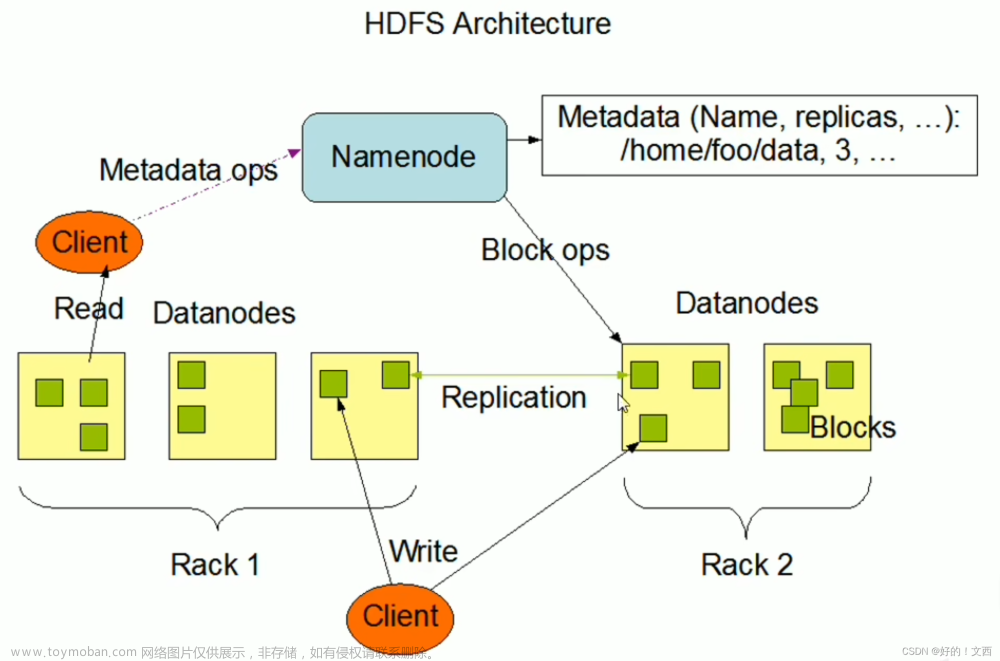
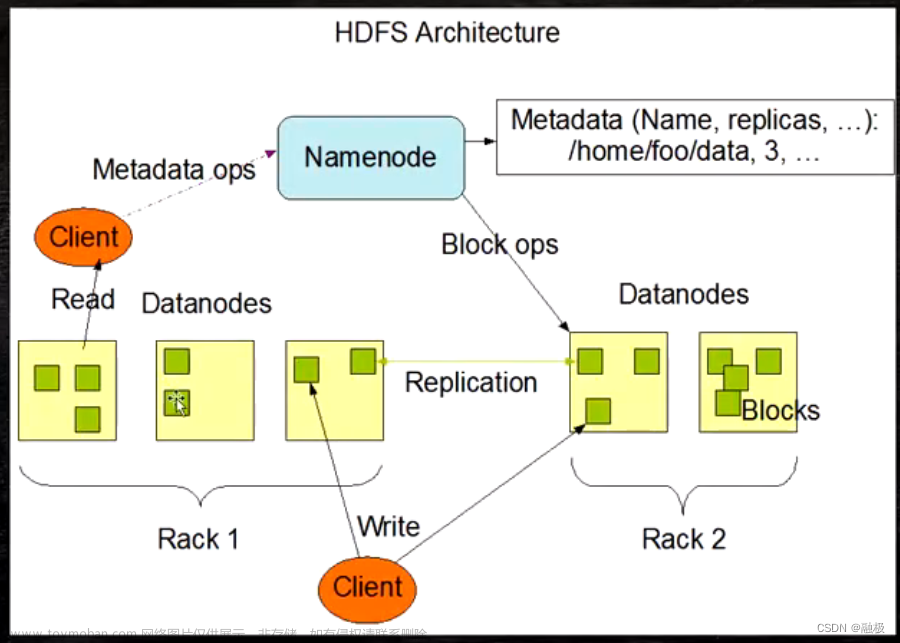
HDFS总体框架
HDFS Client、NameNode、DataNode、Secondary NameNode
HDFS Client
- 文件切分,文件上传 HDFS 的时候,Client 将文件切分成一个一个的Block,然后进行存储
- 与 NameNode 交互,获取文件的位置信息
- 与 DataNode 交互,读取或者写入数据
- Client 提供一些命令来管理 HDFS,比如启动或者关闭HDFS
- Client 可以通过一些命令来访问 HDFS
名称节点和数据节点
HDFS集群中有两类节点,管理节点-工作节点模式。
一个Namenode,多个Datanode。
- NameNode
master,一个管理者,不实际存储数据
管理 HDFS 的名称空间,维护着文件系统树以及整个树的所有文件和目录(fsimage+edits)
管理数据块(Block)映射信息
配置副本策略
处理客户端读写请求 - DataNode
Slave,NameNode 下达命令,DataNode 执行实际的操作
存储实际的数据块
执行数据块的读/写操作
名称节点
- Namenode管理文件系统的命名空间,维护文件系统树及树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘,FsImage镜像文件,EditLog日志文件。
- Namenode也记录每个文件中各个块所在的数据节点信息,但并不永久保存块的位置信息,这些信息会在系统启动时根据数据节点信息重建。

- NameNode在内存中保存着整个文件系统的名称空间和文件数据块的地址映射。
- 整个HDFS可存储的文件数受限于NameNode的内存大小。
- NameNode元数据信息:
文件名,文件目录结构,文件属性(生成时间,副本数,权限)每个文件的快列表。
以及列表中的块与块所在的DataNode之间的地址映射关系,在内存中加载文件系统中
每个文件和每个数据块的引用关系数据会定期保存到本地磁盘(fsimage文件和edits文件) - 元数据是Namenode进行管理的信息
维护HDFS中文件和目录的信息,包括文件名、目录名、父目录信息、文件大小、创建时间、修改时间等。
文件内容,文件分块信息、副本个数、副本所在的位置等。
Datanode的所有信息。
NameNode文件操作
NameNode负责文件元数据的操作,DataNode负责处理文件内容的读写请求,数据流不经过NameNode,会询问它与哪个DataNode联系
NameNode副本
文件数据块到底存放到哪些DataNode上,是由NameNode决定,NameNode根据全局情况做出放置副本的决定。
NameNode心跳机制
- 全权管理数据块的复制,周期性的接受心跳和块的状态报告信息(包含该DataNode上所有数据块的列表)。
- 若接受到心跳信息,NameNode认为DataNode工作正常,如果在10分钟后还接受不到DataNode的心跳,那么NameNode认为DataNode已经宕机,这个时候NameNode准备把DataNode上的数据块进行重新的复制。
- 块的状态报告包含了一个DataNode所有数据块的列表,blocks report每个1个小时发送一次。
FsImage和Editblog
每个文件和每个数据块的引用关系数据会定期保存到本地磁盘(fsimage文件和edits文件)
FsImage文件
- FsImage文件包含文件系统中所有目录和文件inode的序列化形式。每个inode是一个文件或目录的元数据的内部表示,并包含此类信息:文件的复制等级、修改和访问时间、访问权限、块大小以及组成文件的块。对于目录,则存储修改时间、权限和配额元数据。
- FsImage文件没有记录每个块存储在哪个数据节点。而是由名称节点把这些映射信息保留在内存中,当数据节点加入HDFS集群时,数据节点会把自己所包含的块列表告知给名称节点,此后会定期执行这种告知操作,以确保名称节点的块映射是最新的。
名称节点的启动
- 在Namenode启动的时候,它会将FsImage文件中的内容加载到内存中,之后再执行EditLog文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作。
- 一旦在内存中成功建立文件系统元数据的映射,则创建一个新的FsImage文件和一个空的EditLog文件。
- 名称节点起来之后,HDFS中的更新操作会重新写到EditLog文件中,因为FsImage文件一般都很大(GB级别的很常见),如果所有的更新操作都往FsImage文件中添加,这样会导致系统运行的十分缓慢,但是,如果往EditLog文件里面写就不会这样,因为EditLog 要小很多。每次执行写操作之后,且在向客户端发送成功代码之前,Edits文件都需要同步更新。
名称节点的容错
Namenode的容错非常重要,Hadoop提供了两种机制:
- 第一种方式是将持久化存储在本地硬盘的文件系统元数据备份。hadoop可以通过配置来让Namenode将他的持久化状态文件写到不同的文件系统中。这种写操作是同步并且是原子化的。比较常见的配置是在将持久化状态写到本地硬盘的同时,也写入到一个远程挂载的网络文件系统。
- 第二种方式是运行一个辅助的Namenode(Secondary Namenode)。 事实上Secondary Namenode并不能被用作Namenode,它的主要作用是定期的将Namespace镜像与操作日志文件(edit log)合并,以防止操作日志文件(edit log)变得过大。通常,Secondary Namenode运行在一个单独的物理机上,因为合并操作需要占用大量的CPU时间以及和Namenode相当的内存。辅助Namenode保存着合并后的Namespace镜像的一个备份,万一哪天Namenode宕机了,这个备份就可以用上了。
数据节点
- 数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表
- 每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中
- 如果没有namenode,文件系统将无法使用。
- 事实上,如果运行namenode的机器毁坏,文件系统上的所有文件将会丢失,因为不知道如何根据datanode重建文件。
DataNode的功能
- DataNode以数据块的形式存储HDFS文件
- DataNode响应HDFS客户端读写请求
- DataNode周期性向NameNode汇报心跳信息
- DataNode周期性向NameNode汇报数据块信息
- DataNode周期性向NameNode汇报缓存数据块信息
第二名称节点
问题引入:
在名称节点运行期间,HDFS的所有更新操作都是直接写到EditLog中,久而久之, EditLog文件将会变得很大。
虽然这对名称节点运行时候是没有什么明显影响的,但是,当名称节点重启的时候,名称节点需要先将FsImage里面的所有内容映像到内存中,然后再一条一条地执行EditLog中的记录,当EditLog文件非常大的时候,会导致名称节点启动操作非常慢,而在这段时间内HDFS系统处于安全模式,一直无法对外提供写操作,影响了用户的使用。
解决方案:
第二名称节点是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。
SecondaryNameNode一般是单独运行在一台机器上。
SecondaryNameNode的功能:
- 辅助NameNode,分担其工作量
- 定期合并fsimage和edits,并推送给NameNode,紧急情况下,可辅助恢复NameNode
SecondaryNameNode的工作情况:
- SecondaryNameNode会定期和NameNode通信,请求其停止使用EditLog文件,暂时将新的写操作写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别。
- SecondaryNameNode通过HTTP GET方式从NameNode上获取到FsImage和EditLog文件,并下载到本地的相应目录下。
- SecondaryNameNode将下载下来的FsImage载入到内存,然后一条一条地执行EditLog文件中的各项更新操作,使得内存中的FsImage保持最新,这个过程就是EditLog和FsImage文件合并。
- SecondaryNameNode执行完上一步操作之后,会通过post方式将新的FsImage文件发送到NameNode节点上。
- NameNode将从SecondaryNameNode接收到的新的FsImage替换旧的FsImage文件,同时将edit.new替换EditLog文件,通过这个过程EditLog就变小了。

注:Fsimage和edits合并
- Fsimage文件包含整个文件系统所有的文件和目录,是文件系统元数据的持久化检查点,当NameNode重启后都需载入fsimage进入内存,恢复到某个检查点,再执行检查点后的编辑日志,进行重建。
- edits是编辑日志文件,记录检查点后所有文件等信息的改动
HDFS存在的问题
- NameNode单点故障,难以应用于在线场景
- NameNode压力过大,且内存受限,影响系统扩展性
其实上述两个问题在分布式开发中普遍存在,集群环境中,写入写出的namenode节点较少,压力普遍存在,尤其是当这个namenode节点只有一个时,一旦发生故障,就算是立即重启也需要较长时间,那么这一段时间内系统无法工作;而且,单个namenode节点内存有限,使得datenode无法扩展。
解决单点故障
HDFS HA:通过主备NameNode解决,如果主NameNode发生故障,则切换到备NameNode上
解决内存受限问题
HDFS Federation(联邦机制)、HA,2.x 支持2个节点的HA,3.0实现了一主多从
①水平扩展,支持多个NameNode;
②每个NameNode分管一部分目录;
③所有NameNode共享所有DataNode存储资源
HDFS体系结构
HDFS体系结构概述
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点(NameNode)和若干个数据节点(DataNode)。
名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。
集群中的数据节点一般是一个节点运行一个数据节点进程,负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、删除和复制等操作。每个数据节点的数据实际上是保存在本地Linux文件系统中。
HDFS命名空间管理
- HDFS的命名空间包含目录、文件和块
- 在HDFS1.0体系结构中,在整个HDFS集群中只有一个命名空间,并且只有唯一的名称节点,该节点负责对这个命名空间进行管理
- HDFS使用的是传统的分级文件体系,因此,用户可以像使用普通文件系统一样,创建、删除目录和文件,在目录间转移文件,重命名文件等
通信协议
- 所有的HDFS通信协议都是构建在TCP/IP协议基础之上的。
- Hadoop在实现时抛弃了JDK自带的RPC实现—RMI,基于IPC模型实现了一个更高效的轻量级RPC。
- RPC 是远程过程调用(Remote Procedure Call),即远程调用其他虚拟机中运行的 java object,RPC 是一种客户端/服务器模式。使用时包括服务端代码和客户端代码,还有我们调用的远程过程对象。
客户端使用客户端协议与名称节点进行交互
客户端通过一个可配置的端口向名称节点主动发起TCP连接
名称节点和数据节点之间则使用数据节点协议进行交互
客户端与数据节点的交互是通过RPC(Remote Procedure Call)来实现的。在设计上,名称节点不会主动发起RPC,而是响应来自客户端和数据节点的RPC请求
HDFS通信协议分为两种:
- Hadoop RPC接口:主要负责连接的管理、节点的管理以及数据的管理,
- 流式接口:主要是数据的读写传输。
不同于流式接口,Hadoop RPC接口是基于protobuf实现的,protobuf是google的一种数据格式。
Hadoop RPC接口主要包括:
- ClientProtocol
- ClientDatanodeProtocol
- DatanodeProtocol
- InterDatanodeProtocol
- NamenodeProtocol
这几个接口是节点间的主要通信接口。
此外,还包括其他的一些涉及安全、HA的接口。
DatanodeProtocol接口:
- datanode和namenode通信的接口。
- 这个接口非常重要,包括datanode启动、注册、心跳应答、数据块读写相关方法。
心跳相关的方法主要是sendHeartbeat(),心跳是默认3秒钟一次。
数据块读写相关的方法,负责管理数据块,比如出现无效的数据块或者写数据过程中节点故障数据没写完等等:
reportBadBlocks()
blockReceivedAndDeleted()
commitBlockSynchronization() - 启动相关的方法主要是四个:
versionRequest():确认namenode和datanode的版本信息是否一致,如果一直,则建立连接
registerDatanode():注册这个datanode节点的,注册了之后namenode中才会有这个节点相关的信息
blockReport()
cacheReport()
通过这四步,datanode就成功启动加入集群了。 - InterDatanodeProtocol接口
datanode之间相互通信的接口,副本通过datanode之间的通信来实现复制,而不是通过namenode同时将文件数据写到三个副本中
ClientDatanodeProtocol协议
客户端进程与Datanode进程之间进行通信所使用的协议
DatanodeProtocol协议
当Datanode进程需要与NameNode进程进行通信是需要基于此协议,例如发送心跳报告和块状态报告
InterDatanodeProtocol协议
是Datanode进程之间进行通信的协议,例如客户端进程启动复制数据块,此时可能需要在Datanode结点之间进行块副本的流水线复制操作。
客户端
客户端是用户操作HDFS最常用的方式,HDFS在部署时都提供了客户端
HDFS客户端是一个库,暴露了HDFS文件系统接口,这些接口隐藏了HDFS实现中的大部分复杂性
严格来说,客户端并不算是HDFS的一部分
客户端可以支持打开、读取、写入等常见的操作,并且提供了类似Shell的命令行方式来访问HDFS中的数据
此外,HDFS也提供了Java API,作为应用程序访问文件系统的客户端编程接口
HDFS体系结构的局限性
HDFS只设置唯一一个名称节点,这样做虽然大大简化了系统设计,但也带来了一些明显的局限性,具体如下:
(1)命名空间的限制:名称节点是保存在内存中的,因此,名称节点能够容纳的对象(文件、块)的个数会受到内存空间大小的限制。
(2)性能的瓶颈:整个分布式文件系统的吞吐量,受限于单个名称节点的吞吐量。
(3)隔离问题:由于集群中只有一个名称节点,只有一个命名空间,因此,无法对不同应用程序进行隔离。
(4)集群的可用性:一旦这个唯一的名称节点发生故障,会导致整个集群变得不可用。
HDFS存储原理
冗余数据保存
作为一个分布式文件系统,为了保证系统的容错性和可用性,HDFS采用了多副本方式对数据进行冗余存储,通常一个数据块的多个副本会被分布到不同的数据节点上,这种多副本方式具有以下几个优点:
(1)加快数据传输速度
(2)容易检查数据错误
(3)保证数据可靠性
数据存取策略
数据存放
第一个副本:放置在上传文件的数据节点;如果是集群外提交,则随机挑选一台磁盘不太满、CPU不太忙的节点
第二个副本:放置在与第一个副本不同的机架的节点上
第三个副本:与第一个副本相同机架的其他节点上
更多副本:随机节点
数据读取
- HDFS提供了一个API可以确定一个数据节点所属的机架ID,客户端也可以调用API获取自己所属的机架ID
- 当客户端读取数据时,从名称节点获得数据块不同副本的存放位置列表,列表中包含了副本所在的数据节点,可以调用API来确定客户端和这些数据节点所属的机架ID,当发现某个数据块副本对应的机架ID和客户端对应的机架ID相同时,就优先选择该副本读取数据,如果没有发现,就随机选择一个副本读取数据
数据错误与恢复
HDFS具有较高的容错性,可以兼容廉价的硬件,它把硬件出错看作一种常态,而不是异常,并设计了相应的机制检测数据错误和进行自动恢复,主要包括以下几种情形:名称节点出错、数据节点出错和数据出错。
名称节点出错
名称节点保存了所有的元数据信息,其中,最核心的两大数据结构是FsImage和Editlog,如果这两个文件发生损坏,那么整个HDFS实例将失效。因此,HDFS设置了备份机制,把这些核心文件同步复制到备份服务器SecondaryNameNode上。当名称节点出错时,就可以根据备份服务器SecondaryNameNode中的FsImage和Editlog数据进行恢复。
数据节点出错
- 每个数据节点会定期向名称节点发送“心跳”信息,向名称节点报告自己的状态
- 当数据节点发生故障,或者网络发生断网时,名称节点就无法收到来自一些数据节点的心跳信息,这时,这些数据节点就会被标记为“宕机”,节点上面的所有数据都会被标记为“不可读”,名称节点不会再给它们发送任何I/O请求
- 这时,有可能出现一种情形,即由于一些数据节点的不可用,会导致一些数据块的副本数量小于冗余因子
- 名称节点会定期检查这种情况,一旦发现某个数据块的副本数量小于冗余因子,就会启动数据冗余复制,为它生成新的副本
- HDFS和其它分布式文件系统的最大区别就是可以调整冗余数据的位置
数据出错
- 网络传输和磁盘错误等因素,都会造成数据错误
- 客户端在读取到数据后,会采用md5和sha1对数据块进行校验,以确定读取到正确的数据
- 在文件被创建时,客户端就会对每一个文件块进行信息摘录,并把这些信息写入到同一个路径的隐藏文件里面
- 当客户端读取文件的时候,会先读取该信息文件,然后,利用该信息文件对每个读取的数据块进行校验,如果校验出错,客户端就会请求到另外一个数据节点读取该文件块,并且向名称节点报告这个文件块有错误,名称节点会定期检查并且重新复制这个块
HDFS数据读写过程
- FileSystem是一个通用文件系统的抽象基类,可以被分布式文件系统继承,所有可能使用Hadoop文件系统的代码,都要使用这个类。
- Hadoop为FileSystem这个抽象类提供了多种具体实现
- DistributedFileSystem就是FileSystem在HDFS文件系统中的具体实现
- FileSystem的open()方法返回的是一个文件输入流FSDataInputStream对象,在HDFS文件系统中,具体的输入流就是DFSInputStream。
- 到达块的末端时,DFSInputStream关闭与datanode的连接,然后寻找下一个块的最佳datanode。Namenode告诉客户端每个块所在的最佳datanode。
- FileSystem中的create()方法返回的是一个输出流FSDataOutputStream对象,在HDFS文件系统中,具体的输出流就是DFSOutputStream。
- DistributedFileSystem调用Create()方法新建文件,对namenode创建一个RPC调用,在系统的命名空间新建一个文件,datanode中还没有数据块,namenode进行验证,如果通过,创建记录,否则抛出异常。
- 成功返回FSDataOutputStream,开始写入数据,同样, FSDataOutputStream封装了DFSOutputStream对象,负责datanode与namenode的通信。
- 将数据分成一个个数据包,写入内部队列(data queue)。DataStreamer处理数据队列,挑选适合存储数据的一组datanode,并要求namenode分配新的数据块。
- 同时,DFSOutputStream维护一个确认队列。
读数据过程


写数据过程

 文章来源:https://www.toymoban.com/news/detail-486188.html
文章来源:https://www.toymoban.com/news/detail-486188.html
HDFS编程实践
HDFS常用命令
HDFS有很多shell命令,其中,fs命令可以说是HDFS最常用的命令利用该命令可以查看HDFS文件系统的目录结构、上传和下载数据、
创建文件等。
Hadoop中有三种Shell命令方式:文章来源地址https://www.toymoban.com/news/detail-486188.html
- hadoop fs适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
- hadoop dfs只能适用于HDFS文件系统
- hdfs dfs跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
到了这里,关于分布式文件系统HDFS的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!