关注微信公共号:小程在线


关注CSDN博客:程志伟的博客
一、配置workers
[atguigu@hadoop102 hadoop]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
增加以下内容:
hadoop102
hadoop103
hadoop104
[atguigu@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc
二、启动集群
2.1 第一启动,需要在hadoop102节点格式化NameNode。
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
2.2 启动HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
Starting namenodes on [hadoop102]
Starting datanodes
hadoop104: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating.
hadoop103: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating.
Starting secondary namenodes [hadoop104]
2.3 在配置了ResourceManager的节点(hadoop103)启动YARN
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers
2.4 查看进程
[atguigu@hadoop102 hadoop-3.1.3]$ jps
3765 NameNode
4350 Jps
3999 NodeManager
3871 DataNode
[atguigu@hadoop103 hadoop-3.1.3]$ jps
3490 DataNode
3677 ResourceManager
4462 Jps
3807 NodeManager
[atguigu@hadoop104 hadoop]$ jps
3588 SecondaryNameNode
3957 Jps
3431 NodeManager
3324 DataNode
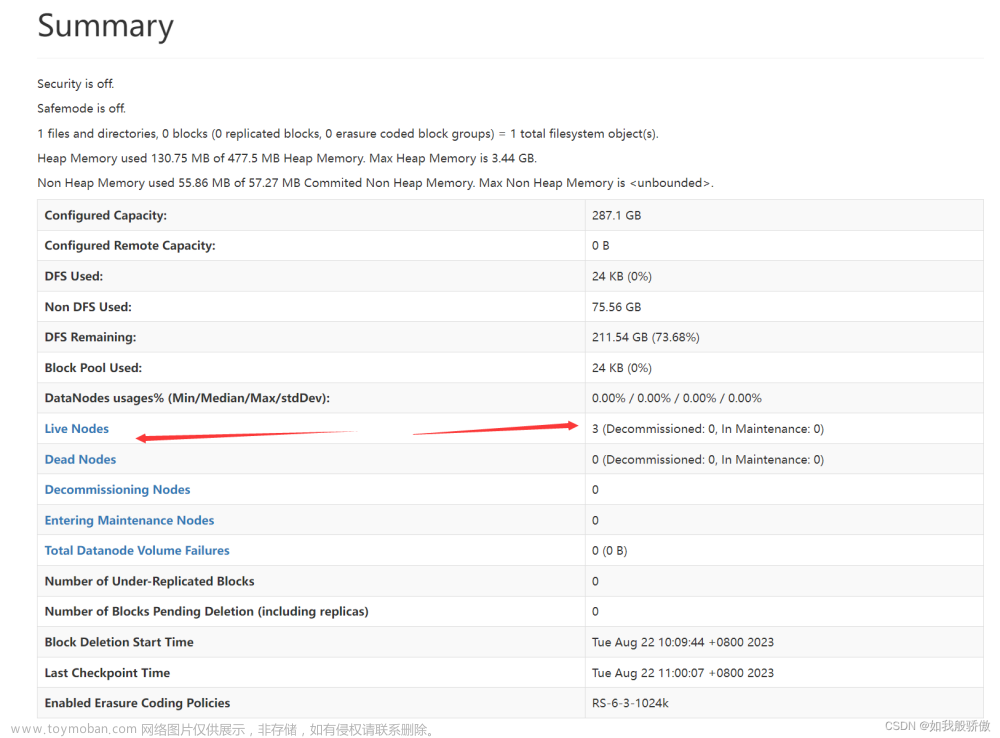
2.5 Web端查看HDFS的NameNode
浏览器中输入:http://hadoop102:9870
2.6 Web端查看YARN的ResourceManager
浏览器中输入:http://hadoop103:8088

三、测试
3.1 创建word.txt
[atguigu@hadoop102 hadoop-3.1.3]$ mkdir wcinput
[atguigu@hadoop102 hadoop-3.1.3]$ cd wcinput
[atguigu@hadoop102 wcinput]$ vim word.txt
hadoop yarn
hadoop mapreduce
atguigu
atguigu
3.2 上传文件
[atguigu@hadoop102 wcinput]$ hadoop fs -put $HADOOP_HOME/wcinput/word.txt /input



[atguigu@hadoop102 wcinput]$ hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /

3.3 上传文件后查看文件存放在什么位置
- 查看HDFS文件存储路径
红色字体表示每个人的位置不一样,需要根据自己的目录调整:pwd
/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-406943879-192.168.10.102-1652083415701/current/finalized/subdir0/subdir0

查看HDFS在磁盘存储文件内容,和上面word.txt文件内容一致
[atguigu@hadoop102 subdir0]$ cat blk_1073741825
hadoop yarn
hadoop mapreduce
atguigu
atguigu
查看JDK
[atguigu@hadoop102 subdir0]$ cat blk_1073741826 >> tmp.tar.gz
[atguigu@hadoop102 subdir0]$ cat blk_1073741827 >> tmp.tar.gz
[atguigu@hadoop102 subdir0]$ tar -zxvf tmp.tar.gz

执行wordcount程序
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
这个界面就可以显示有个任务在执行:
 文章来源:https://www.toymoban.com/news/detail-486234.html
文章来源:https://www.toymoban.com/news/detail-486234.html
 文章来源地址https://www.toymoban.com/news/detail-486234.html
文章来源地址https://www.toymoban.com/news/detail-486234.html
到了这里,关于Hadoop集群搭建--集群启动的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!