-
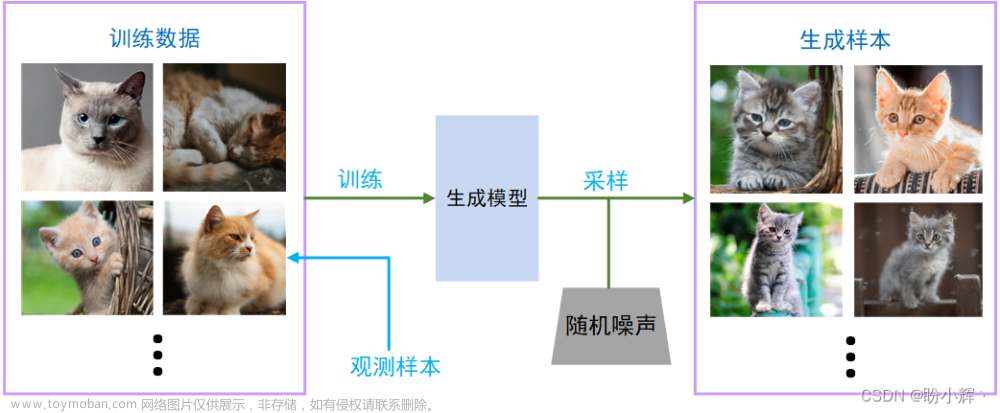
MMagic (Multimodal Advanced, Generative, and Intelligent Creation) 是一个供专业人工智能研究人员和机器学习工程师去处理、编辑和生成图像与视频的开源 AIGC 工具箱。MMagic 支持各种基础生成模型,包括:
-
无条件生成对抗网络 (GANs),条件生成对抗网络 (GANs)
-
内部学习
-
扩散模型…
-
-
自从 MMEditing 诞生以来,它一直是许多图像超分、编辑和生成任务的首选算法库。经过 OpenMMLab 2.0 的迭代更新以及与 MMGeneration 的代码合并,MMEditing 已经成为了一个支持基于 GAN 和传统 CNN 的底层视觉算法的强大工具。MMEditing 正式更名为 MMagic(Multimodal Advanced, Generative, and Intelligent Creation)。
-
针对 Diffusion Model,我们提供了以下“魔法”:
-
支持基于 Stable Diffusion 与 Disco Diffusion 的图像生成;
-
支持 Dreambooth 以及 DreamBooth LoRA 等 Finetune 方法;
-
支持 ControlNet 进行可控性的文本到图像生成;
-
支持 xFormers 加速;
-
支持基于 MultiFrame Render 的视频生成;
-
支持通过 Wrapper 调用 Diffusers 的基础模型以及采样策略
-
-
MMagic可以实现的功能有图文生成;图像翻译;3D 生成;图像超分辨率;视频超分辨率;视频插帧;图像补全;图像抠图;图像修复;图像上色;图像生成等。
-
配置文件按照下面的风格命名
-
{model}_[model setting]_{backbone}_[refiner]_[norm setting]_[misc]_[gpu x batch_per_gpu]_{schedule}_{dataset} -
-
{model}: 模型种类,例如srcnn,dim等等。 -
[model setting]: 特定设置一些模型,例如,输入图像resolution, 训练stage name。 -
{backbone}: 主干网络种类,例如r50(ResNet-50)、x101(ResNeXt-101)。 -
{refiner}: 精炼器种类,例如pln简单精炼器模型 -
[norm_setting]: 指定归一化设置,默认为批归一化,其他归一化可以设为:bn(批归一化),gn(组归一化),syncbn(同步批归一化)。 -
[misc]: 模型中各式各样的设置/插件,例如dconv,gcb,attention,mstrain。 -
[gpu x batch_per_gpu]: GPU数目 和每个 GPU 的样本数, 默认为8x2。 -
{schedule}: 训练策略,如20k,100k等,意思是20k或100k迭代轮数。 -
{dataset}: 数据集,如places(图像补全)、comp1k(抠图)、div2k(图像恢复)和paired(图像生成)。
-
-
-
配置文件 - 生成。对完整的配置和生成系统中的模块有一个基本的了解,对 pix2pix 的配置做如下简要说明。
-
# 模型设置 model = dict( type='Pix2Pix', # 合成器名称 generator=dict( type='UnetGenerator', # 生成器名称 in_channels=3, # 生成器的输入通道数 out_channels=3, # 生成器的输出通道数 num_down=8, # # 生成器中下采样的次数 base_channels=64, # 生成器最后卷积层的通道数 norm_cfg=dict(type='BN'), # 归一化层的配置 use_dropout=True, # 是否在生成器中使用 dropout init_cfg=dict(type='normal', gain=0.02)), # 初始化配置 discriminator=dict( type='PatchDiscriminator', # 判别器的名称 in_channels=6, # 判别器的输入通道数 base_channels=64, # 判别器第一卷积层的通道数 num_conv=3, # 判别器中堆叠的中间卷积层(不包括输入和输出卷积层)的数量 norm_cfg=dict(type='BN'), # 归一化层的配置 init_cfg=dict(type='normal', gain=0.02)), # 初始化配置 gan_loss=dict( type='GANLoss', # GAN 损失的名称 gan_type='vanilla', # GAN 损失的类型 real_label_val=1.0, # GAN 损失函数中真实标签的值 fake_label_val=0.0, # GAN 损失函数中伪造标签的值 loss_weight=1.0), # GAN 损失函数的权重 pixel_loss=dict(type='L1Loss', loss_weight=100.0, reduction='mean')) # 模型训练和测试设置 train_cfg = dict( direction='b2a') # pix2pix 的图像到图像的转换方向 (模型训练的方向,和测试方向一致)。模型默认: a2b test_cfg = dict( direction='b2a', # pix2pix 的图像到图像的转换方向 (模型测试的方向,和训练方向一致)。模型默认: a2b show_input=True) # 保存 pix2pix 的测试图像时是否显示输入的真实图像 # 数据设置 train_dataset_type = 'GenerationPairedDataset' # 训练数据集的类型 val_dataset_type = 'GenerationPairedDataset' # 验证/测试数据集类型 img_norm_cfg = dict(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) # 输入图像归一化配置 train_pipeline = [ dict( type='LoadPairedImageFromFile', # 从文件路径加载图像对 io_backend='disk', # 存储图像的 IO 后端 key='pair', # 查找对应路径的关键词 flag='color'), # 加载图像标志 dict( type='Resize', # 图像大小调整 keys=['img_a', 'img_b'], # 要调整大小的图像的关键词 scale=(286, 286), # 调整图像大小的比例 interpolation='bicubic'), # 调整图像大小时用于插值的算法 dict( type='FixedCrop', # 固定裁剪,在特定位置将配对图像裁剪为特定大小以训练 pix2pix keys=['img_a', 'img_b'], # 要裁剪的图像的关键词 crop_size=(256, 256)), # 裁剪图像的大小 dict( type='Flip', # 翻转图像 keys=['img_a', 'img_b'], # 要翻转的图像的关键词 direction='horizontal'), # 水平或垂直翻转图像 dict( type='RescaleToZeroOne', # 将图像从 [0, 255] 缩放到 [0, 1] keys=['img_a', 'img_b']), # 要重新缩放的图像的关键词 dict( type='Normalize', # 图像归一化 keys=['img_a', 'img_b'], # 要归一化的图像的关键词 to_rgb=True, # 是否将图像通道从 BGR 转换为 RGB **img_norm_cfg), # 图像归一化配置(`img_norm_cfg` 的定义见上文) dict( type='ToTensor', # 将图像转化为 Tensor keys=['img_a', 'img_b']), # 要从图像转换为 Tensor 的图像的关键词 dict( type='Collect', # 决定数据中哪些键应该传递给合成器 keys=['img_a', 'img_b'], # 图像的关键词 meta_keys=['img_a_path', 'img_b_path']) # 图片的元关键词 ] test_pipeline = [ dict( type='LoadPairedImageFromFile', # 从文件路径加载图像对 io_backend='disk', # 存储图像的 IO 后端 key='pair', # 查找对应路径的关键词 flag='color'), # 加载图像标志 dict( type='Resize', # 图像大小调整 keys=['img_a', 'img_b'], # 要调整大小的图像的关键词 scale=(256, 256), # 调整图像大小的比例 interpolation='bicubic'), # 调整图像大小时用于插值的算法 dict( type='RescaleToZeroOne', # 将图像从 [0, 255] 缩放到 [0, 1] keys=['img_a', 'img_b']), # 要重新缩放的图像的关键词 dict( type='Normalize', # 图像归一化 keys=['img_a', 'img_b'], # 要归一化的图像的关键词 to_rgb=True, # 是否将图像通道从 BGR 转换为 RGB **img_norm_cfg), # 图像归一化配置(`img_norm_cfg` 的定义见上文) dict( type='ToTensor', # 将图像转化为 Tensor keys=['img_a', 'img_b']), # 要从图像转换为 Tensor 的图像的关键词 dict( type='Collect', # 决定数据中哪些键应该传递给合成器 keys=['img_a', 'img_b'], # 图像的关键词 meta_keys=['img_a_path', 'img_b_path']) # 图片的元关键词 ] data_root = 'data/pix2pix/facades' # 数据的根路径 data = dict( samples_per_gpu=1, # 单个 GPU 的批量大小 workers_per_gpu=4, # 为每个 GPU 预取数据的 Worker 数 drop_last=True, # 是否丢弃训练中的最后一批数据 val_samples_per_gpu=1, # 验证中单个 GPU 的批量大小 val_workers_per_gpu=0, # 在验证中为每个 GPU 预取数据的 Worker 数 train=dict( # 训练数据集配置 type=train_dataset_type, dataroot=data_root, pipeline=train_pipeline, test_mode=False), val=dict( # 验证数据集配置 type=val_dataset_type, dataroot=data_root, pipeline=test_pipeline, test_mode=True), test=dict( # 测试数据集配置 type=val_dataset_type, dataroot=data_root, pipeline=test_pipeline, test_mode=True)) # 优化器 optimizers = dict( # 用于构建优化器的配置,支持 PyTorch 中所有优化器,且参数与 PyTorch 中对应优化器相同 generator=dict(type='Adam', lr=2e-4, betas=(0.5, 0.999)), discriminator=dict(type='Adam', lr=2e-4, betas=(0.5, 0.999))) # 学习策略 lr_config = dict(policy='Fixed', by_epoch=False) # 用于注册 LrUpdater 钩子的学习率调度程序配置 # 检查点保存 checkpoint_config = dict(interval=4000, save_optimizer=True, by_epoch=False) # 配置检查点钩子,实现参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py evaluation = dict( # 构建验证钩子的配置 interval=4000, # 验证区间 save_image=True) # 是否保存图片 log_config = dict( # 配置注册记录器钩子 interval=100, # 打印日志的时间间隔 hooks=[ dict(type='TextLoggerHook', by_epoch=False), # 用于记录训练过程的记录器 # dict(type='TensorboardLoggerHook') # 还支持 Tensorboard 记录器 ]) visual_config = None # 构建可视化钩子的配置 # 运行设置 total_iters = 80000 # 训练模型的总迭代次数 cudnn_benchmark = True # 设置 cudnn_benchmark dist_params = dict(backend='nccl') # 设置分布式训练的参数,端口也可以设置 log_level = 'INFO' # 日志级别 load_from = None # 从给定路径加载模型作为预训练模型。 这不会恢复训练 resume_from = None # 从给定路径恢复检查点,当检查点被保存时,训练将从该 epoch 恢复 workflow = [('train', 1)] # runner 的工作流程。 [('train', 1)] 表示只有一个工作流程,名为 'train' 的工作流程执行一次。 训练当前生成模型时保持不变 exp_name = 'pix2pix_facades' # 实验名称 work_dir = f'./work_dirs/{exp_name}' # 保存当前实验的模型检查点和日志的目录
-
-
配置文件 - 补全。对完整的配置和修复系统中的模块有一个基本的了解,对 Global&Local 的配置作如下简要说明。
-
model = dict( type='GLInpaintor', # 补全器的名称 encdec=dict( type='GLEncoderDecoder', # 编码器-解码器的名称 encoder=dict(type='GLEncoder', norm_cfg=dict(type='SyncBN')), # 编码器的配置 decoder=dict(type='GLDecoder', norm_cfg=dict(type='SyncBN')), # 解码器的配置 dilation_neck=dict( type='GLDilationNeck', norm_cfg=dict(type='SyncBN'))), # 扩颈的配置 disc=dict( type='GLDiscs', # 判别器的名称 global_disc_cfg=dict( in_channels=3, # 判别器的输入通道数 max_channels=512, # 判别器中的最大通道数 fc_in_channels=512 * 4 * 4, # 最后一个全连接层的输入通道 fc_out_channels=1024, # 最后一个全连接层的输出通道 num_convs=6, # 判别器中使用的卷积数量 norm_cfg=dict(type='SyncBN') # 归一化层的配置 ), local_disc_cfg=dict( in_channels=3, # 判别器的输入通道数 max_channels=512, # 判别器中的最大通道数 fc_in_channels=512 * 4 * 4, # 最后一个全连接层的输入通道 fc_out_channels=1024, # 最后一个全连接层的输出通道 num_convs=5, # 判别器中使用的卷积数量 norm_cfg=dict(type='SyncBN') # 归一化层的配置 ), ), loss_gan=dict( type='GANLoss', # GAN 损失的名称 gan_type='vanilla', # GAN 损失的类型 loss_weight=0.001 # GAN 损失函数的权重 ), loss_l1_hole=dict( type='L1Loss', # L1 损失的类型 loss_weight=1.0 # L1 损失函数的权重 ), pretrained=None) # 预训练权重的路径 train_cfg = dict( disc_step=1, # 训练生成器之前训练判别器的迭代次数 iter_tc=90000, # 预热生成器的迭代次数 iter_td=100000, # 预热判别器的迭代次数 start_iter=0, # 开始的迭代 local_size=(128, 128)) # 图像块的大小 test_cfg = dict(metrics=['l1']) # 测试的配置 dataset_type = 'ImgInpaintingDataset' # 数据集类型 input_shape = (256, 256) # 输入图像的形状 train_pipeline = [ dict(type='LoadImageFromFile', key='gt_img'), # 加载图片的配置 dict( type='LoadMask', # 加载掩码 mask_mode='bbox', # 掩码的类型 mask_config=dict( max_bbox_shape=(128, 128), # 检测框的形状 max_bbox_delta=40, # 检测框高宽的变化 min_margin=20, # 检测框到图片边界的最小距离 img_shape=input_shape)), # 输入图像的形状 dict( type='Crop', # 裁剪 keys=['gt_img'], # 要裁剪的图像的关键词 crop_size=(384, 384), # 裁剪图像块的大小 random_crop=True, # 是否使用随机裁剪 ), dict( type='Resize', # 图像大小调整 keys=['gt_img'], # 要调整大小的图像的关键词 scale=input_shape, # 调整图像大小的比例 keep_ratio=False, # 调整大小时是否保持比例 ), dict( type='Normalize', # 图像归一化 keys=['gt_img'], # 要归一化的图像的关键词 mean=[127.5] * 3, # 归一化中使用的均值 std=[127.5] * 3, # 归一化中使用的标准差 to_rgb=False), # 是否将图像通道从 BGR 转换为 RGB dict(type='GetMaskedImage'), # 获取被掩盖的图像 dict( type='Collect', # 决定数据中哪些键应该传递给合成器 keys=['gt_img', 'masked_img', 'mask', 'mask_bbox'], # 要收集的数据的关键词 meta_keys=['gt_img_path']), # 要收集的数据的元关键词 dict(type='ToTensor', keys=['gt_img', 'masked_img', 'mask']), # 将图像转化为 Tensor dict(type='ToTensor', keys=['mask_bbox']) # 转化为 Tensor ] test_pipeline = train_pipeline # 构建测试/验证流程 data_root = 'data/places365' # 数据根目录 data = dict( samples_per_gpu=12, # 单个 GPU 的批量大小 workers_per_gpu=8, # 为每个 GPU 预取数据的 Worker 数 val_samples_per_gpu=1, # 验证中单个 GPU 的批量大小 val_workers_per_gpu=8, # 在验证中为每个 GPU 预取数据的 Worker 数 drop_last=True, # 是否丢弃训练中的最后一批数据 train=dict( # 训练数据集配置 type=dataset_type, ann_file=f'{data_root}/train_places_img_list_total.txt', data_prefix=data_root, pipeline=train_pipeline, test_mode=False), val=dict( # 验证数据集配置 type=dataset_type, ann_file=f'{data_root}/val_places_img_list.txt', data_prefix=data_root, pipeline=test_pipeline, test_mode=True)) optimizers = dict( # 用于构建优化器的配置,支持 PyTorch 中所有优化器,且参数与 PyTorch 中对应优化器相同 generator=dict(type='Adam', lr=0.0004), disc=dict(type='Adam', lr=0.0004)) lr_config = dict(policy='Fixed', by_epoch=False) # 用于注册 LrUpdater 钩子的学习率调度程序配置 checkpoint_config = dict(by_epoch=False, interval=50000) # 配置检查点钩子,实现参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py log_config = dict( # 配置注册记录器钩子 interval=100, # 打印日志的时间间隔 hooks=[ dict(type='TextLoggerHook', by_epoch=False), # dict(type='TensorboardLoggerHook'), # 支持 Tensorboard 记录器 # dict(type='PaviLoggerHook', init_kwargs=dict(project='mmagic')) ]) # 用于记录训练过程的记录器 visual_config = dict( # 构建可视化钩子的配置 type='VisualizationHook', output_dir='visual', interval=1000, res_name_list=[ 'gt_img', 'masked_img', 'fake_res', 'fake_img', 'fake_gt_local' ], ) # 用于可视化训练过程的记录器。 evaluation = dict(interval=50000) # 构建验证钩子的配置 total_iters = 500002 dist_params = dict(backend='nccl') # 设置分布式训练的参数,端口也可以设置 log_level = 'INFO' # 日志级别 work_dir = None # 保存当前实验的模型检查点和日志的目录 load_from = None # 从给定路径加载模型作为预训练模型。 这不会恢复训练 resume_from = None # 从给定路径恢复检查点,当检查点被保存时,训练将从该 epoch 恢复 workflow = [('train', 10000)] # runner 的工作流程。 [('train', 1)] 表示只有一个工作流程,名为 'train' 的工作流程执行一次。 训练当前生成模型时保持不变 exp_name = 'gl_places' # 实验名称 find_unused_parameters = False # 是否在分布式训练中查找未使用的参数
-
-
配置文件 - 抠图。原始 DIM 模型的配置做一个简短的评论,如下所示。
-
# 模型配置 model = dict( type='DIM', # 模型的名称(我们称之为抠图器) backbone=dict( # 主干网络的配置 type='SimpleEncoderDecoder', # 主干网络的类型 encoder=dict( # 编码器的配置 type='VGG16'), # 编码器的类型 decoder=dict( # 解码器的配置 type='PlainDecoder')), # 解码器的类型 pretrained='./weights/vgg_state_dict.pth', # 编码器的预训练权重 loss_alpha=dict( # alpha 损失的配置 type='CharbonnierLoss', # 预测的 alpha 遮罩的损失类型 loss_weight=0.5), # alpha 损失的权重 loss_comp=dict( # 组合损失的配置 type='CharbonnierCompLoss', # 组合损失的类型 loss_weight=0.5)) # 组合损失的权重 train_cfg = dict( # 训练 DIM 模型的配置 train_backbone=True, # 在 DIM stage 1 中,会对主干网络进行训练 train_refiner=False) # 在 DIM stage 1 中,不会对精炼器进行训练 test_cfg = dict( # 测试 DIM 模型的配置 refine=False, # 是否使用精炼器输出作为输出,在 stage 1 中,我们不使用它 metrics=['SAD', 'MSE', 'GRAD', 'CONN']) # 测试时使用的指标 # 数据配置 dataset_type = 'AdobeComp1kDataset' # 数据集类型,这将用于定义数据集 data_root = 'data/adobe_composition-1k' # 数据的根目录 img_norm_cfg = dict( # 归一化输入图像的配置 mean=[0.485, 0.456, 0.406], # 归一化中使用的均值 std=[0.229, 0.224, 0.225], # 归一化中使用的标准差 to_rgb=True) # 是否将图像通道从 BGR 转换为 RGB train_pipeline = [ # 训练数据处理流程 dict( type='LoadImageFromFile', # 从文件加载 alpha 遮罩 key='alpha', # 注释文件中 alpha 遮罩的键关键词。流程将从路径 “alpha_path” 中读取 alpha 遮罩 flag='grayscale'), # 加载灰度图像,形状为(高度、宽度) dict( type='LoadImageFromFile', # 从文件中加载图像 key='fg'), # 要加载的图像的关键词。流程将从路径 “fg_path” 读取 fg dict( type='LoadImageFromFile', # 从文件中加载图像 key='bg'), # 要加载的图像的关键词。流程将从路径 “bg_path” 读取 bg dict( type='LoadImageFromFile', # 从文件中加载图像 key='merged'), # 要加载的图像的关键词。流程将从路径 “merged_path” 读取并合并 dict( type='CropAroundUnknown', # 在未知区域(半透明区域)周围裁剪图像 keys=['alpha', 'merged', 'ori_merged', 'fg', 'bg'], # 要裁剪的图像 crop_sizes=[320, 480, 640]), # 裁剪大小 dict( type='Flip', # 翻转图像 keys=['alpha', 'merged', 'ori_merged', 'fg', 'bg']), # 要翻转的图像 dict( type='Resize', # 图像大小调整 keys=['alpha', 'merged', 'ori_merged', 'fg', 'bg'], # 图像调整大小的图像 scale=(320, 320), # 目标大小 keep_ratio=False), # 是否保持高宽比例 dict( type='GenerateTrimap', # 从 alpha 遮罩生成三元图。 kernel_size=(1, 30)), # 腐蚀/扩张内核大小的范围 dict( type='RescaleToZeroOne', # 将图像从 [0, 255] 缩放到 [0, 1] keys=['merged', 'alpha', 'ori_merged', 'fg', 'bg']), # 要重新缩放的图像 dict( type='Normalize', # 图像归一化 keys=['merged'], # 要归一化的图像 **img_norm_cfg), # 图像归一化配置(`img_norm_cfg` 的定义见上文) dict( type='Collect', # 决定数据中哪些键应该传递给合成器 keys=['merged', 'alpha', 'trimap', 'ori_merged', 'fg', 'bg'], # 图像的关键词 meta_keys=[]), # 图片的元关键词,这里不需要元信息。 dict( type='ToTensor', # 将图像转化为 Tensor keys=['merged', 'alpha', 'trimap', 'ori_merged', 'fg', 'bg']), # 要转换为 Tensor 的图像 ] test_pipeline = [ dict( type='LoadImageFromFile', # 从文件加载 alpha 遮罩 key='alpha', # 注释文件中 alpha 遮罩的键关键词。流程将从路径 “alpha_path” 中读取 alpha 遮罩 flag='grayscale', save_original_img=True), dict( type='LoadImageFromFile', # 从文件中加载图像 key='trimap', # 要加载的图像的关键词。流程将从路径 “trimap_path” 读取三元图 flag='grayscale', # 加载灰度图像,形状为(高度、宽度) save_original_img=True), # 保存三元图用于计算指标。 它将与 “ori_trimap” 一起保存 dict( type='LoadImageFromFile', # 从文件中加载图像 key='merged'), # 要加载的图像的关键词。流程将从路径 “merged_path” 读取并合并 dict( type='Pad', # 填充图像以与模型的下采样因子对齐 keys=['trimap', 'merged'], # 要填充的图像 mode='reflect'), # 填充模式 dict( type='RescaleToZeroOne', # 与 train_pipeline 相同 keys=['merged', 'ori_alpha']), # 要缩放的图像 dict( type='Normalize', # 与 train_pipeline 相同 keys=['merged'], **img_norm_cfg), dict( type='Collect', # 与 train_pipeline 相同 keys=['merged', 'trimap'], meta_keys=[ 'merged_path', 'pad', 'merged_ori_shape', 'ori_alpha', 'ori_trimap' ]), dict( type='ToTensor', # 与 train_pipeline 相同 keys=['merged', 'trimap']), ] data = dict( samples_per_gpu=1, #单个 GPU 的批量大小 workers_per_gpu=4, # 为每个 GPU 预取数据的 Worker 数 drop_last=True, # 是否丢弃训练中的最后一批数据 train=dict( # 训练数据集配置 type=dataset_type, # 数据集的类型 ann_file=f'{data_root}/training_list.json', # 注解文件路径 data_prefix=data_root, # 图像路径的前缀 pipeline=train_pipeline), # 见上文 train_pipeline val=dict( # 验证数据集配置 type=dataset_type, ann_file=f'{data_root}/test_list.json', data_prefix=data_root, pipeline=test_pipeline), # 见上文 test_pipeline test=dict( # 测试数据集配置 type=dataset_type, ann_file=f'{data_root}/test_list.json', data_prefix=data_root, pipeline=test_pipeline)) # 见上文 test_pipeline # 优化器 optimizers = dict(type='Adam', lr=0.00001) # 用于构建优化器的配置,支持 PyTorch 中所有优化器,且参数与 PyTorch 中对应优化器相同 # 学习策略 lr_config = dict( # 用于注册 LrUpdater 钩子的学习率调度程序配置 policy='Fixed') # 调度器的策略,支持 CosineAnnealing、Cyclic 等。支持的 LrUpdater 详情请参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py#L9。 # 检查点保存 checkpoint_config = dict( # 配置检查点钩子,实现参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py interval=40000, # 保存间隔为 40000 次迭代 by_epoch=False) # 按迭代计数 evaluation = dict( # # 构建验证钩子的配置 interval=40000) # 验证区间 log_config = dict( # 配置注册记录器钩子 interval=10, # 打印日志的时间间隔 hooks=[ dict(type='TextLoggerHook', by_epoch=False), # 用于记录训练过程的记录器 # dict(type='TensorboardLoggerHook') # 支持 Tensorboard 记录器 ]) # runtime settings total_iters = 1000000 # 训练模型的总迭代次数 dist_params = dict(backend='nccl') # 设置分布式训练的参数,端口也可以设置 log_level = 'INFO' # 日志级别 work_dir = './work_dirs/dim_stage1' # 保存当前实验的模型检查点和日志的目录 load_from = None # 从给定路径加载模型作为预训练模型。 这不会恢复训练 resume_from = None # 从给定路径恢复检查点,当检查点被保存时,训练将从该 epoch 恢复 workflow = [('train', 1)] # runner 的工作流程。 [('train', 1)] 表示只有一个工作流程,名为 'train' 的工作流程执行一次。 训练当前抠图模型时保持不变
-
-
使用以下命令,输入一张测试图像以及缺损部位的遮罩图像,实现对测试图像的补全。
-
python demo/inpainting_demo.py \ ${CONFIG_FILE} \ ${CHECKPOINT_FILE} \ ${MASKED_IMAGE_FILE} \ ${MASK_FILE} \ ${SAVE_FILE} \ [--imshow] \ [--device ${GPU_ID}]
-
-
输入一张测试图像以及对应的三元图(trimap),实现对测试图像的抠图。
-
python demo/matting_demo.py \ ${CONFIG_FILE} \ ${CHECKPOINT_FILE} \ ${IMAGE_FILE} \ ${TRIMAP_FILE} \ ${SAVE_FILE} \ [--imshow] \ [--device ${GPU_ID}] ## 举例 python demo/matting_demo.py \ configs/dim/dim_stage3-v16-pln_1000k-1xb1_comp1k.py \ https://download.openmmlab.com/mmediting/mattors/dim/dim_stage3_v16_pln_1x1_1000k_comp1k_SAD-50.6_20200609_111851-647f24b6.pth \ tests/data/matting_dataset/merged/GT05.jpg \ tests/data/matting_dataset/trimap/GT05.png \ tests/data/matting_dataset/pred/GT05.png
-
-
使用以下命令来测试要恢复的图像。
-
python demo/restoration_demo.py \ ${CONFIG_FILE} \ ${CHECKPOINT_FILE} \ ${IMAGE_FILE} \ ${SAVE_FILE} \ [--imshow] \ [--device ${GPU_ID}] \ [--ref-path ${REF_PATH}] ## 举例 python demo/restoration_demo.py \ configs/esrgan/esrgan_x4c64b23g32_400k-1xb16_div2k.py \ https://download.openmmlab.com/mmediting/restorers/esrgan/esrgan_x4c64b23g32_1x16_400k_div2k_20200508-f8ccaf3b.pth \ tests/data/image/lq/baboon_x4.png \ demo/demo_out_baboon.png
-
-
视频超分辨率
-
python demo/restoration_video_demo.py \ ${CONFIG_FILE} \ ${CHECKPOINT_FILE} \ ${INPUT_DIR} \ ${OUTPUT_DIR} \ [--window-size=${WINDOW_SIZE}] \ [--device ${GPU_ID}] ## 举例 python demo/restoration_video_demo.py \ configs/edvr/edvrm_wotsa_reds_600k-8xb8.py \ https://download.openmmlab.com/mmediting/restorers/edvr/edvrm_wotsa_x4_8x4_600k_reds_20200522-0570e567.pth \ data/Vid4/BIx4/calendar/ \ demo/output \ --window-size=5
-
-
可以使用以下命令来测试视频插帧。
-
python demo/video_interpolation_demo.py \ ${CONFIG_FILE} \ ${CHECKPOINT_FILE} \ ${INPUT_DIR} \ ${OUTPUT_DIR} \ [--fps-multiplier ${FPS_MULTIPLIER}] \ [--fps ${FPS}] -
${INPUT_DIR}和${OUTPUT_DIR}可以是视频文件路径或存放一系列有序图像的文件夹。 若${OUTPUT_DIR}是视频文件地址,其帧率可由输入视频帧率和fps_multiplier共同决定,也可由fps直接给定(其中前者优先级更高)。
-
-
图像生成文章来源:https://www.toymoban.com/news/detail-486438.html
-
python demo/generation_demo.py \ ${CONFIG_FILE} \ ${CHECKPOINT_FILE} \ ${IMAGE_FILE} \ ${SAVE_FILE} \ [--unpaired-path ${UNPAIRED_IMAGE_FILE}] \ [--imshow] \ [--device ${GPU_ID}] -
如果指定了
--unpaired-path(用于 CycleGAN),模型将执行未配对的图像到图像的转换。 如果指定了--imshow,演示也将使用opencv显示图像。文章来源地址https://www.toymoban.com/news/detail-486438.html
-
到了这里,关于【MMagic】底层视觉与MMEditing Plus版;小窥AIGC,生成模型涌现智慧,研究创造性的方向的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!