目录
Python应用程序设计
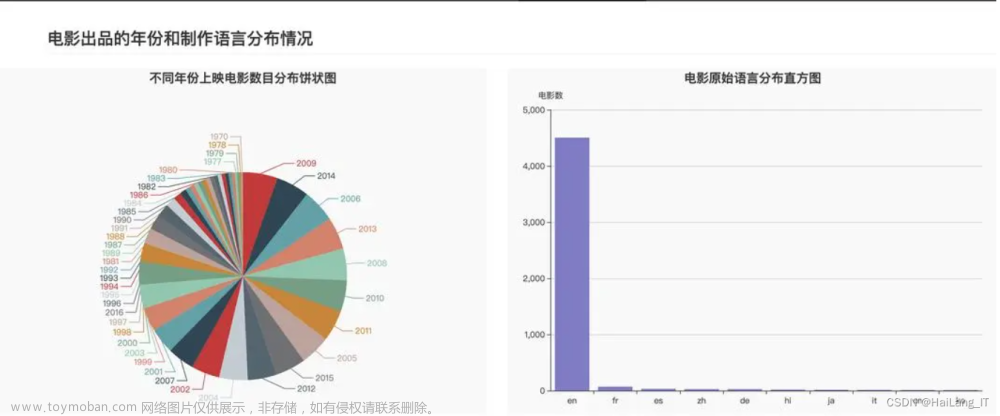
豆瓣读书网站的数据爬取与分析
一、 项目背景与需求分析
二、数据抓取与分析
三、数据库设计
四、展示系统
一、 项目背景与需求分析
选题背景
本设计作品选取了豆瓣读书网站,主要爬取的是豆瓣读书的TOP250,通过爬取的数据进行对信息的进一步的数据分析。豆瓣读书TOP250网址为:https://book.douban.com/top250?start=0。
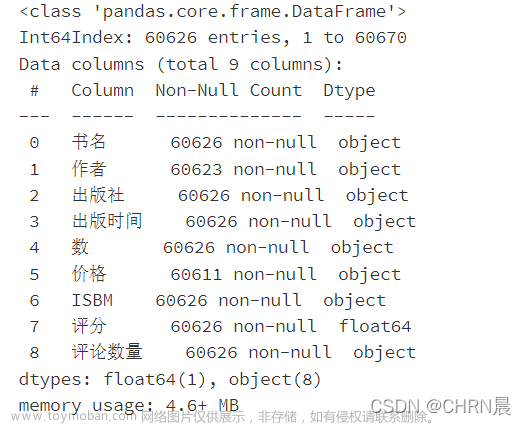
在这个设计中爬取了豆瓣读书的书名、书籍链接、书籍评分、评分人数、书籍作者、书籍的翻译者、出版社、出版日期、书籍的价格、一句话评价、书籍图片。通过爬取这些数据,可以使我们更加直观看到TOP250的图书整理数据,有效减少手动筛选统计的工作量。
数据抓取与分析
1.豆瓣图书数据
通过requests向页面发送请求,BeautifulSoup解析豆瓣读书网页数据,将爬取下来的数据利用pandas库存到csv,通过for循环依此爬取网站十页250条数据。由于爬取的内容板块较多,且并不是每一本书都有一句话评价、译者、作者,也并不是每一本书都只有一个价格,所以需要将特殊情况另外拿出分析。
当每一种情况都有时:
if len(info) == 5:
book_author.append(info[0])
book_translater.append(info[1])
book_publisher.append(info[2])
book_pub_year.append(info[3])
book_price.append(str(info[4]))
当没有译者的时候:
elif len(info) == 4:
book_author.append(info[0])
book_translater.append(None)
book_publisher.append(info[1])
book_pub_year.append(info[2])
book_price.append(str(info[3]))
当有两种价格时:
elif len(info) == 6:
book_author.append(info[0])
book_translater.append(info[1])
book_publisher.append(info[2])
book_pub_year.append(info[3])
book_price.append(str(info[4]) + '/' + str(info[5]))
当没有作者时:
elif len(info) == 3:
book_author.append(None)
book_translater.append(None)
book_publisher.append(info[0])
book_pub_year.append(info[1])
book_price.append(str(info[2]))
当没有一句话评价时:
if book.select('.quote span'):
book_comment.append(book.select('.quote span')[0].text)
else:
book_comment.append(None)
爬取数据:

图1
转换为excl文件:
图2
数据展示:
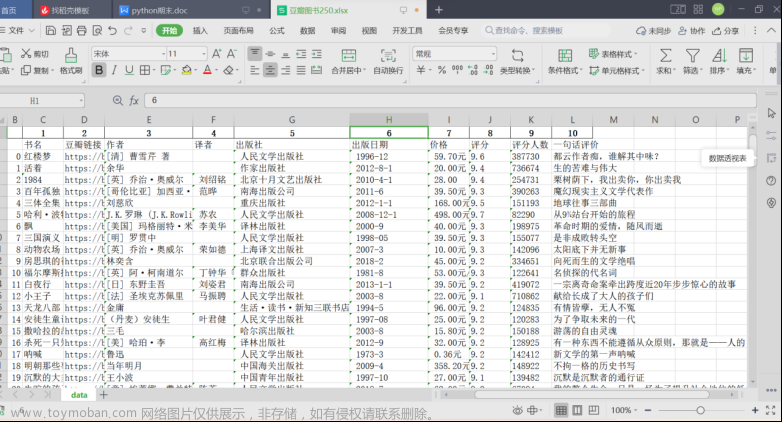
图3
图标数据和数据库数据
该部分的取数通过运用正则表达式,找到要爬取的书名和评分,再通过控制爬取的网页页数,从而爬出前25本和250本图书的数据。
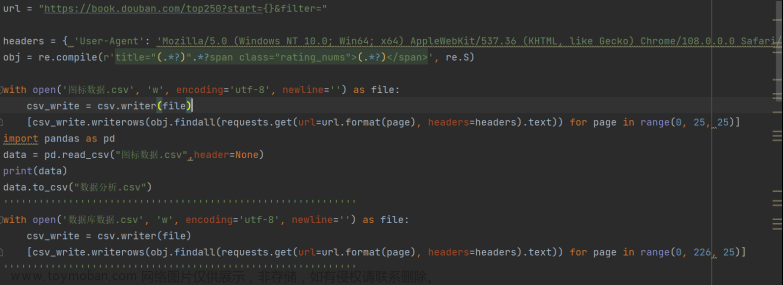
图4
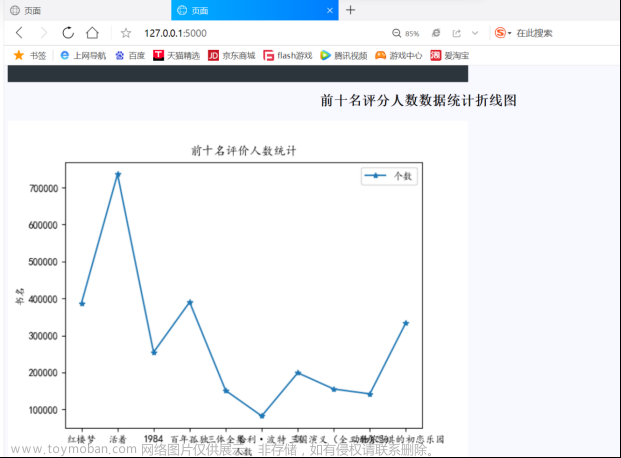
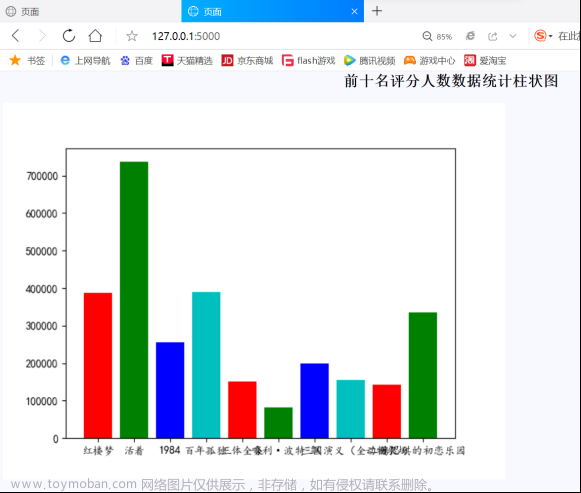
排名前十名评分人物数据
该数据的取值是从“豆瓣图书.csv”中取出的,通过取出我们本来文件中的第一列书名与第九列评分,再控制一到十行,就可方便取出数据。
import pandas as pd
data = pd.read_csv("豆瓣图书.csv",header=None)
data = data.loc[1:10,[1,9]]
print(data)
data.to_csv("排名前十评分人数数据.csv")
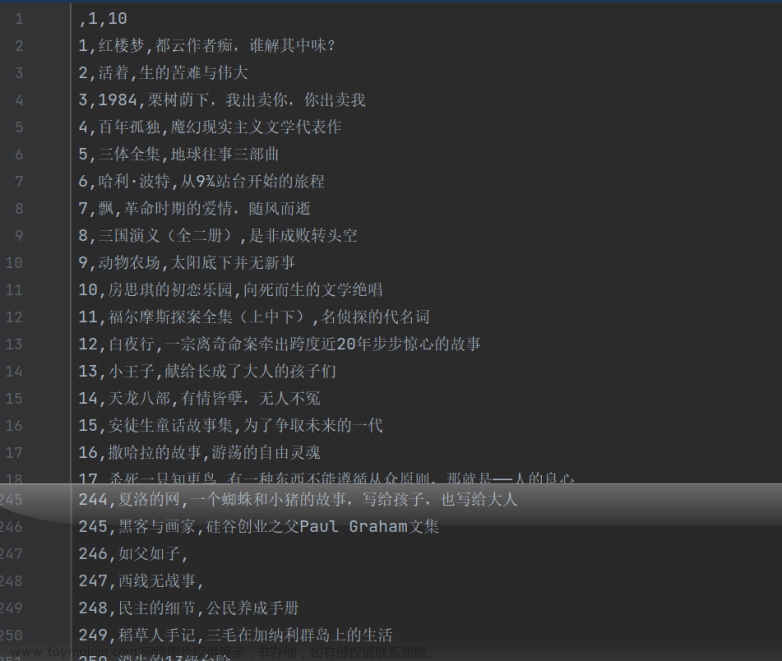
图6
爬取图片
由于之前已经将爬取的代码保存成了a.txt,那么只要在该文件里找到图片所在位置node1=soup.find_all(“img”,width=”90”),再将图片取出存入文件夹即可。
代码如图:
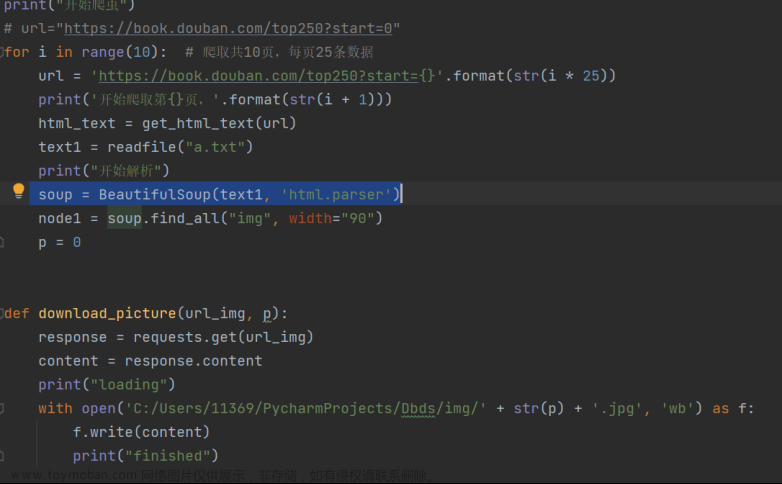
图7
爬取结果:

数据库设计
豆瓣读书爬虫系统在SQLite的平台上创建了一个名为books的数据库,在库中共创建了1张表。
信息表book,存储图书的信息,其设计如表1所示。
表1 图书表
表名 |
属性 |
类型 |
描述 |
备注 |
Book |
name |
String |
书名 |
主码 |
pingfen |
String |
评分 |
not null |

展示系统
1.登录页面
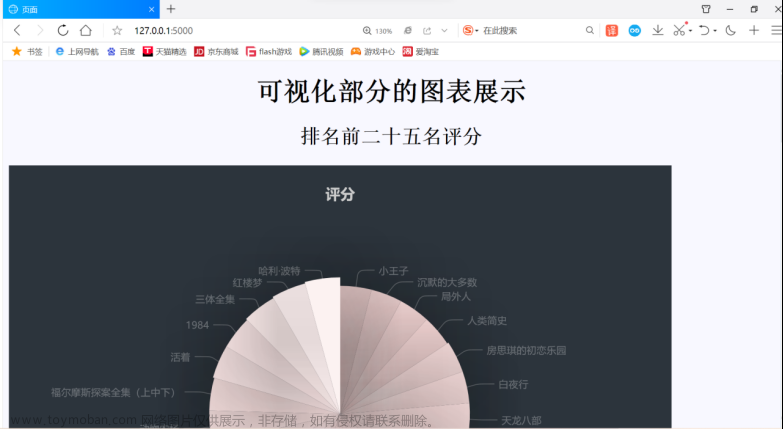
2.可视化部分图表展示


参考文章来源:https://www.toymoban.com/news/detail-486632.html
(3条消息) python爬虫获取豆瓣TOP25电影名称和评分_生年不满百,常怀千岁忧的博客-CSDN博客文章来源地址https://www.toymoban.com/news/detail-486632.html
到了这里,关于豆瓣读书网站的数据爬取与分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!