- 霹雳吧啦Wz的个人空间-霹雳吧啦Wz个人主页-哔哩哔哩视频 目标检测篇
- github地址;GitHub - WZMIAOMIAO/deep-learning-for-image-processing: deep learning for image processing including classification and object-detection etc.
-


数据集
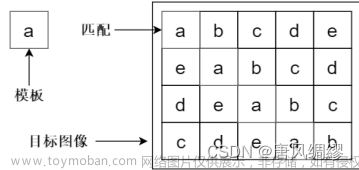
实例分割vs语义分割:语义分割只有类别;实例分割是每一个目标。

- test数据集不公开;trainval是用来训练验证的。
- -1,0,1;是否有船;0-这个船是有困难的。


MS COCO数据集介绍以及pycocotools简单使用_太阳花的小绿豆的博客-CSDN博客


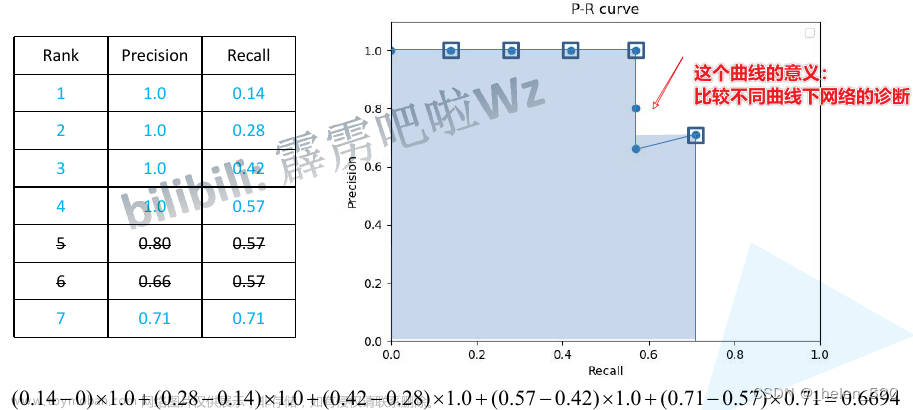
mAP计算方法
推荐文章: https://www.zhihu.com/question/53405779/answer/399478988


RCNN






Faster RCNN






直接端到端的过程;不像Fast RCNN还需要ss部分;RPN取代ss,称为端到端。
框架越来越简洁,效果也越来越好。
RPN网络结构 CVPR2016

一些小细节:
- # 是否按图片相似高宽比采样图片组成batch 统计图像的长宽比,然后从相似的长宽比中去获取batch图像,这样能够减少显存;统计长宽比的代码,结果也有一些发现:原始数据的长宽比不一样。
# 使用的话能够减小训练时所需GPU显存,默认使用 - # create model num_classes equal background + 20 classes 创建模型时需要加入背景类
model = create_model(num_classes=args.num_classes + 1) 

- 先冻结backbone的底层权重,训练后面,不仅训练速度会加快,而且模型效果也比直接训练好。训练方法也参考了官方的训练方法。
- 模型开始收敛之后,开始保存模型权重。保存了很多内容,优化器和lr都一起保存下来了。
- 加了参数parse,可以使用脚本来训练。命令行参数。
- 接着训练,保存模型,然后继续开始训练。
- 15个epoch之后,VOC_mAP到了80%;几个epoch,就可以达到这么高的mAP?why?我去?
- 冻结BN层
- 记录预测时间:模型在第一次启动的时候比较慢,在第一次推理之后,再统计时间。50ms一张图像;GPU上。不要统计第一次前向传播的时间。
- type,有时候会报错;IDE的问题,不要去改;并不是注释。 # typ 这个并不是注释,而是告诉pytorch的格式。

- 通过fasterRCNN的网络结构来看代码
黄色是在训练转给你才有的


- anchors 共20W个,只保留scores最高的2000个预测框;每一层只保留2000个;

- anchor和gt的匹配:看看哪些anchor作为正样本和负样本。 负样本;丢弃样本;正样本
- 计算loss,只有正样本计算bbox loss;所有的都计算clas loss;同时2000个推荐rpn里面只有几百个去计算loss的;
- Fast RCNN部分:ROIHeads;
- ROIPooling:ROIAlign
(base) zhr@zhr-Lenovo-Legion-Y7000P2020H:/home/helen/code/deep-learning-for-image-processing$ conda activate fastai2
(fastai2) zhr@zhr-Lenovo-Legion-Y7000P2020H:/home/helen/code/deep-learning-for-image-processing$ /home/zhr/miniconda3/envs/fastai2/bin/python /home/helen/code/deep-learning-for-image-processing/pytorch_object_detection/faster_rcnn/train_res50_fpn.py
Namespace(device='cuda:0', data_path='/home/helen/dataset/VOCtrainval_06-Nov-2007', num_classes=20, output_dir='./save_weights', resume='', start_epoch=0, epochs=15, lr=0.01, momentum=0.9, weight_decay=0.0001, batch_size=2, aspect_ratio_group_factor=3, amp=False)
Using cuda device training.
Using [0, 0.5, 0.6299605249474366, 0.7937005259840997, 1.0, 1.2599210498948732, 1.5874010519681994, 2.0, inf] as bins for aspect ratio quantization
Count of instances per bin: [ 4 8 400 57 103 1845 58 26]
Using 2 dataloader workers
_IncompatibleKeys(missing_keys=[], unexpected_keys=['fc.weight', 'fc.bias'])
/home/zhr/miniconda3/envs/fastai2/lib/python3.9/site-packages/torch/functional.py:445: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:2157.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
Epoch: [0] [ 0/1250] eta: 0:16:50.245979 lr: 0.000020 loss: 3.9301 (3.9301) loss_classifier: 3.1865 (3.1865) loss_box_reg: 0.1150 (0.1150) loss_objectness: 0.5403 (0.5403) loss_rpn_box_reg: 0.0882 (0.0882) time: 0.8082 data: 0.1655 max mem: 3213
Epoch: [0] [ 50/1250] eta: 0:10:51.982285 lr: 0.000519 loss: 0.9857 (1.8274) loss_classifier: 0.5287 (1.2986) loss_box_reg: 0.4109 (0.2776) loss_objectness: 0.0314 (0.2208) loss_rpn_box_reg: 0.0147 (0.0305) time: 0.5342 data: 0.0001 max mem: 3564
Epoch: [0] [ 100/1250] eta: 0:10:16.309807 lr: 0.001019 loss: 0.5225 (1.2822) loss_classifier: 0.3056 (0.8365) loss_box_reg: 0.1879 (0.2742) loss_objectness: 0.0218 (0.1443) loss_rpn_box_reg: 0.0073 (0.0273) time: 0.5390 data: 0.0001 max mem: 3564
Epoch: [0] [ 150/1250] eta: 0:09:44.290952 lr: 0.001518 loss: 0.4234 (1.0831) loss_classifier: 0.2392 (0.6689) loss_box_reg: 0.1529 (0.2802) loss_objectness: 0.0269 (0.1081) loss_rpn_box_reg: 0.0044 (0.0259) time: 0.5095 data: 0.0001 max mem: 3564
Epoch: [0] [ 200/1250] eta: 0:09:17.379252 lr: 0.002018 loss: 0.3337 (0.9938) loss_classifier: 0.1420 (0.5824) loss_box_reg: 0.1097 (0.2923) loss_objectness: 0.0411 (0.0925) loss_rpn_box_reg: 0.0409 (0.0267) time: 0.5314 data: 0.0001 max mem: 3564
Epoch: [0] [ 250/1250] eta: 0:08:55.809067 lr: 0.002517 loss: 0.6095 (0.9255) loss_classifier: 0.2653 (0.5296) loss_box_reg: 0.3108 (0.2890) loss_objectness: 0.0097 (0.0808) loss_rpn_box_reg: 0.0237 (0.0260) time: 0.5611 data: 0.0001 max mem: 3564
Epoch: [0] [ 300/1250] eta: 0:08:27.952396 lr: 0.003017 loss: 0.6465 (0.8819) loss_classifier: 0.2775 (0.4919) loss_box_reg: 0.2594 (0.2901) loss_objectness: 0.0776 (0.0735) loss_rpn_box_reg: 0.0319 (0.0264) time: 0.5391 data: 0.0001 max mem: 3564
Epoch: [0] [ 350/1250] eta: 0:08:01.532866 lr: 0.003516 loss: 0.5011 (0.8319) loss_classifier: 0.1880 (0.4560) loss_box_reg: 0.2810 (0.2828) loss_objectness: 0.0193 (0.0667) loss_rpn_box_reg: 0.0129 (0.0264) time: 0.5380 data: 0.0001 max mem: 3564
Epoch: [0] [ 400/1250] eta: 0:07:32.227619 lr: 0.004016 loss: 0.9177 (0.7983) loss_classifier: 0.4662 (0.4321) loss_box_reg: 0.4026 (0.2783) loss_objectness: 0.0273 (0.0621) loss_rpn_box_reg: 0.0215 (0.0259) time: 0.5185 data: 0.0001 max mem: 3564
Epoch: [0] [ 450/1250] eta: 0:07:04.867693 lr: 0.004515 loss: 0.5924 (0.7654) loss_classifier: 0.1544 (0.4091) loss_box_reg: 0.3071 (0.2733) loss_objectness: 0.0731 (0.0576) loss_rpn_box_reg: 0.0578 (0.0254) time: 0.5164 data: 0.0001 max mem: 3564
Epoch: [0] [ 500/1250] eta: 0:06:38.074630 lr: 0.005015 loss: 0.3341 (0.7497) loss_classifier: 0.1391 (0.3970) loss_box_reg: 0.0885 (0.2717) loss_objectness: 0.0195 (0.0556) loss_rpn_box_reg: 0.0871 (0.0255) time: 0.5333 data: 0.0001 max mem: 3564
Epoch: [0] [ 550/1250] eta: 0:06:10.807065 lr: 0.005514 loss: 0.1902 (0.7351) loss_classifier: 0.0802 (0.3851) loss_box_reg: 0.0925 (0.2711) loss_objectness: 0.0157 (0.0533) loss_rpn_box_reg: 0.0019 (0.0256) time: 0.5072 data: 0.0001 max mem: 3564
Epoch: [0] [ 600/1250] eta: 0:05:44.049398 lr: 0.006014 loss: 0.3604 (0.7184) loss_classifier: 0.1228 (0.3740) loss_box_reg: 0.1714 (0.2674) loss_objectness: 0.0401 (0.0516) loss_rpn_box_reg: 0.0261 (0.0254) time: 0.5430 data: 0.0001 max mem: 3564
Epoch: [0] [ 650/1250] eta: 0:05:17.771165 lr: 0.006513 loss: 0.4614 (0.6996) loss_classifier: 0.2250 (0.3619) loss_box_reg: 0.1799 (0.2622) loss_objectness: 0.0104 (0.0501) loss_rpn_box_reg: 0.0460 (0.0254) time: 0.5383 data: 0.0001 max mem: 3564
Epoch: [0] [ 700/1250] eta: 0:04:51.137477 lr: 0.007013 loss: 0.8279 (0.6829) loss_classifier: 0.3304 (0.3515) loss_box_reg: 0.4181 (0.2582) loss_objectness: 0.0566 (0.0482) loss_rpn_box_reg: 0.0228 (0.0249) time: 0.5235 data: 0.0001 max mem: 3564
Epoch: [0] [ 750/1250] eta: 0:04:24.435647 lr: 0.007512 loss: 0.8482 (0.6704) loss_classifier: 0.3065 (0.3429) loss_box_reg: 0.5166 (0.2559) loss_objectness: 0.0114 (0.0467) loss_rpn_box_reg: 0.0138 (0.0249) time: 0.5250 data: 0.0001 max mem: 3564
Epoch: [0] [ 800/1250] eta: 0:03:58.256285 lr: 0.008012 loss: 0.3776 (0.6573) loss_classifier: 0.1871 (0.3344) loss_box_reg: 0.1464 (0.2527) loss_objectness: 0.0362 (0.0453) loss_rpn_box_reg: 0.0078 (0.0248) time: 0.5322 data: 0.0001 max mem: 3564
Epoch: [0] [ 850/1250] eta: 0:03:31.801975 lr: 0.008511 loss: 0.5743 (0.6512) loss_classifier: 0.1657 (0.3305) loss_box_reg: 0.3795 (0.2515) loss_objectness: 0.0139 (0.0444) loss_rpn_box_reg: 0.0152 (0.0248) time: 0.5123 data: 0.0001 max mem: 3564
Epoch: [0] [ 900/1250] eta: 0:03:05.681250 lr: 0.009011 loss: 0.3209 (0.6391) loss_classifier: 0.1504 (0.3230) loss_box_reg: 0.1290 (0.2475) loss_objectness: 0.0192 (0.0437) loss_rpn_box_reg: 0.0224 (0.0249) time: 0.5535 data: 0.0001 max mem: 3564
Epoch: [0] [ 950/1250] eta: 0:02:39.160406 lr: 0.009510 loss: 0.3390 (0.6315) loss_classifier: 0.1408 (0.3179) loss_box_reg: 0.0968 (0.2446) loss_objectness: 0.0551 (0.0437) loss_rpn_box_reg: 0.0463 (0.0252) time: 0.5313 data: 0.0001 max mem: 3564
Epoch: [0] [1000/1250] eta: 0:02:12.473630 lr: 0.010000 loss: 0.6111 (0.6244) loss_classifier: 0.2668 (0.3134) loss_box_reg: 0.2741 (0.2423) loss_objectness: 0.0424 (0.0434) loss_rpn_box_reg: 0.0279 (0.0253) time: 0.5298 data: 0.0001 max mem: 3564
Epoch: [0] [1050/1250] eta: 0:01:45.931352 lr: 0.010000 loss: 0.1799 (0.6206) loss_classifier: 0.0963 (0.3109) loss_box_reg: 0.0665 (0.2412) loss_objectness: 0.0159 (0.0431) loss_rpn_box_reg: 0.0012 (0.0254) time: 0.5216 data: 0.0001 max mem: 3564
Epoch: [0] [1100/1250] eta: 0:01:19.383105 lr: 0.010000 loss: 0.3410 (0.6164) loss_classifier: 0.1912 (0.3075) loss_box_reg: 0.1053 (0.2405) loss_objectness: 0.0146 (0.0428) loss_rpn_box_reg: 0.0299 (0.0257) time: 0.5140 data: 0.0001 max mem: 3564
Epoch: [0] [1150/1250] eta: 0:00:52.859734 lr: 0.010000 loss: 0.3323 (0.6092) loss_classifier: 0.1147 (0.3034) loss_box_reg: 0.1117 (0.2384) loss_objectness: 0.0517 (0.0419) loss_rpn_box_reg: 0.0541 (0.0255) time: 0.5126 data: 0.0001 max mem: 3564
Epoch: [0] [1200/1250] eta: 0:00:26.451852 lr: 0.010000 loss: 0.8478 (0.6050) loss_classifier: 0.3946 (0.3007) loss_box_reg: 0.3991 (0.2376) loss_objectness: 0.0318 (0.0414) loss_rpn_box_reg: 0.0224 (0.0254) time: 0.5384 data: 0.0001 max mem: 3564
Epoch: [0] [1249/1250] eta: 0:00:00.529085 lr: 0.010000 loss: 0.5046 (0.6003) loss_classifier: 0.2864 (0.2969) loss_box_reg: 0.1911 (0.2361) loss_objectness: 0.0120 (0.0417) loss_rpn_box_reg: 0.0152 (0.0256) time: 0.5260 data: 0.0001 max mem: 3564
Epoch: [0] Total time: 0:11:01 (0.5292 s / it)
creating index...
index created!
Test: [ 0/2510] eta: 0:09:30.997376 model_time: 0.1030 (0.1030) evaluator_time: 0.0103 (0.0103) time: 0.2275 data: 0.1136 max mem: 3564
Test: [ 100/2510] eta: 0:04:19.837475 model_time: 0.1070 (0.1019) evaluator_time: 0.0035 (0.0044) time: 0.1081 data: 0.0001 max mem: 3564
Test: [ 200/2510] eta: 0:04:08.381130 model_time: 0.0998 (0.1020) evaluator_time: 0.0105 (0.0045) time: 0.1107 data: 0.0001 max mem: 3564
Test: [ 300/2510] eta: 0:03:56.536819 model_time: 0.0983 (0.1018) evaluator_time: 0.0041 (0.0044) time: 0.1066 data: 0.0001 max mem: 3564
Test: [ 400/2510] eta: 0:03:46.088226 model_time: 0.0989 (0.1019) evaluator_time: 0.0042 (0.0046) time: 0.1066 data: 0.0001 max mem: 3564
Test: [ 500/2510] eta: 0:03:35.095542 model_time: 0.1007 (0.1018) evaluator_time: 0.0039 (0.0046) time: 0.1068 data: 0.0001 max mem: 3564
Test: [ 600/2510] eta: 0:03:24.057438 model_time: 0.0991 (0.1017) evaluator_time: 0.0059 (0.0045) time: 0.1056 data: 0.0001 max mem: 3564
Test: [ 700/2510] eta: 0:03:13.869030 model_time: 0.1081 (0.1021) evaluator_time: 0.0024 (0.0045) time: 0.1076 data: 0.0001 max mem: 3564
Test: [ 800/2510] eta: 0:03:03.341802 model_time: 0.0984 (0.1022) evaluator_time: 0.0061 (0.0045) time: 0.1050 data: 0.0001 max mem: 3564
Test: [ 900/2510] eta: 0:02:52.732500 model_time: 0.0994 (0.1022) evaluator_time: 0.0057 (0.0045) time: 0.1091 data: 0.0001 max mem: 3564
Test: [1000/2510] eta: 0:02:41.909927 model_time: 0.0996 (0.1021) evaluator_time: 0.0051 (0.0046) time: 0.1084 data: 0.0001 max mem: 3564
Test: [1100/2510] eta: 0:02:31.036624 model_time: 0.0991 (0.1020) evaluator_time: 0.0040 (0.0046) time: 0.1080 data: 0.0001 max mem: 3564
Test: [1200/2510] eta: 0:02:20.235565 model_time: 0.0989 (0.1020) evaluator_time: 0.0017 (0.0046) time: 0.1063 data: 0.0001 max mem: 3564
Test: [1300/2510] eta: 0:02:09.559061 model_time: 0.0985 (0.1020) evaluator_time: 0.0032 (0.0046) time: 0.1059 data: 0.0001 max mem: 3564
Test: [1400/2510] eta: 0:01:58.835945 model_time: 0.1080 (0.1020) evaluator_time: 0.0085 (0.0045) time: 0.1059 data: 0.0001 max mem: 3564
Test: [1500/2510] eta: 0:01:48.172328 model_time: 0.0986 (0.1020) evaluator_time: 0.0053 (0.0046) time: 0.1067 data: 0.0001 max mem: 3564
Test: [1600/2510] eta: 0:01:37.436264 model_time: 0.1076 (0.1020) evaluator_time: 0.0040 (0.0046) time: 0.1088 data: 0.0001 max mem: 3564
Test: [1700/2510] eta: 0:01:26.723859 model_time: 0.0989 (0.1020) evaluator_time: 0.0039 (0.0046) time: 0.1053 data: 0.0001 max mem: 3564
Test: [1800/2510] eta: 0:01:16.011011 model_time: 0.0987 (0.1020) evaluator_time: 0.0036 (0.0046) time: 0.1078 data: 0.0001 max mem: 3564
Test: [1900/2510] eta: 0:01:05.321071 model_time: 0.0878 (0.1021) evaluator_time: 0.0170 (0.0045) time: 0.1078 data: 0.0001 max mem: 3564
Test: [2000/2510] eta: 0:00:54.577022 model_time: 0.1124 (0.1020) evaluator_time: 0.0149 (0.0045) time: 0.1038 data: 0.0001 max mem: 3564
Test: [2100/2510] eta: 0:00:43.881791 model_time: 0.0977 (0.1020) evaluator_time: 0.0047 (0.0045) time: 0.1071 data: 0.0001 max mem: 3564
Test: [2200/2510] eta: 0:00:33.196065 model_time: 0.0995 (0.1021) evaluator_time: 0.0050 (0.0046) time: 0.1082 data: 0.0001 max mem: 3564
Test: [2300/2510] eta: 0:00:22.478021 model_time: 0.0994 (0.1020) evaluator_time: 0.0061 (0.0046) time: 0.1059 data: 0.0001 max mem: 3564
Test: [2400/2510] eta: 0:00:11.767563 model_time: 0.0984 (0.1020) evaluator_time: 0.0062 (0.0046) time: 0.1059 data: 0.0001 max mem: 3564
Test: [2500/2510] eta: 0:00:01.069602 model_time: 0.1081 (0.1019) evaluator_time: 0.0037 (0.0046) time: 0.1075 data: 0.0001 max mem: 3564
Test: [2509/2510] eta: 0:00:00.106963 model_time: 0.1083 (0.1019) evaluator_time: 0.0094 (0.0046) time: 0.1069 data: 0.0001 max mem: 3564
Test: Total time: 0:04:28 (0.1070 s / it)
Averaged stats: model_time: 0.1083 (0.1019) evaluator_time: 0.0094 (0.0046)
Accumulating evaluation results...
DONE (t=2.25s).
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.237
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.539
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.158
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.089
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.192
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.255
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.274
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.425
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.436
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.193
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.370
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.457



现在是往里面填值进去:10是IoU的10个阈值,100是recall的10个值,20是类别,4是面积,3是max个数;precision和recall都是这么大的一个矩阵
在coco_eval的evaluateImg中,有详细计算的逻辑:match和ignore的地方,然后根据这个去做统计。
- for 类别
- for area
- for max
- 取检测的多少个框框出来:dtScores
- 按照置信度来降序排列
- 计算tps和fps:dtMatches的内容
- for max
- for area
- 先收集所有的框框,然后把所有框框排列起来
- 然后计算tps,fps
COCO tools工具 源码阅读
Pycocotools源码分析 - 知乎




- prepare准备的是:coco_eval的_gts和_dts;


100个框框中,类别为9个只有38个框。

值得注意的是,这里的ious计算为什么只有(0,9)是有数值的呢? 这里面是一个矩阵:(38,5);说明只计算了gt所在的类别的;




目标检测:cocoeval中的evaluateImg,accumulate函数解析_evaluateimglists_cartes1us的博客-CSDN博客


accumulate的代码如下:
代码地址为:pycocotools/cocoeval.py #315行
- 每个类别,每一个区域,每一个图像,去收集相应的内容
- 从每一个图像里面,去把所有evalImgs都给取出来,到E中
- 然后根据dtScores,同一个类别,同一个区域里面;这些所有的框框先根据置信度降序排列,取得索引。
- 同时框框的个数根据maxDet来决定
- 排序后的dtm, dtIg, gtIg
- 开始计算tps, fps和fns
- tps = dtm && ~dtIg 所有dtm有匹配gt的,同时不可忽略的det框,都是tps。
- fps = ~dtm && ~dtIg 所有dtm中为0的部分,dtm为0就是初始化过的。
dtIg = dtIg || (~dtm && a), 若面积是all,a=False, 就只看dtIg; dtIg起初全是0,就看gtIg[m]赋予的值了;如果匹配的gt框,其不是ignore的,那就是不可忽略的。

dtIg=1,当dtm没有匹配,或者det框面积不在范围内的,都会设置为1;dtIg=0的 且 dtm=0的det框,都是fps;
对于all面积来说,dtIg就看gtIg了;匹配的框,是否要忽略;看召回率的影响!!!
recall = tp / npig,所有的gt匹配的框框;
对比一下coco map和VOC map
最大的差别应该在:coco_mAP比VOC mAP要高一些;因为只有gt和det都有,才计算有匹配,才有EvalImg;没有的就不计算fps,tps,fns。所以指标要好一些的。
VOC mAP

COCO mAP

coco_evaluator---
|--coco_gt----COCO() # 对象:将
| |---self.dataset # 里面存了所有的gt框的标注信息
| |---self.anns, self.imgs, self.cats, self.imgToAnns, self.catToImgs
|--coco_eval----COCOeval()
| |---cocoGt---COCO() # 前面的coco_gt
| |---cocoDt---COCO() # 根据coco_gt和detections来构造Dt,COCO()类型对象
| |---evalImgs
| |---_gts
| |---_dts
| |---params---imgIds---maxDets---catIds
| |---ious[(img_id, cat_id)] # det框按照score置信度降序排列的
| |---cocoDt = loadRes(self.coco_gt, predictions) # 利用gt来构建Dt对象,确认了是同一个对象
| |---_prepare() # 函数功能: 重新组织数据格式,通过img_id和类别去索引dt和gt
| | |---gts = self.cocoGt.loadAnns(self.cocoGt.getAnnIds(img_id, cat_id=[1~20]))
| | |---_gts[img_id, cat_id].append(gt)
| | |---_dts[img_id, cat_id].append(dt)
| |---computeIoU()
| | |---# 只有gt和dt都有的类别是有计算ious的,其他都是空的
| | |---det按照score降序排列,ious里面是有顺序的,det的置信度高的优先匹配
| |---evaluateImgs() # (20,4,1)20个类别,4个面积段;这里面进行匹配算法
| | |---(imge_id, catId, aRng, maxDet, dtIds, gtIds, dtMatches, gtMatches, dtScores, dtIgnore, gtIgnore) # dtMatches,10×m的向量
| | |---dtMatches.shape = [10, m] # 10表示IoU[0.5:1.0:0.5] 匹配的gt框ID;若没有,表示这个det框是FP误检
| | |---gtMatches.shape = [10, n] # 10表示IoU[0.5:1.0:0.5] 匹配的det框ID;若没有,表示这个gt框是FN漏检
| |---accumulate() # 开始累计计算tps, fps, fns
| | |---for c in cat_Ids:
| | |--- for a in areas:
| | |--- for m in maxDets:
| | |--- tps = dtMatches && ~dtIgnore
| | |--- fps = ~dtMatches && ~dtIgnore
| |---eval-----precision,recall, scores # TRKAM, T阈值,R召回分辨率,K类别,A面积,M最大个数
| |---summarize()
| | |---if ap=1(算ap,还是算recall) : s=self.eval['precision'], mean_s = np.mean(s[s>-1]) # 求precision的平均值
1. pycocotools如何从源码安装?如何debug进入到源码
进入到源码debug,需要从源码开始编译和安装;
因为pip install是从他人已经预编译过的开始使用,没有编译信息,无法定位和debug文章来源:https://www.toymoban.com/news/detail-486859.html
- pycocotools源码自己编译时会遇到较多的问题,需要解决很多bug,修改源码
- 修改之后的源码文件为:链接要后续补充
-
源码安装和调试方法:
- pip install -v -e .
-
# "-v" 指详细说明,或更多的输出 # "-e" 表示在可编辑模式下安装项目,因此对代码所做的任何本地修改都会生效,从而无需重新安装
-
遇到的问题:
- 没有pycocotools._mask——需要执行make操作
- pip show pycocotools一直要看其安装路径,是否为本地;如果是pip源,就要先卸载干净。
 文章来源地址https://www.toymoban.com/news/detail-486859.html
文章来源地址https://www.toymoban.com/news/detail-486859.html
到了这里,关于霹雳吧啦 目标检测 学习笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!