1、whisper简介
-
Whisper是一个通用的语音识别模型。它是在不同音频的大型数据集上训练的,也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。
-
whisper有五种模型尺寸,提供速度和准确性的平衡,其中English-only模型提供了四种选择。下面是可用模型的名称、大致内存需求和相对速度。

- github链接:https://github.com/openai/whisper
2、方法
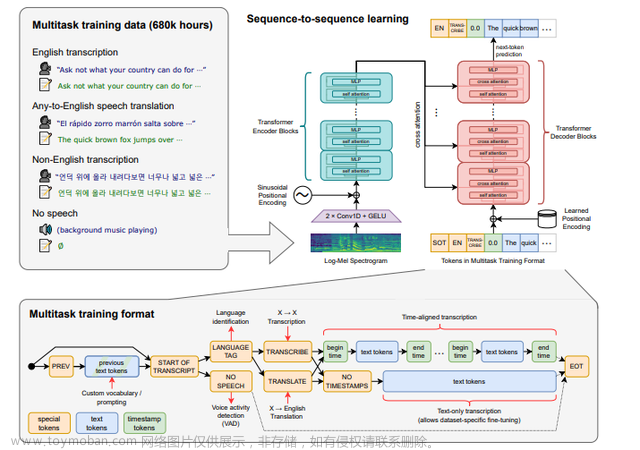
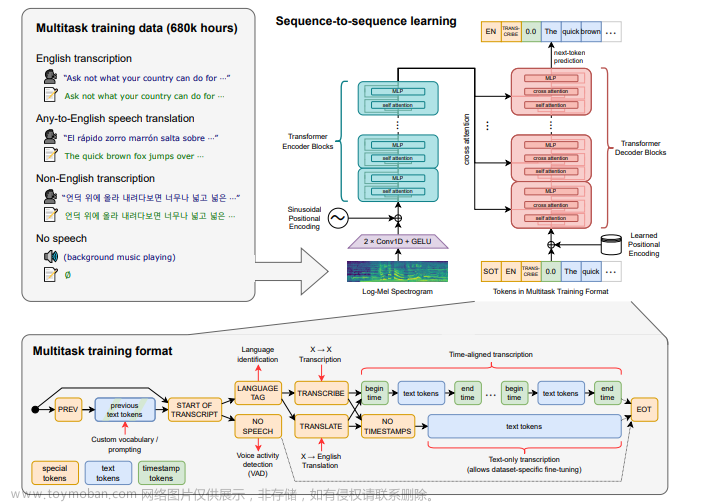
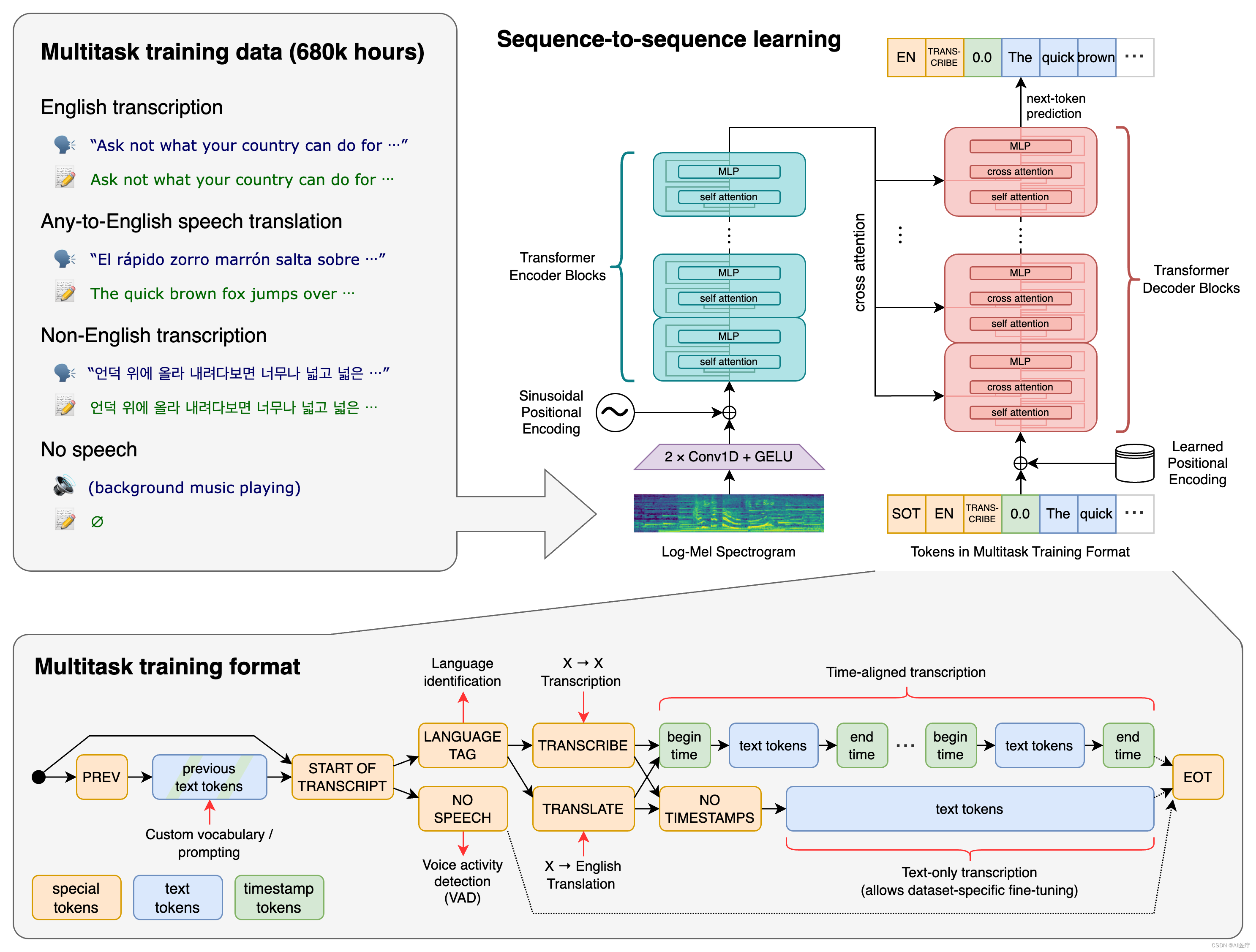
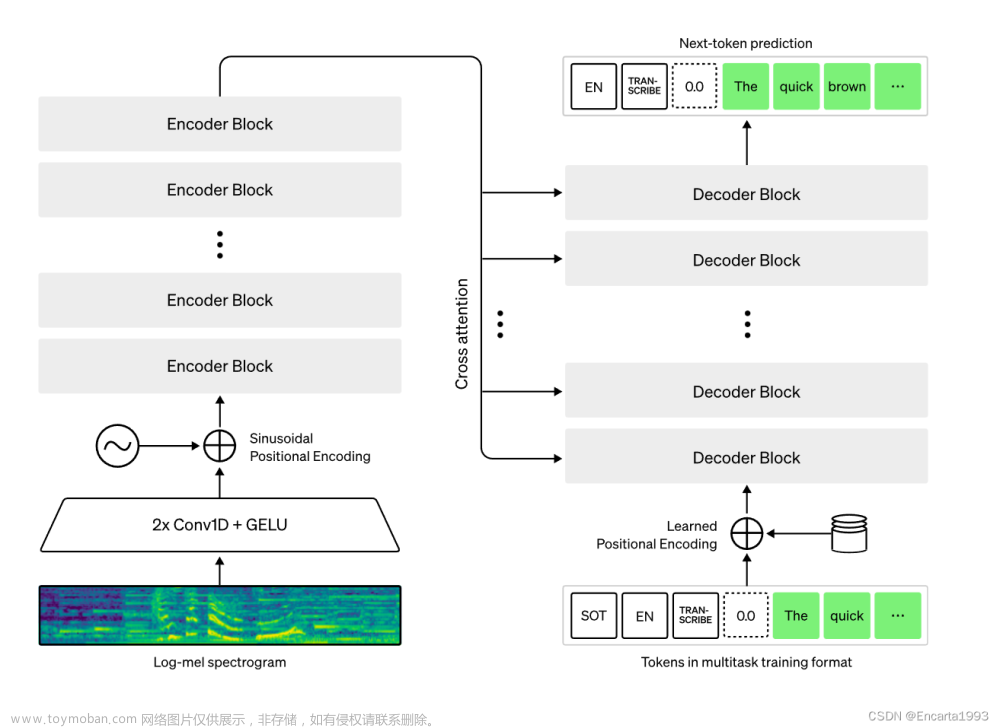
一种 Transformer 序列到序列模型被训练用于各种语音处理任务,包括多语种语音识别、语音翻译、口语语言识别以及语音活动检测。这些任务共同以一个需要被解码器预测的符号序列的形式进行表示,从而使得单个模型可以替代传统语音处理管道中的多个阶段。多任务训练格式使用一系列特殊的符号作为任务指示符或分类目标。
3、环境配置
conda create -n whisper python=3.9
conda activate whisper
pip install -U openai-whisper
sudo apt update && sudo apt install ffmpeg
pip install setuptools-rust
4、python测试脚本
- 以轻量级tiny模型为例,测试脚本如下:
import whisper
model = whisper.load_model("tiny")
result = model.transcribe("sample_1.wav")
print(result["text"])
测试结果如下:

- 如果要测试large模型,需要16GB以上的显卡才行。
注:以上测试脚本暂不支持多gpu,这是因为有可能在一个GPU上加载编码器,在另一个GPU上加载解码器。
如果想通过多gpu测试,可尝试以下方法:文章来源:https://www.toymoban.com/news/detail-486870.html
- 首先更新包,以便它有最新的提交
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git
- 然后,参考以下脚本:
import whisper
model = whisper.load_model("large", device="cpu")
model.encoder.to("cuda:0")
model.decoder.to("cuda:1")
model.decoder.register_forward_pre_hook(lambda _, inputs: tuple([inputs[0].to("cuda:1"), inputs[1].to("cuda:1")] + list(inputs[2:])))
model.decoder.register_forward_hook(lambda _, inputs, outputs: outputs.to("cuda:0"))
model.transcribe("jfk.flac")
多gpu脚本参考连接:https://github.com/openai/whisper/discussions/360文章来源地址https://www.toymoban.com/news/detail-486870.html
- 测试large模型(显存>=16GB),输入音频,输出文本(中文简体),需要设置initial_prompt,不然输出的可能是中文繁体
import whisper
import os
model = whisper.load_model("large")
prompt='以下是普通话的句子'
result = model.transcribe(file_path, language='zh',verbose=True, initial_prompt=prompt)
print(result["text"])
到了这里,关于OpenAI-whisper语音识别模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!