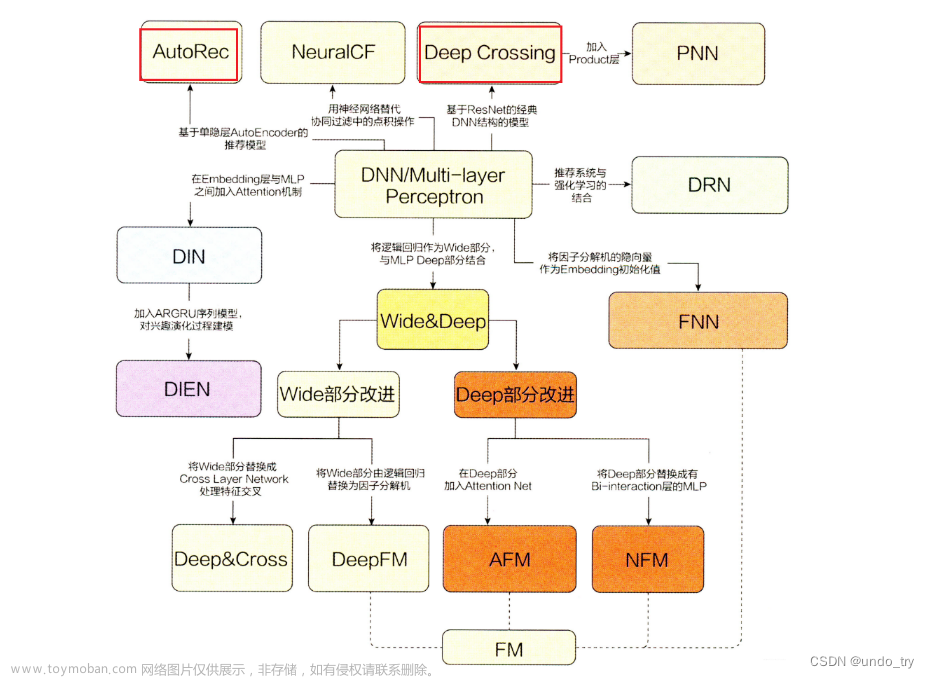
前言
在CTR预估中,FM系列模型使用浅层网络(线性模型),让模型自己学习特征组合交互,为显式建模的方式;而DNN系列模型使用深层网络,隐式挖掘模型的高阶特征交互。
本文继续介绍结合这两者优点的另外一个系列:Wide&Deep,即同时加入低阶特征组合交互的线性模型-Wide、高阶特征交叉的深度模型(Deep),Wide部分模型提供模型的记忆能力,而Deep部分提供模型的泛化能力。这是Wide&Deep系列模型很重要的一个点。
Wide & Deep
论文:Wide & Deep Learning for Recommender Systems
地址:https://arxiv.org/pdf/1606.07792.pdf
论文指出推荐系统的其中一个挑战在于同时兼顾memorization(记忆)和generalization(泛化):
- 记忆能力可以宽松地定义为从历史数据中学习items和特征的共现和相关性,对应逻辑回归这样的线性模型的学习模式,但它们不够泛化,无法处理训练样本中未出现过的query-item特征对;
- 泛化则是另外一方面的能力:相关性的传递和对于新的特征组合的探索,对应深度神经网络,通过将为特征学习一个低维的embedding向量来获得这样的泛化能力,但对于那些频次很低的query和item,学习一个有效的向量表征是困难的,比如有些用户的偏好是很狭隘少见的,那么它们应该跟大部分query-item pairs是没有交互的,但稠密向量会导致所有query-item pairs是nonzero的,直白说就是强行交互了,过度泛化了,因此出现无关的推荐;
- 另一方面,带有cross-product特征变换的线性模型,可以用很少的参数,记住(memorize)那些例外的规则(exception rules)。
论文提出的Wide & Deep学习框架就是为了兼具记忆和泛化,联合训练一个线性模型组件和一个深度神经网络模型组件,如下图:
Wide Component
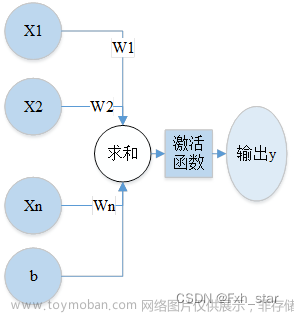
Wide组件是一个普通的线性模型,如上图[Wide&Deep框架]-左: y = w T x + b y=w^Tx+b y=wTx+b
其中,y是预估值,x是一个向量,包含了d个特征值 x = [ x 1 , x 2 , . . . , x d ] x=[x_1,x_2,...,x_d] x=[x1,x2,...,xd],w是模型的参数 w = [ w 1 , w 2 , . . . , w d ] w=[w_1,w_2,...,w_d] w=[w1,w2,...,wd],而b则是bias。
值得注意的是,x包括了原设的特征输入,还有变换过的特征,论文列出一个最重要的特征变化:cross-product
c k i c_{ki} cki是一个布尔变量,当第i个特征是第k个变换的一部分,取值为1,否则为0。比如有一个cross-product变换为“AND(gender=female, language=en)”,那么当且仅当所有组成特征都为1时, ϕ k \phi_k ϕk才等于1,其他情况都为0。
再对应解释下 c k i c_{ki} cki,如另外的特征(city)由于不是这个变换的部分,那么 c k i c_{ki} cki为0,任何取值下 x i c k i x_i^{c_{ki}} xicki都为1,不影响最终的 ϕ k \phi_k ϕk。
Deep component
Deep组件是一个前馈神经网络,如上图[Wide&Deep框架]-右。老生常谈,对于类别特征,原设输入是字符串(如‘language=en’,language有许多取值),每一个这样稀疏和高维的特征都会转换为一个低维和稠密的实值向量,即embedding vector。这些embedding vectors会被输入到神经网络的隐藏层:
其中,l是隐藏层的数量,f是激活函数(一般为ReLUs)。
联合训练
在这里,论文还说明了集成学习和联合训练的区别:
- 集成学习中,每个独立的模型在训练阶段是分开,无法获取其他模型的知识,仅仅在推理阶段组合它们的预测。而正是集成学习的训练不交叉的缘故,每个独立的模型规模通过会比较大,以为了能够取得更好的效果;
- 而联合训练在训练时,包括wide和deep组件,所有参数是同步更新的。wide组件是为了deep组件的弱势,因此wide组件仅仅是一些少量的cross-product特征变换。
在联合训练中,wide组件使用的优化器是带有L1正则的Follow-the-regularized-leader (FTRL),而deep组件使用的AdaGrad,最终组合的模型正如上图[Wide&Deep框架]-中,形式如下:
其中,
σ
(
⋅
)
\sigma(\cdot)
σ(⋅)是一个sigmoid函数,
a
(
l
f
)
a^{(l_f)}
a(lf)是最后一层网络经过激活函数的输出。
DeepFM
论文:DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
地址:https://www.ijcai.org/proceedings/2017/0239.pdf
DeepFM模型仍然可以认为是套用Wide&Deep的基础框架,但是DeepFM模型在以下几点上做了一些改进:
- wide部分使用了FM模型,来替代线性模型;
- wide和deep部分共享了同样的输入;
- wide和deep部分共享了feature embedding;
-
FM可以代替原来wide组件中的交叉特征工程,而feature embedding共享可以让模型同时学习低阶特征和高阶特征的交互能力。


对于FM模型系列,可以跳转到这篇文章FM/FFM/FwFM/FEFM
论文做了详细的超参数消融实验,具体结果如下图所示:
其中network shape表示:constant (200-200-200)、increasing (100-200-300)、decreasing (300-200-100)、diamond (150-300-150).
Deep&Cross(DCN)
论文:Deep & Cross Network for Ad Click Predictions
地址:https://arxiv.org/pdf/1708.05123.pdf
Deep & Cross Network (DCN)与DeepFM模型一样,基于Wide & Deep的框架,对wide部分进行改进:使用cross network,能够学习超过二阶的特征交互,同样可以摆脱人工特征工程。DCN模型结构如下图:
- 离散特征转化为embedding向量,然后与连续性特征进行拼接;
- 拼接后的特征,分别输入到多层MLP和Cross Network;
- 与DeeFM不同的是,MLP和Cross network不是输出标量,而是向量;
- 最后,MLP和Cross Network的输出向量进行拼接,再经过一层MLP(与权重相乘加上偏置),使用sigmoid函数得到最终的输出预测概率。

DCN中除了Cross network,其他部分与其他模型的基本一致,因此不再赘述,着重讲解cross network部分。
Cross Network
Cross Network是这篇论文的核心创新点-显示的特征交叉,它的公式形式如下式:

其中,
x
0
x_0
x0即是特征embedding拼接输入,
x
l
+
1
,
x
l
∈
R
d
x_{l+1},x_l\in \mathbb{R}^d
xl+1,xl∈Rd是d维的向量,分别代表第l和l+1层cross layer的输出,并且第l层在特征交叉(feature cross)之后,会加回原来的输入
x
l
x_l
xl,即让feature cross去拟合第l+1层与第l层的残差:
x
l
+
1
−
x
l
x_{l+1}-x_l
xl+1−xl
可以看出l层的cross network能够达到l+1阶的特征交叉,并且参数量仅为d的的线性关系: d × l × 2 d\times l \times 2 d×l×2
论文从三种角度来帮助分析理解cross network的有效性:polynomial approximation、generalization to FMs、efficient projection。在分别介绍这三种分析方法之前,先说明一些参数符号:
- w j ( i ) 是 w j w_j^{(i)}是w_j wj(i)是wj的第i个元素
- 交叉项索引: α = [ α 1 , α 2 , . . . , α d ] ∈ N d , ∣ α ∣ = ∑ i = 1 d α i \alpha=[\alpha_1,\alpha_2,...,\alpha_d]\in \mathbb{N}^d,|\alpha|=\sum_{i=1}^d\alpha_i α=[α1,α2,...,αd]∈Nd,∣α∣=∑i=1dαi
- x = [ x 1 , x 2 , . . . , x d ] x=[x_1,x_2,...,x_d] x=[x1,x2,...,xd]
- ∣ α ∣ |\alpha| ∣α∣决定了交叉项 x 1 α 1 x 2 α 2 ⋅ ⋅ ⋅ x d α d x_1^{\alpha_1}x_2^{\alpha_2}\cdot \cdot \cdot x_d^{\alpha_d} x1α1x2α2⋅⋅⋅xdαd的阶数,比如 α = [ 1 , 0 , 1 , 0 ] \alpha=[1,0,1,0] α=[1,0,1,0]即代表了2阶交叉,且交叉项为 x 1 x 3 x_1x_3 x1x3
Polynomial Approximation
对于n阶的多元(d元)多项式为,它的系数数量达到了
O
(
d
n
)
O(d^n)
O(dn),如下式:
但是,论文提出的cross network能够以O(d)的参数量,包含了上式多元多项式的所有交叉项,并且每个交叉项的系数都是不同的。
考虑一个l层的cross network,并且第i+1层的输出为: x i + 1 = x 0 x i T w i + x i x_{i+1}=x_0x_i^Tw_i+x_i xi+1=x0xiTwi+xi。
让输入为
x
0
=
[
x
1
,
x
2
,
.
.
.
,
x
d
]
x_0=[x_1,x_2,...,x_d]
x0=[x1,x2,...,xd],输出为
g
l
(
x
0
)
=
x
l
T
w
l
g_l(x_0)=x_l^Tw_l
gl(x0)=xlTwl,参数为
w
i
,
b
i
∈
R
d
w_i,b_i\in \mathbb{R}^d
wi,bi∈Rd,然后多元多项式
g
l
(
x
0
)
g_l(x_0)
gl(x0)可以变为下式:
- 其中, c α = M α ∑ i ∈ B α ∑ j ∈ P α Π w i k ( j k ) c_\alpha=M_\alpha\sum_{i\in B_\alpha}\sum_{j\in P_\alpha}\Pi w_{i_k}^{(j_k)} cα=Mα∑i∈Bα∑j∈PαΠwik(jk),
- M α M_\alpha Mα是一个与w无关的独立常量,
- i = [ i 1 , i 2 , . . . , i ∣ α ∣ ] 和 j = [ j 1 , j 2 , . . . , j ∣ α ∣ ] i=[i_1,i_2,...,i_{|\alpha|}]和j=[j_1,j_2,...,j_{|\alpha|}] i=[i1,i2,...,i∣α∣]和j=[j1,j2,...,j∣α∣]都是交叉项索引, B α = { y ∈ { 0 , 1 , . . . , l } ∣ α ∣ ∣ y i < y j ∧ y ∣ α ∣ = l } B_\alpha=\{y\in \{0,1,...,l\}^{|\alpha|}|y_i<y_j \wedge y_{|\alpha|}=l\} Bα={y∈{0,1,...,l}∣α∣∣yi<yj∧y∣α∣=l},
- P α = 1 , . . . , 1 ⏟ α 1 t i m e s . . . d , . . . , d ⏟ α d t i m e s P_{\alpha}=\underbrace{1,...,1}_{\alpha_1\ times}...\underbrace{d,...,d}_{\alpha_d\ times} Pα=α1 times 1,...,1...αd times d,...,d,是交叉项索引的所有排列组合。
- 举个例子,对于交叉项 x 1 x 2 x 3 x_1x_2x_3 x1x2x3,有 α = { 1 , 1 , 1 , 0 , . . . , 0 } \alpha=\{1,1,1,0,...,0\} α={1,1,1,0,...,0},第2层即l=2时, c α = ∑ i , j , k ∈ P α w 0 ( i ) w 1 ( j ) w 2 ( k ) c_{\alpha}=\sum_{i,j,k\in P_{\alpha}}w_0^{(i)}w_1^{(j)}w_2^{(k)} cα=∑i,j,k∈Pαw0(i)w1(j)w2(k)。而第3层即l=3时, c α = ∑ i , j , k ∈ P α w 0 ( i ) w 1 ( j ) w 3 ( k ) + w 0 ( i ) w 2 ( j ) w 3 ( k ) + w 1 ( i ) w 2 ( j ) w 3 ( k ) c_{\alpha}=\sum_{i,j,k\in P_{\alpha}}w_0^{(i)}w_1^{(j)}w_3^{(k)}+w_0^{(i)}w_2^{(j)}w_3^{(k)}+w_1^{(i)}w_2^{(j)}w_3^{(k)} cα=∑i,j,k∈Pαw0(i)w1(j)w3(k)+w0(i)w2(j)w3(k)+w1(i)w2(j)w3(k)
- 以上公式可以辅助下图展开进行理解:

可以看出,1、cross network的参数量能够比普通的多元多项式少的原因在于:参数w的共享,但每个特征交叉项又使用了不同的参数交叉,以达到不同系数的效果;
2、cross network是以bit-wise的方式来实现高阶特征交叉的。
Generalization of FMs
cross network借鉴了FM模型的参数共享的精髓,并且将其扩展到更深的结构。
- 在FM模型中,特征 x i x_i xi跟着权重向量 v i v_i vi,它与 x j x_j xj的交叉项 x i x j x_ix_j xixj的权重由 < v i , v j > <v_i,v_j> <vi,vj>计算而来。但DCN中, x i x_i xi的权重则是标量 { w k ( i ) } k = 1 l \{w_k^{(i)}\}^l_{k=1} {wk(i)}k=1l,交叉项 x i x j x_ix_j xixj的权重则变成了 { w k ( i ) } k = 0 l \{w_k^{(i)}\}^l_{k=0} {wk(i)}k=0l和 { w k ( j ) } k = 0 l \{w_k^{(j)}\}^l_{k=0} {wk(j)}k=0l两个集合的相乘
- 参数共享不仅可以使模型更加高效,对于训练样本中无共现的特征交叉,还能起到泛化的作用,更具鲁棒性,这也是FM模型的一个重要创新点
- 但是FM模型只限于二阶交叉,相比之下,DCN可以实现所有交叉项 x 1 α 1 x 2 α 2 ⋅ ⋅ ⋅ x d α d x_1^{\alpha_1}x_2^{\alpha_2}\cdot \cdot \cdot x_d^{\alpha_d} x1α1x2α2⋅⋅⋅xdαd的 ∣ α ∣ = l + 1 |\alpha|=l+1 ∣α∣=l+1阶交叉,由cross network的层数决定,并且参数量只是与输入维度d是线性关系。
Efficient Projection
记
x
~
\tilde{x}
x~为每一层的cross layer的输入,cross layer实现的其实就是隐式的组合
x
~
\tilde{x}
x~和x的所有pairwise interactions
x
i
x
~
j
x_i\tilde{x}_j
xix~j(
d
2
d^2
d2个),然后再隐式的投影(project)到维度d,有效将参数量由维度d的三次方减少到线性关系,从这里也可以看出参数量的减少得益于参数w共享: 其中,
w
∈
R
d
w\in \mathbb{R}^d
w∈Rd。回归到DCN,x则为
x
0
x_0
x0,那么
x
P
=
x
0
x
~
T
w
x_P=x_0\tilde{x}^Tw
xP=x0x~Tw
其中,
w
∈
R
d
w\in \mathbb{R}^d
w∈Rd。回归到DCN,x则为
x
0
x_0
x0,那么
x
P
=
x
0
x
~
T
w
x_P=x_0\tilde{x}^Tw
xP=x0x~Tw
实验结果
论文使用的数据集是:Criteo Display Ads Data,实验得到最好的结构是6层cross layer和2层1024size的deep layer,其他参数如下:
- batch_size为512
- 使用Adam优化器,并且梯度裁剪norm为100
- 学习率使用的递增方式,从0.0001到0.001,增值为0.0001
从下图也可以看出,加入cross layer之后,效果提升显著
DCN V2
论文:DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems
地址:https://arxiv.org/pdf/2008.13535.pdf
2017年提出DCN之后,该团队在2020年发表DCN-V2版本的论文,与DCN的区别在于Cross Network,在特征对交叉使用的权重使用了矩阵的形式,而DCN是向量形式,如下图所示:

但这样带来的参数量提升是巨大的,由原来的O(d)变为
O
(
d
2
)
O(d^2)
O(d2)。因此引入一种low-rank的方法,即将原来输入的直接投影(project),调整为先投影到低维度空间
R
r
\mathbb{R}^r
Rr,再重新投影回原来的维度
R
d
\mathbb{R}^d
Rd
当r<<d时,参数量可以显著减少。 U l , V l ∈ R d × r U_l,V_l\in \mathbb{R}^{d\times r} Ul,Vl∈Rd×r
上述,DCN是以bit-wise的方式来实现高阶特征交叉的,而DCN-V2不仅能视为bit-wise的交叉方式(可认为是cross network中权重w没有共享的的DCN,如下图[efficient projection]),也能够看成是feature-wise。

总结
Wide & Deep提出一种通用框架:wide组件的线性模型的显性低阶特征交叉提供记忆能力,deep组件的深度网络模型的隐式高阶特征交叉提供泛化能力;
DeepFM模型则是在此基础,加强wide部分的能力,将线性模型替换为FM模型,并且大大减少特征工程;
Deep & Cross又是进一步提升wide部分的能力,突破FM浅层网络的二阶特征交叉能力限制,使用深层网络来实现高阶的显式特征交叉,并且参数量能够保持在输入维度的线性关系。
代码实现
DCN文章来源:https://www.toymoban.com/news/detail-486883.html
DeepFM文章来源地址https://www.toymoban.com/news/detail-486883.html
到了这里,关于CTR预估之Wide&Deep系列模型:DeepFM/DCN的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!