ES集群搭建实践
虚拟机安装
下载地址
Windows & Linux:WMware Workstation 16 Pro
MacOS:WMware Fusion
构建CentOS镜像
下载系统镜像
下载地址:https://centos.org/download/
选择符合符合你电脑的指令集版本,比如我的CPU是 x86_64架构
配置网卡信息
vi /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="none" # 关闭dhcp,需要固定ip
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="6dcded77-ba54-4f70-a16c-80535656ba86"
DEVICE="ens33"
ONBOOT="yes"
IPADDR="192.168.3.81" #修改每个节点的ip地址
PREFIX="24"
GATEWAY="192.168.3.1" ## 确定网关地址
DNS1="114.114.114.114"
DOMAIN="8.8.8.8"
IPV6_PRIVACY="no"
重启网卡
service network restart
网卡重启报错的话,重启虚拟机
网卡验证
远程登录验证
创建elastic用户
使用elasticsearch账号操作:启动,关闭等
创建用户
useradd elastic
修改密码命令
passwd elastic
账号添加到sudoer
elastic is not in the sudoers file
su
visudo -f /etc/sudoers
## Then add the user below admin user like below syntax.
elastic ALL=(ALL) ALL
配置Java环境
下载ES
虚拟机直接下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.0-linux-x86_64.tar.gz
yuminstall
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/rpm.html#rpm-repo
官网手动下载
ES下载地址
https://www.elastic.co/guide/en/elasticsearch/reference/8.8/rpm.html#rpm-repo
ES7下载地址
linux version
https://www.elastic.co/downloads/past-releases/elasticsearch-7-17-10
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/rpm.html#rpm-repo
https://www.elastic.co/downloads/past-releases#elasticsearch 浏览各种release版本
docker version
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/docker.html
本地与目标服务器传输文件
scp elasticsearch-7.17.10-linux-x86_64.tar.gz elastic@node151:~/
解压文件
tar -xzf you.tar.gz
z : gz
x:extract
f: file name
创建数据存储目录
生产环境不允许把data和log放在elasticsearch中
sudo mkdir -p /opt/elasticsearch/data
sudo mkdir -p /opt/elasticsearch/logs
sudo chown -R elastic:elastic /opt/elasticsearch
退出Session使配置生效
quit terminal
修改配置文件
单集群单节点配置
cluster.name: zgc-cluster
node.name: node151
network.host: 172.16.193.151
http.port: 9200
transport.port: 9300
## discovery.seed_hosts: ["172.16.193.152:9300","172.16.193.153:9300"]
cluster.initial_master_nodes: ["node151"]
##cluster.initial_master_nodes: ["node152"]
* cluster.name:集群名称,节点根据集群名称确定是否是同一个集群。节点自动互相发现就根据这个名称
* node.name:节点名称,集群内唯一。
* node.roles:[ data, master, voting_only ],`node.roles`配置项如果没有显式的配置,那么当前节点拥有所有角色(master、data、ingest、ml、remote_cluster_client、transform)。如果你放开了注释,或者手动显式添加了 `node.roles`配置项,那么当前节点仅拥有此配置项的中括号中显式配置的角色,没有配置的角色将被阉割。因此如果在不熟悉角色配置的情况下,不要轻易修改角色配置值, **切勿画蛇添足** **。**
* network.host: 节点对外提供服务的地址以及集群内通信的ip地址
* network.publish_host : 如果在一个局域网,节点之间通过network.host进行通信,如果不在一个局域网就需要publish_host。生产环境一般不允许公网地址,因为影响通信效率
* bootstrap.memory_lock: Swapping对性能和节点稳定性非常不利,应该不惜一切代价避免。它可能导致GC持续**几分钟**而不是几毫秒,并且可能导致节点响应缓慢甚至与集群断开连接。在弹性分布式系统中,使用Swap还不如让操作系统杀死节点效果更好。可以通过设置 `bootstrap.memory_lock: true` 以防止任何 Elasticsearch 堆内存被换出。
* http.port:对外提供服务的端口号
* discovery.seed_hosts: 集群初始化的种子节点,可配置部分或全部候选节点,大型集群可通过嗅探器发现剩余节点,考试环境配置全部节点即可
* cluster.initial_master_nodes:节点初始 `active master`节点, 必须是有master角色的节点,即必须是候选节点,但并不是必须配置所有候选节点。生产模式下启动新集群时,必须明确列出应在第一次选举中计算其选票的候选节点。第一次成功形成集群后,`cluster.initial_master_nodes`从每个节点的配置中删除设置。重新启动集群或向现有集群添加新节点时,请勿使用此设置。
增加max file descriptors
一般修改 /etc/security/limits.conf
sudo vim /etc/security/limits.conf
/etc/sysctl.conf 这个文件是所有共享的上限
* soft nofile 65536
* hard nofile 65536
fs.file-max = 190000
使配置生效
sudo sysctl -p
# Do not forget to reboot or: sysctl --system
查看是否生效
ulimit -n 65536
增加 vm.max_map_count
sudo vim /etc/sysctl.d/99-sysctl.conf
增加如下内容:
vm.max_map_count=362144
使能配置:
sudo sysctl -p
启动服务
# 前台进程
./bin/elasticsearch
# 后台启动 守护进程
./bin/elasticsearch -d
# 推荐方式(保存进程号 不占用窗口,并且方便杀进程): 它会在当前目录保存一个pid文件,方便查找
./bin/elasticsearch -d -p pid
关闭服务
ps -ef | grep elastic
OR
# kill by pid file
kill -9 `cat pid`
pkill -F pid
启动后验证
http://172.16.193.151:9200/
http://172.16.193.151:9200/_cat/nodes?v
常见问题
本地无法访问服务
关闭防火墙,生产环境建议仅开放指定端口
# 关闭防火墙
systemctl stop firewalld
# 禁用防火墙
systemctl disabled firewalld
修改 max file descriptors
-
fs.file-max:这个参数定义了整个系统中可以打开的文件描述符的最大数量。它表示系统范围内的限制。当系统达到这个限制时,将无法打开更多的文件描述符。可以通过修改该值来增加系统的文件描述符限制。 -
* hard nofile 65536:这是/etc/security/limits.conf文件中的一行配置,它指定了用户的硬限制(hard limit)的文件描述符数量。hard limit是用户或进程的最大限制值,超过这个限制将导致系统返回错误。在这个例子中,nofile(即文件描述符)的硬限制被设置为 65536。这个配置会影响所有用户。 -
* soft nofile 65536:这也是/etc/security/limits.conf文件中的一行配置,它指定了用户的软限制(soft limit)的文件描述符数量。soft limit是用户或进程的警告值,超过这个限制会产生警告,但允许继续增加。在这个例子中,nofile(即文件描述符)的软限制被设置为 65536。这个配置会影响所有用户。
Linux中修改文件描述符(file descriptors)的方法有多种。下面列举了一些常见的方法:
- 命令行参数:在运行程序时,可以使用命令行参数来设置文件描述符的数量。例如,通过
ulimit命令可以设置进程的最大文件描述符数量,如ulimit -n 1024表示将最大文件描述符数量设置为1024。
ulimit -n 65536
- 修改配置文件:可以通过修改系统的配置文件来调整文件描述符的数量限制。在Linux系统中,有两个主要的配置文件与文件描述符相关:
/etc/security/limits.conf和/etc/sysctl.conf。在这些配置文件中,可以设置文件描述符的软限制和硬限制,以及其他相关参数。
一般修改 /etc/security/limits.conf
sudo vim /etc/security/limits.conf
/etc/sysctl.conf 这个文件是所有共享的上限
* soft nofile 65536
* hard nofile 65536
fs.file-max = 190000
OR
elastic soft nofile 65536
elastic hard nofile 65536
fs.file-max = 190000
- 编程方式:通过编程语言(如C、C++、Java等)的API,可以在程序中设置文件描述符的数量。这通常涉及到使用系统调用(如
setrlimit)或编程语言提供的相关函数。
这些配置方法的区别与联系如下:
- 临时修改适用于临时调整配置,对当前会话有效,重启后会恢复为默认值。
- 持久修改适用于永久性调整配置,会将修改写入配置文件中,重启后仍然有效。
文件描述符的修改与登录用户相关。在Linux系统中,每个用户都有自己的文件描述符限制。用户可以通过上述方法中的命令行参数或配置文件来调整自己的文件描述符数量限制。登录用户可以根据自身需求灵活地调整文件描述符的数量。
** 不同用户之间的文件描述符配置是相互独立的,即每个用户可以根据自己的需要设置文件描述符的数量。因此,文件描述符的修改配置是与用户相关的,不同用户之间的文件描述符是独立的,不会相互影响。每个用户可以根据自己的需求进行个性化的配置,而不会对其他用户产生影响。**
使配置生效
sudo sysctl -p
# Do not forget to reboot or: sysctl --system
验证max file descriptors配置是否生效
ulimit -n
max virtual memory areas vm.max_map_count [65530] is too low
当出现"max virtual memory areas vm.max_map_count [65530] is too low"的错误消息时,这表示操作系统的虚拟内存区域数量限制太低,无法满足当前的需求。解决此问题的常见方法是增加vm.max_map_count的值。
在Linux系统中,有几种配置方法可以调整vm.max_map_count的值:
-
临时修改:可以使用以下命令临时修改
vm.max_map_count的值:sysctl -w vm.max_map_count=362144 ## the setting will only last for the duration of the session. If the host reboots, the setting will be reset to the original value. ## If you want to set this permanently, you need to edit /etc/sysctl.conf and set vm.max_map_count sudo vim /etc/sysctl.conf这种方法只在当前会话中生效,重启后会恢复为默认值。
-
持久修改:
在 Linux 系统中,可以通过以下几个文件来修改
vm.max_map_count参数:-
/proc/sys/vm/max_map_count:这是一个虚拟文件,它提供了对内核参数vm.max_map_count的读写访问。您可以直接编辑该文件,将所需的值写入其中。但是,修改的值只会在当前会话中生效,重启系统后会重置为默认值。 -
/etc/sysctl.conf:这个文件用于设置系统级别的内核参数。您可以在文件中添加一行类似vm.max_map_count=65530的配置,并保存文件。在下次系统启动时,内核会加载该文件,并根据配置进行相应的参数设置。修改该文件可以使配置在系统重启后仍然生效。 -
/etc/sysctl.d/目录:在某些 Linux 发行版中,您可以将包含*.conf扩展名的文件放置在/etc/sysctl.d/目录中。这些文件中的配置会在系统启动时自动加载,并覆盖默认的内核参数设置。您可以创建一个新的文件,例如99-custom.conf,在其中添加vm.max_map_count=65530的配置,并保存文件。请注意,这些文件会按字母顺序加载,因此确保文件名的顺序正确以避免冲突。
sudo vim /etc/sysctl.d/99-sysctl.confAdd to file :
vm.max_map_count=362144 fs.file-max = 190000然后保存文件并执行以下命令使配置生效:
sudo sysctl -p # Do not forget to reboot or: sysctl --system -
-
通过限制文件:有时操作系统可能对修改
vm.max_map_count的值有限制。在这种情况下,可以尝试通过限制文件来修改该值。在/etc/security/limits.conf文件中,sudo vim /etc/security/limits.conf添加以下行:
* hard memlock unlimited
这些配置方法的区别与联系如下:
- 临时修改适用于临时调整配置,对当前会话有效,重启后会恢复为默认值。
- 持久修改适用于永久性调整配置,会将修改写入配置文件中,重启后仍然有效。
- 通过限制文件修改
vm.max_map_count的值可以绕过一些操作系统对配置修改的限制。
对于这个问题,不同用户无需单独配置。一旦修改了vm.max_map_count的值,对于所有用户来说都会生效。因为该配置是作用于整个操作系统的虚拟内存区域,所以不需要为每个用户单独配置。任何登录到系统的用户都将受到新的vm.max_map_count值的影响。
修改limits.conf和sysctl.conf区别
-
/etc/security/limits.conf:- 作用:
limits.conf文件的配置是针对用户级别的,包括文件描述符限制。可以为每个用户或用户组设置不同的限制。 - 文件描述符限制:通过
nofile或nofiles参数可以设置每个用户(或用户组)可以打开的文件描述符的最大数量。该参数的值表示用户(或用户组)可以同时打开的文件或网络套接字的数量。生效范围:配置limits.conf文件后,对应的限制会应用于特定的用户或用户组,而不会影响整个系统的其他用户。
- 作用:
-
/etc/sysctl.conf:- 作用:sysctl.conf`文件的配置是针对整个系统的内核参数,包括系统级别的配置。适用于所有用户。
- 文件描述符限制:通过修改
fs.file-max参数可以调整系统级别的文件描述符限制,指定整个系统可以打开的文件描述符的最大数量。 - 生效范围:配置
sysctl.conf文件后,对应的内核参数会影响整个系统的所有用户,即所有用户共享相同的文件描述符限制。
总结:
-
/etc/security/limits.conf用于设置用户级别的资源限制,包括文件描述符限制,配置针对用户或用户组,并且对应的限制仅适用于指定的用户或用户组。 -
/etc/sysctl.conf用于设置系统级别的内核参数,包括文件描述符限制,配置对整个系统生效,所有用户共享相同的限制。这句话指的是所有用户加起来不能超过这个值。所以就要注意limits和sysctl之间的数量关系,sysctl中的配置一定要大于limit
max file descriptors too low 没有生效原因
- 没有改配置文件
vim /etc/security/limits.conf
* hard memlock unlimited
* soft nofile 65536
* hard nofile 65536
elasticsearch soft nofile 65536
elasticsearch hard nofile 65536
sudo vim /etc/sysctl.conf
vm.max_map_count=362144
- 没有执行
sudo sysctl -p
- 没有重启终端
通过执行ulimit -n如果仍然不行则:
如果仍然不行,则退出当前shell session(terminal),重新登录。亲测有效。
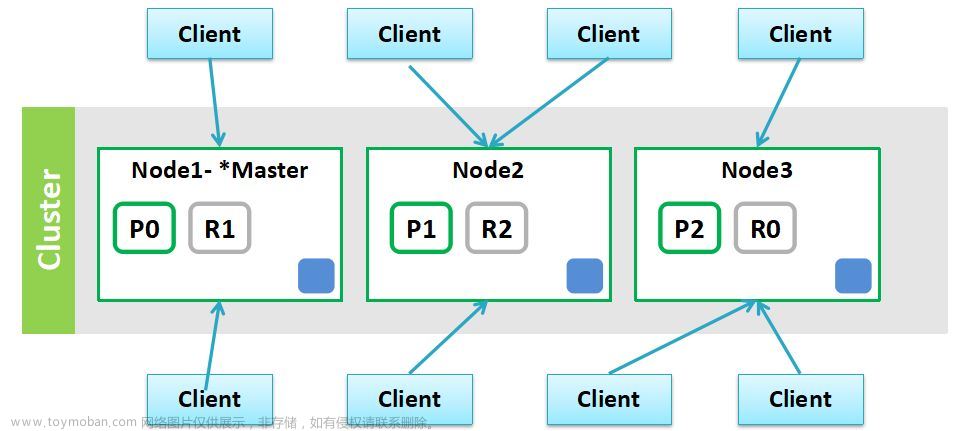
两个节点的集群为什么都成为master了
- 选举票数导致的问题,你需要设置2n+1
- 节点名字重复了: 修改node.name
- 发生脑裂了: 删除data目录然后重启
生产环境注意事项
data和log目录一定不要默认
如果es本身的一些升级等操作很可能被覆盖,所以硬性要求必须配置到es目录之外
vim config/elasticsearch.yml
modify文章来源:https://www.toymoban.com/news/detail-487021.html
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
#path.logs: /path/to/logs
 文章来源地址https://www.toymoban.com/news/detail-487021.html
文章来源地址https://www.toymoban.com/news/detail-487021.html
到了这里,关于从0到1ES集群搭建实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!