初探Bert
因为一次偶然的原因,自己有再次对Bert有了一个更深层地了解,特别是对预训练这个概念,首先说明,自己是看了李宏毅老师的讲解,这里只是尝试进行简单的总结复述并加一些自己的看法。
说Bert之前不得不说现在的语言模型与芝麻街有密切的联系了:
What is pre-train
以前,在自然语言处理中,是一个任务就有一个对应的模型来使用,但是现在却出现了另外一种设计方法——预训练。
这篇文章分析了预训练模型的由来,我认为就是原来的word embedding由于无法解决不同语义下不同词的不同性,因此才有了这样的大模型。
但是我个人认为Bert这样的预训练模型既可以是属于sentence level的,也可以属于word level的,因为如果从预训练任务上来考虑,BERT是sentence level的;如果从输出层面上来看,每一个word Token对应不同的represence,这样又是word level。
预训练的设计思路是这样的,先通过在大量的文章进行无监督训练,让模型具有一定的语言能力,然后再根据不同的任务进行微调,具体来说可以用下图来表示:
那么现在就可以认为预训练模型其实就是生成embedding vector,即将每一个token转变成embedding vector。以前的方法是用Word2vector,现在来说,就是用预训练模型来实现的。
不同的预训练模型可以使用不同的架构,比如说现在的ELMo使用的就是LSTM来实现的,Bert使用的就Transformer来实现的。
How to fine-tuned
我们目前知道了预训练模型其实就是生成了embedding vector ,但是如何用到不同任务领域呢?
那就是需要用到fine-tune来实现了,其实微调的本质就是在预训练模型之后添加一个任务层就好:
为了更好地说明如何微调,这里简单地根据输入和输出将NLP概括成2类的输入问题和4类的输出问题。
首先看输入部分:
- 输入的是一个句子:那就直接丢入模型中就好;
- 如果是输入了多个句子(这里以两个句子来说明):将两个句子合并成为一个句子就好,只不过需要对输入的句子做划分,这样才可以说明句子中的token是来自于哪个句子的;这里以QA问题来说明,那么两个句子就是一个句子对<Query, Answer>,只不过需要在两个句子中添加一个分隔符[SEP]
输入部分:
- 单分类问题
- 这个问题的处理方法,以BERT为例,BERT中是使用了一个特殊的符号[CLS],只要是输入了这个符号在句子的首位置,那么就是说明这是一个分类问题,那么最后预训练模型的输出应该是在第一个位置考虑整个句子的文字情况(也就是在预训练过程中,训练告诉模型,一旦看到了[CLS],就产生和整个句子有关的embedding)。
- 对于多分类问题,就可以用下面的图示的方法来做:
- 问答问题(copy from input)
- 这个任务具体来说就是根据输入的文本,能狗根据文章中的信息来回答所提问的问题,根据下图来说是就是需要模型能够预测出问题在文中的起始位置s和结束位置e。
- sequence问题
- 这个问题就来说一下怎么实现seq2seq模型,其实很简单地就可以想到seq2seq的实现方法就是用两个模型的拼接就好(encode和decode),如下图所示,但是这样的模型就存在了一个问题——Decoder没有pre-train,那么就还需要继续训练,这样就与我们预训练的初心相违背了。
- 因此基于这个问题,对预训练模型进行修改如下
- 这个问题就来说一下怎么实现seq2seq模型,其实很简单地就可以想到seq2seq的实现方法就是用两个模型的拼接就好(encode和decode),如下图所示,但是这样的模型就存在了一个问题——Decoder没有pre-train,那么就还需要继续训练,这样就与我们预训练的初心相违背了。
至此我们已将NLP中存在的任务进行了简要的概述,那么回到这一小节的主题——如何微调。
微调有两种方法:
- 一种是只需要微调自己的任务层,预训练的部分不需要做改动;
- 另一种就是将预训练的部分和任务层看成一个整体来进行微调的工作(这样的效果更好一些);
这里无意间发现了
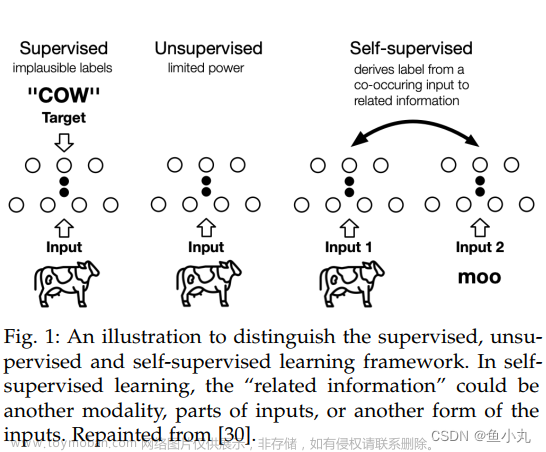
self-supervised learning的定义是来自Yann LeCun,他定义了将这种无监督的训练方法定义叫做自监督的训练,因为模型的输入和输出都是模型自己找到的,并非是人工标注的。
BERT
Abstract
好了,言归正传,BERT的出现真的是在NLP领域掀起了一阵不小的轰动,从BERT文章的Abstract部分就可以看出,BERT是结合了GPT和ELMo两个模型的框架特点——是一个深层次的以Transformer为Backbone的双向架构。这样的设计的方法可以在预训练之后的BERT模型之上添加一个额外的输出层便可以实现各种下游任务(其实这个地方就是微调,跟GPT一样,只需要改上层结构就可以了)。
Introduction
文中说到,NLP中的任务可以分为两个方向:
- sentence-level tasks——如句子分类、情感分析和语言推理等;
- token-level tasks——如NER、问答等
在使用预训练模型做特征表示的时候,一般是有两类策略:
-
feature-based——基于特征的,以ELMo为例,使用ELMo的时候需要根据任务构建一个特定的框架,然后将预训练模型得到的特征表示作为模型额外的输入一起输入构造的模型当中。
-
下图取自Improving a Sentiment Analyzer using ELMo — Word Embeddings on Steroids这篇文章,下图说明了ELMo的工作方式。
下图是说明feature-based的方式:
-
-
fine-tuning——基于微调的,以GPT为例(其实BERT本身也是用的fine-tune),主要就是根据不同的下游任务对模型中的所有参数进行简单的微调即可。
由于标准的语言模型本身是单向的,这样的训练方式就限制了预训练模型表征能力,存在一定的局限性,因此文中提出了改进,即BERT的是基于双向设计的。
但是这个BERT的框架从细节上还是跟我想到的是不一样的,因为原文中只是说其只是采用了Transformer的encoder部分,那么到底是什么样子的,我从别的地方找到了BERT的框架:
模型可以简单的归纳为三个部分,分别是输入层,中间层,以及输出层。这些都和transformer的encoder一致,除了输入层有略微变化
Pretext task
pretext tasl1
BERT是这样设计的(这也是BERT模型的创新点或者贡献之一),提出了MLM(Masked Language Model),这种带掩码的语言模型是这样设计的:
-
随机把一句话中15%的token(字或词)替换成以下内容:
-
这些token有80%的几率被替换成
[MASK],例如my dog is hairy→my dog is [MASK] -
有10%的几率被替换成任意一个其它的token,例如my dog is hairy→my dog is apple
-
有10%的几率原封不动,例如my dog is hairy→my dog is hairy
-
这个地方为什么这样设计,我至今也没搞明白为什么。
文中在附录
C.2中提到了这个MASK的问题,他是这样解释的——“Note that the purpose of the masking strategies is to reduce the mismatch between pre-training and fifine-tuning, as the [MASK] symbol never appears during the fifine-tuning stage.”也就是说该策略令到BERT不再只对[MASK]敏感,而是对所有的token都敏感,以致能抽取出任何token的表征信息。意思是说,首先模型是不知道哪个位置是需要被预测的,但是每个位置有15%的可能性是[MASK]这个特殊Token,但是实际上这15%中只有80%才会被替换成[MASK]。
对于语言模型的预测,文中是这样说的“ the fifinal hidden vectors corresponding to the mask tokens are fed into an output softmax over the vocabulary, as in a standard LM”这样模型就不回仅仅看到[MASK]就预测了,也就是说[MASK]还仅仅是一个Token罢了,模型是不知道这个位置是需要去预测的,因为最后是经过了一个softmax层,故这样的做的目的纯粹就是让模型自己学习预测每个位置的可能性,[MASK]位置可能就是所有token的可能性,但是不评论模型做得是否对。
同时在附录
A.1中也提到“The advantage of this procedure is that the Transformer encoder does not know which words it will be asked to predict or which have been replaced by random words, so it is forced to keep a distributional contextual representation of every input token. Additionally, because random replacement only occurs for 1.5% of all tokens (i.e., 10% of 15%), this does not seem to harm the model’s language understanding capability“。也就是说采用MASK的方法可以让预训练模型来学习分布式上下文的表征。
文章在
C.2中也做了消融实验,说明了为什么要这样定义,从验证集的效果上说明了这样定义的效果:In the table, MASK means that we replace the target token with the [MASK] symbol for MLM; SAME means that we keep the target token as is; RND means that we replace the target token with another random token.
-
-
这样的设计方法可以不仅仅是只能看前面的语言信息来预测后面的语言信息了。
pretext task2
除了提出了一个语言模型之外,文中还提出了一个任务叫做——“next sentence prediction”(贡献二),这个任务的思想就是给你两个句子(文中称为句子对),让你判断两个句子是不是相邻的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zQ53mzcm-1686469797592)(null)]
仅仅一个MLM任务是不足以让 BERT 解决阅读理解等句子关系判断任务的,Next Sequence Prediction(NSP)任务判断句子B是否是句子A的下文,如果是的话输出’IsNext‘,否则输出’NotNext‘。这样可以使模型学习句子层面上的信息。
到底这个next sentence prediction对预训练模型有没有用,文中也做了消融实验,效果如下:
补充:
在19年有文章说明了这个NSP的效果,对于BERT理解句子层面上的信息,产生的效果作用很小:
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Man-dar Joshi, Danqi Chen, Omer Levy, Mike Lewis,Luke Zettlemoyer, and Veselin Stoyanov. 2019.Roberta: A robustly optimized bert pretraining ap-proach. arXiv preprint arXiv:1907.11692
下面这篇文章指出了
On the Sentence Embeddings from Pre-trained Language Models
以上这两个创新点是为了预训练BERT而提出的,也就是说通过这两个任务可以让BERT通过自监督学习的两个任务来学习相关的表征然后应用到不同的下游任务。
这篇文章中也总结了在NLP中其他自监督预训练任务
Detail
文章对BERT对工作划分为两个部分:预训练和微调。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-89LlItyC-1686469797772)(null)]
通过上图可以看出,BERT预训练是在大量的无标签的句子对上进行训练的,而在微调的时候,根据不同的任务,使用相同的预训练模型的权重,然后进行微调。
文中说自己训练了两个BERT模型,一个是 B E R T B A S E BERT_{BASE} BERTBASE(L=12,H=768,A=12),另一个是 B E R T L A R G E BERT_{LARGE} BERTLARGE(L=24,H=1024,A=16), 因为该模型的Backbone是采用了Transformer,因此这里的参数都是指代的Transformer里面的参数,这里就不解释了。
输入和输出
BERT预训练的输入被定义为“sequence”,这个sequence被描述为一个或者两个句子的集合,其中序列的词典是由WordPiece方法生成的。
WordPiece这个方法是将每一个单词作为处理单元,但是考虑到单词的复合型(存在词根或词缀)的现象,或者说某些词出现的频率很小,因此会将一个很长的词进行切分,这样的话就可以用一个大小为3w的token 字典来表示了。
# wordpiece就是一个subword的编码方式,经过WordpieceTokenizer 之后,将词变为了word piece, 例如: input = "unaffable" output = ["un", "##aff", "##able"] # 其中##表示紧跟的意思这样子的好处是,可以有效的解决OOV的问题,但是mask wordpiece的做法也被后来(ERNIE以及SpanBERT等)证明是不合理的,没有将字的知识考虑进去,会降低精度,于是google在此版的基础上,进行Whole Word Masking(WWM)的模型。需要注意的是,中文的每个字都是一个word piece,所以WWM的方法在中文中,就是MASK一个词组。
对于输入的sequence来说,第一个Token永远都是[CLS]的特殊token,这个特殊token会在最后的隐藏层中,被用来表示整个句子的分类任务。
另外,为了区分两个句子,文中说到了两个方式:
- 两个句子之间添加一个特殊的token——[SEP];
- 针对每一个输入的token,需要添加一个learned 嵌入层(Embedding)来表示token是属于sentenceA还是sentenceB的
- 在下图中红框里面的
E向量就是需要学习的嵌入层Embedding - [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-omgD9eRT-1686469797553)(null)]
- 在下图中红框里面的
对于BERT的输入(也就是输入到Transformer里面的数据),是由三部分构成的(如下图所示),分别是Token嵌入层(这里没有明确说明是怎么得到的,我在某篇博客看到BERT这部分的实现是用了nn.Embddding来实现的)+句子嵌入层+位置嵌入层(位置嵌入层是经过学习得来的,并非是跟Transformer里面一样是计算出来的)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SsBIXKt8-1686469797572)(null)]
在BERT中,不管是Position Embedding(该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合)还是Segment Embeddings(由于出现在文本不同位置的字/词所携带的语义信息存在差异(比如:“我爱你”和“你爱我”),因此,BERT模型对不同位置的字/词分别附加一个不同的向量以作区分)都是自己学习得到的(也就是说一开始是随机生成的,让模型自己学习)。
这篇文章从源码的角度上分析了为何是使用这三种相加,以及如何使用这三种嵌入层的信息相加。
BERT模型的主要输入是文本中各个字/词(或者称为token)的原始词向量,该向量既可以随机初始化,也可以利用Word2Vector等算法进行预训练以作为初始值;
输出是文本中各个字/词融合了全文语义信息后的向量表示
预训练
在预训练过程中,其实就是围绕着两个任务来做的,一个是Masked LM的训练,另一个就是NSP(Next Sentence Prediction)
其实我一直对如何预训练的过程不了解,也不明白是怎么用这两个任务来做预训练的,文中只是说进行预测,那么到底是怎么预测的还是不知道的,还需要继续探索。
至此,笔记的记录已经结束,原文的剩下部分就是介绍如何微调的,这里就不做讨论了。
参考
-
https://www.nowcoder.com/discuss/351902
-
部分代码:https://zhuanlan.zhihu.com/p/103226488
-
[PPT下载链接](https://pan.baidu.com/s/1LovEFd4Fswwk0jr8wIKkvA?pwd=ajh9 提取码:ajh9)
-
关于BERT预训练的knowlage
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EFKESPnV-1686469794665)(null)]
- 自监督学习: 人工智能的未来从CV到NLP
关于机器学习的作用,LeCun做了一个形象的比喻,如下图所示:强化学习像蛋糕上的樱桃,监督学习像蛋糕上的糖霜,而自监督学习是蛋糕本身。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n22C1i9Y-1686469797756)(null)]
通过这个比喻,可以很好的理解自监督学习在人工智能中的重要基石作用。
-
什么是自监督学习:https://amitness.com/2020/02/illustrated-self-supervised-learning/
中文:https://zhuanlan.zhihu.com/p/110278826文章来源:https://www.toymoban.com/news/detail-487023.html
-
我的博客链接文章来源地址https://www.toymoban.com/news/detail-487023.html
到了这里,关于初探BERT&Pre-train&Self-supervise的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!