注意力机制和Transformer
机器翻译是NLP领域中最重要的问题之一,也是Google翻译等工具的基础。传统的RNN方法使用两个循环网络实现序列到序列的转换,其中一个网络(编码器)将输入序列转换为隐藏状态,而另一个网络(解码器)则将该隐藏状态解码为翻译结果。但是,这种方法存在两个问题:
- 编码器网络的最终状态难以记住句子开头,导致对于长句子的模型质量较差。
- 序列中的所有单词对结果的影响是相同的,但实际上,输入序列中特定的单词往往对顺序输出的影响大于其他单词。
注意机制
注意机制提供了一种权衡每个输入向量对RNN每个输出预测的上下文影响的方法。具体实现是在输入RNN和输出RNN之间创建快捷方式。这样,在生成输出符号yt时,我们将考虑所有输入隐藏状态hi,具有不同的权重系数αt,i。


注意机制对于NLP的许多当今或即将达到的最新技术水平负有责任。添加注意机制增加了模型参数的数量,这导致了RNN的扩展问题。扩展RNN的关键限制是,模型的循环性质使批处理和并行化训练变得具有挑战性。在RNN中,序列的每个元素都需要按顺序处理,这意味着它不能轻松并行化。

带注意机制的编码器解码器模型
引入注意机制后,结合这个约束,导致了现在我们所知道和使用的Transformer模型的创建,例如BERT到Open-GPT3。
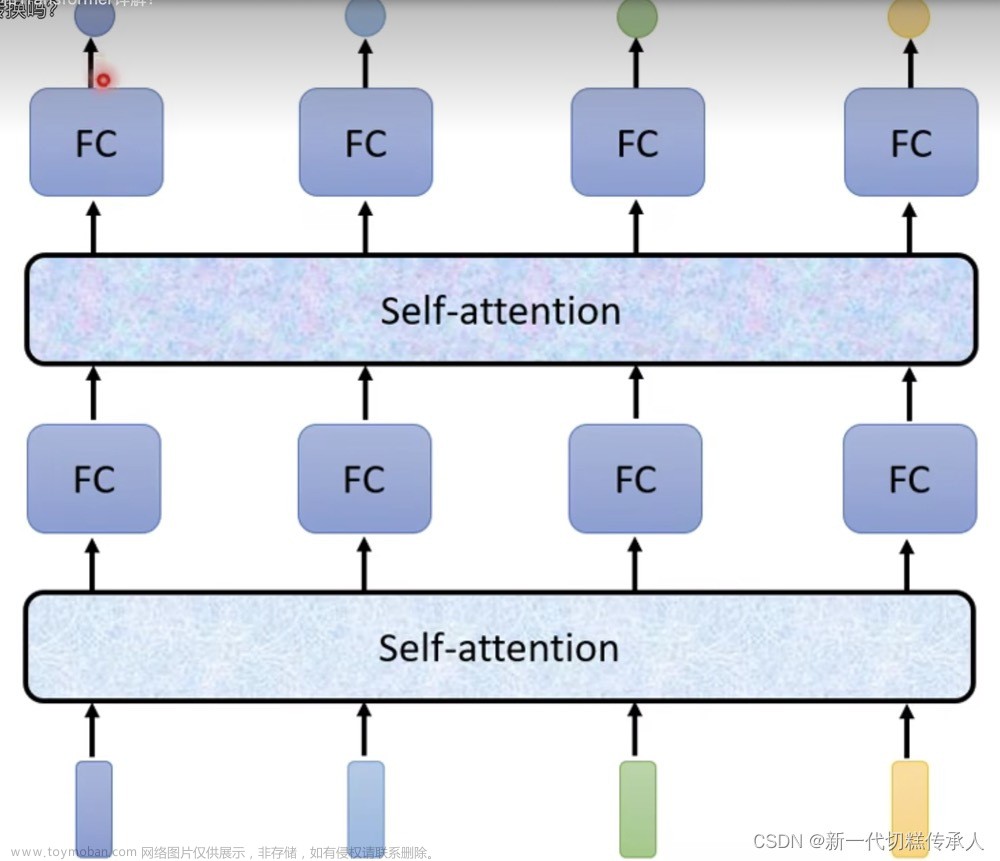
Transformer模型
Transformer的主要思想之一是避免RNN的顺序性并创建一个可在训练期间并行化的模型。这是通过实现两个思想来实现的:位置编码和使用自注意力机制来捕获模式,而不是使用RNN(或CNN)。这就是为什么介绍transformers的论文被称为“Attention is all you need”。
位置编码/嵌入
位置编码的思想是,当使用RNN时,标记的相对位置由步数表示,因此不需要明确表示。但是,一旦我们切换到注意机制,我们需要知道序列中标记的相对位置。为了获得位置编码,我们将标记的序列与序列中的标记位置一起增强(即一系列数字0,1,…)。然后,我们将标记位置与标记嵌入向量混合。为将位置(整数)转换为向量,我们可以使用不同的方法:
- 可训练嵌入,类似于标记嵌入。这是我们在此考虑的方法。我们在标记和它们的位置之上应用嵌入层,得到相同尺寸的嵌入向量,然后将它们相加。
- 固定的位置编码函数,如原始论文中所提出的

多头自注意力
接下来,我们需要捕获序列中的一些模式。为了做到这一点,transformers使用自注意力机制,它本质上是应用于相同的输入和输出序列的注意力机制。应用自注意力使我们能够考虑句子中的上下文,并查看哪些单词是相互关联的。例如,它使我们能够查看哪些单词被指代,以及考虑上下文:

在transformers中,我们使用多头自注意力来使网络能够捕获多种不同类型的依赖关系,例如长期与短期的单词关系,共指与其他关系等。
编码器解码器注意力
在transformers中,注意力应用于两个位置:
- 使用自注意力来捕获输入文本中的模式。
- 执行序列翻译时,它是位于编码器和解码器之间的注意力层。
编码器解码器注意力与RNN中描述的注意力机制非常相似。下面的动画图解释了编码器解码器注意力的作用。

由于每个输入位置都被独立地映射到每个输出位置,因此transformers可以比RNN更好地并行化,这使得更大、更具表现力的语言模型成为可能。每个注意力头可以用于学习不同的单词关系,从而提高下游的自然语言处理任务的效果。
BERT
BERT(双向编码器表示来自transformers)是一个非常大的多层变压器网络,BERT-base有12层,BERT-large有24层。该模型首先使用无监督的训练(预测句子中的掩码单词)在大量文本数据(维基百科+图书)上进行预训练。在预训练期间,模型吸收了大量的语言理解,这可以通过微调其他数据集来利用。这个过程被称为迁移学习。文章来源:https://www.toymoban.com/news/detail-487207.html
 文章来源地址https://www.toymoban.com/news/detail-487207.html
文章来源地址https://www.toymoban.com/news/detail-487207.html
到了这里,关于注意力机制和Transformer的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!