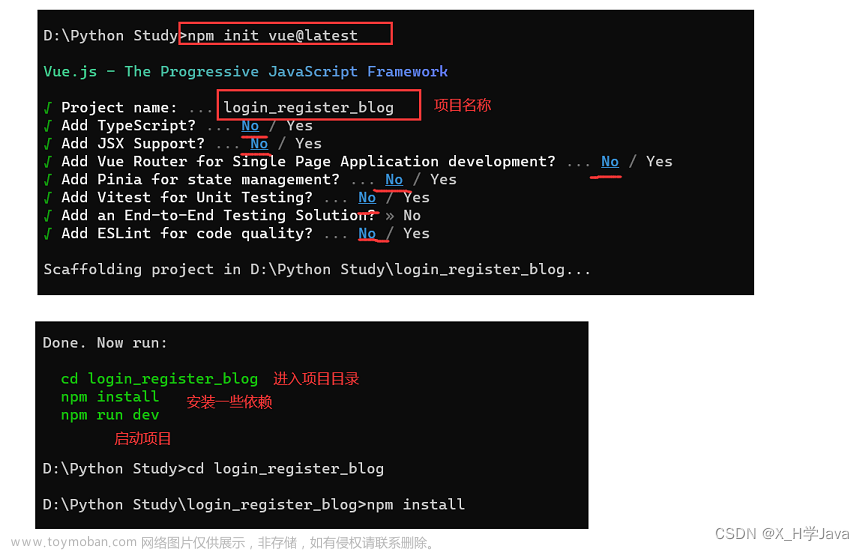
一:Django虚拟环境搭建
- 先在本地创建一个用来存放项目的路径
- 进入创建好的路径,创建虚拟环境
python -m venv djenv # 1.创建虚拟环境,djenv名称随意
- 进入虚拟环境
#
source djenv/bin/activate #Mac 进入激活虚拟环境
djenv\Scripts\activate.bat #Windows 进入激活虚拟环境
- 执行pip命令安装Django模块(最新版)
(Django模块 仅仅在 虚拟环境中,而不是安装在Python全局环境)
pip install Django
pip show Django#查看版本
- 创建Django项目
django-admin startproject 项目名
或者
python -m django startproject 项目名
- 创建app应用( 一般一个项目包含多个app应用程序(当然,通用的app也可以在多个项目中 使用。)
cd 项目名
django-admin startapp app应用名
或者
python -m django startapp app应用名
或者
python manage.py startapp app应用名
或者
python ../manage.py startapp system
- 注册app应用
app应用 程序创建以后,必须把 app 注册到 Django ,才能够被 Django 项目 所管理
我们只需要把app应用的名称,配置到 项目名/settings.py
文件中即可, 注意,最后面必须要有个逗号!
INSTALLED_APPS = [
"django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.messages",
"django.contrib.staticfiles",
'sign', # app应用名
]
7.1 .如果 应用多了,项目目录结构层次就不够清爽,所以项目根目录下创建包,然后再包下创建应用,比如创建apps包,system应用。
#创建应用
cd apps
python ../manage.py startapp system
- 需要修改修改 apps/system/apps.py 模块下的 SystemConfig 类
name 由 system 改为 apps.system
添加环境变量:在 settings.py 模块中,把 apps 包,添加到 sys.path 中(找个合适的位置),代 码如下
# 1.把apps目录设置到环境变量中
sys.path.insert(0, os.path.join(BASE_DIR, 'apps'))
- 启动Django项目
# [port] 为应用访问端口,可选,默认为8000端口(但酷狗音乐默认端口为 8000,因此我们最好指定端口)
python manage.py runserver [port]
二:Django视图与路由
1.Django视图
Django 视图的作用:用于接受Web请求并且返回Web响应的简单 Python 函 数。该函数一般定义在各自应用的 views.py 文件中。在视图函数中有两个重要 的对象:请求对象和响应对象。 下面是一个最简单的视图函数:
# 例:在demo/views.py 中
from django.http import HttpResponse
def index(request): #可写成req
return HttpResponse('我的第一个视图!Hello,World')
#render函数
def evnets(req):
event_list = Event.objects.all()
# 三个参数,第一个为request对象,第二个为模板名称,第三个为返回的数据(字典格式),.....
return render(req,'events.html',{'event_list': event_list})
2.Django路由
路由:就是请求向导,通俗点说就是用户请求的Url和视图的映射关系。
Django 的路由定义文件为:项目目录 /urls.py 文件。我们所有的路由配 置,都以数组的方式,定义在 urls.py 文件中,每个app应用下的/urls.py定义好之后,再汇总到项目下的 /urls.py
2.1路由分级
第一步:在各个应用的根目录下,创建 urls.py 文件(文件名可以自定义, 一般用 urls )
from django.urls import path
from app名 import views as sign_view #
urlpatterns = [
# 第一个参数:浏览器里的URL,第二个参数:应用里的函数名
path("events/", sign_view.evnets),
path("guest_detail/<int:guest_id>/", sign_view.guest_detail),
]
第二步:修改主路由,把其他应用的路由,通过include导入进来
from django.contrib import admin
from django.urls import path,include #1...导入include模块
#2...导入其他应用的urls模块
from 应用名 import urls as sign_urls
urlpatterns = [
path('admin/', admin.site.urls),
# 3...导入子路由 (参数1=父路由访问路径,参数2=导入子路由)
#第一个参数:浏览器中的更深一层url,第二个参数是应用名-别名
path("sign/", include(sign_urls)),
]
三:Django模型
1 .ORM概念
Object Relational Mapping (对象关系映射) 其主要作用是:在编程中,把面向对象的概念跟数据库中表的概念对应起来。
…当然这只是从对象到SQL的映射,还有从SQL到对象的映射,也是类似的过程。 有了ORM,我们不需要再写繁琐的sql语句,一切以 python 语法为准,通过ORM提供的API,就可以操作数据库。
Django 框架可以通过 ORM 模型,来创建数据库表。具体步骤如下:
- 安装mysql数据库需要的插件pip install mysqlclient
- 配置数据库信息( 项目目录/settings.py ),还需要更改时区
- 定义模型( 各应用目录/models.py )
class Case(BaseModel):#继承BaseModel类,也可以用models.Model
file_path= models.CharField('用例文件路径', max_length=1000, default='demo_case.json')
config=models.OneToOneField(Config, on_delete=models.CASCADE, related_name="cs")
#查询该模型结果对外展示字段
def __str__(self):
return self.config.name
#模型元类,指的是 除了字段外的所有内容 ,例如排序方式、数据 库表名等。所有的这些都是 非必须的 ,甚至元数据本身对模型也是 非必须的 在实际使用中具有重要的作用。
class Meta():
# abstract = True #抽象类,不会在数据库单独生成这张表
db_table = settings.TABLE_PREFIX+'case' #数据库表名
verbose_name = '用例表'
ordering = ['id'] #排序
- 控制台执行以下两个命令:
生成迁移文件(python manage.py makemigrations)
应用数据库迁移(python manage.py migrate)
mysql 数据库和时区配置为:
# 项目目录/settings.py DATABASES = {
# 数据库必须8以上,否则会报错
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'course_autotp_sixth', # 1.数据库名称
'USER': 'root', # 2.用户名
'PASSWORD': 'sq', # 3.密码
'HOST': '127.0.0.1',
'PORT': '3306',
'TEST': { # 4.Django在创建测试数据库时,防止中文乱码
'CHARSET': 'utf8',
'COLLATION': 'utf8_general_ci',
}
}
}
#时区配置
LANGUAGE_CODE = "zh-hans" # 语言 en-us zh-hans
TIME_ZONE = "Asia/Shanghai" # 时区 UTC Asia/Shanghai
USE_I18N = True
USE_TZ = False # 使用UTC时间
在ORM中,一张表就是一个模型类,因此我们可以在 应用名/models.py 文件 中,先定义一个类,必须继承django自带的模型基类**(models.Model)**
2.对数据库进行操作
数据库操作主要包括数据的:新增、删除、修改、查询。 我们可以使用 Django 自带命令行工具,进行模型类数据库操作:
python manage.py shell
首先,在需要执行数据库操作的 py文件 中,从相关应用的 models 模块引入 模型,如从 sign.models 模块中引入 Event 模型
from sign.models import Event
def xxx():
# 这里写数据库操作代码
也可以用tests模块对数据库进行测试,要注意的是这里操作不会真的对数据库
3.模型管理器
我们把: xxx模型类 . objects 称之为xxx模型的 模型管理器 。
3.1数据库操作
#新增
Event.objects.create(name='性能发布会',address='南京市花神大道23 号',limits=150)
event_dict = {'name':'测开发布会','address':'南京市鼓楼 区','limits':150}
Event.objects.create(**event_dict) # 解包
#查询
#例如1:查询 Event 表中的所有数据,返回 QuerySet 对象列表,代码如下:
eventList = Event.objects.all()
#例如2:条件过滤查询 Event 表中的数据,返回 QuerySet 对象列表,代码如 下:
eventList = Event.objects.filter(**kw) # 不加参数等同于all()
例如3:查询 Event 表中唯一数据(没有匹配结果或者匹配结果超过1条都会 报错),代码如下:
event = Event.objects.get(id=1) # 返回对象
#删除, limits 为100的数据
Event.objects.filter(limits=100).delete()
#修改
Event.objects.filter(limits=150).update(address='上海市')
#模糊查询
xx模型类.objects.filter(xxx字段名__xx关键字=xx值)
例如:
Event.objects.filter(limits__gte=100) # 人数大于等于100 Event.objects.filter(name__contains='双') # name 包含“双”字 Event.objects.filter(name__isnull=False) # name 不为空
4.数据库表关联
在关系型数据库中,表与表之间的关联关系,主要有三种:一对一,一对多,多对多 。
一对一:在任意一方,一般定义在次要的一方,用 models.OneToOneField 来定义。记住不能双方都定义
一对多:只能定义在多的一方,用models.ForeignKey 来定义
多对多:在任意一方,一般定义在后出现的,用 models.ManyToManyField 来定义。
【注意】定义在哪一方,哪一方就是字表
在模型中,设置好关联关系后, 为: 一对一、一对多的情况一样,在 中,会添加一个名称为【字段名_id】
的字段。如guest表中的event_id。 多对多不一样,在两个关联的模型表中,均不会添加字段,而是会出现一张中间
表,表名为:
【应用名 _ 模型1 _ 模型2】 如: sgin_guest_events ,其中模型1为定义的模型
5.on_delete外键策略
on_delete 外键策略,是解决当主表的数据删除时,从表的数据该如何处理的问 题。
外键删除策略有:
- on_delete = models.CASCADE :删除关联数据的时候,与之的关联也删除
- on_delete =models.PROTRCT :删除关联数据的时候,引发报错
- on_delete = models.SET_NULL :删除关联数据的时候,与之关联的值设置为空
- on_delete = models.DO_NOTHING :删除关联数据的时候,什么操作也不做
6.正向查询和反向查询
正向:子查父 子对象.父类名小写,就会返回一个父对象
反向:父查子 父对象.子类类名小写_set,就会返回一个【模块管理器】,也可以用别名(关联字段中related_name=别名),父对象.别名
#视图-》路由-》页面
class Department(models.Model):
title = models.CharField(verbose_name='部门',max_length=32)
class UserInfo(models.Model):
depart=models.ForeignKey(verbose_name='部
门',to='Department',related_name="u") #别名related_name ,正向查询没有影响,反向查询可以通过别名
departObj = Department.objects.get(id=9) departObj.userinfo_set.all()
user = models.CharField(verbose_name='用户称',max_length=32)
pwd= models.CharField(verbose_name='密码', max_length=256)
例如:部门表( Depart )和用户表( UserInfo )是一对多的关系,我们应该在多的一方(用户表),建立 Foreignkey 外键。这样, 多的一方通常也叫做 。根据子表(从表),来查找父表(主表)信息,我 们叫做 正向查询,和正向查询相反,通过父表(主表)来查询子表(从表),叫做 可以用.子表类名小写_set来查询
# 正向查询---用点就行
userObj = UserInfo.objects.get(id=1)
userObj.depart
# 反向查询---模型对象名小写_set
departObj = Department.objects.get(id=9)
depart_object.u.all()
# 报错,设置了 related_name别名后,原本的反向查询失效
departObj.userinfo_set.all()# 报错
四:Django的安全策略
CSRF跨站请求伪造,是一种常见的网络攻击手 段。 默认为我们开启了防范 攻击的机制,对于GET请求,一般来说没有这 个问题,通常是针对POST或PUT方法的。如果不做任何设置,在发送post请求时,会出
现 CSRF 验证失败,请求被中止
解决方法有以下三种(任选一种):
- 方法一: settings 文件的 MIDDLEWARE 中,去掉 CSRF 安全策略 【自废武功】
- 方法二:给视图函数添加装饰器@csrf_exempt: 【开后门】
- 方法三: Template 模板的表单内部加入 {% csrf_token %} 【正规流程】
五:Django的单元测试
- Django 的单元测试采用 Python 的标准模块: unittest 。该模块以类的形式定义 测试。 Django
继承了该模块并对其做了一定修改,使其能配合 Django 的特性做一些测 试 - 主要测试对象:数据模型
- 运行方法:
python manage.py test # 运行整个项目的测试用例
python manage.py test sign # 运行某个应用的测试用例
python manage.py test sign.tests # 运行某个模块的测试用例
python manage.py test sign.tests.xxxxClass
python manage.py test sign.tests.xxxxClass.xxxdef
- 测试文件:某 app 目录下的 tests.py 模块
- 特点
使用 Django 提供的 TestCase 类作为被继承类。注意这里不是 unittest 的 TestCa ,否则无法使用 django 的测试功能。
创建数据时采用的是测试数据库,并且会在测试结束后 ,测试行为不会影 响到真实的数据库。
六:数据库事务
例如:
# 3.签到保存
guest_obj.is_sign = True
guest_obj.save()
# 4.实际到场人数+1
event_obj.limits=event_obj.limits+1
event_obj.save()
以上代码片段共涉及到两次存数据库的操作,这两次存数据库的操作应该是一个原 子操作。即要么两次存数据库都成功,要么两次存数据库操作都失败。如果第一次修改 guest表成功,而第二次修改event表失败,这样就会导致发布会实际到场人数统计不一 致的bug。
【注意】在数据库中这种要成功就一起成功,要失败就一起失败的做法叫 ,如果这里签到成功但是后面的步骤失败了,那么数据库会发起回滚操作,将签到撤销。
在django中,可以用 with transaction.atomic(): 语句块实现事务操作。
with transaction.atomic():
# 4.签到=数据库更新
guest_obj.is_sign = True
guest_obj.save()
# 其他代码
# my_god = 10 / 0
# 5.修改发布会的已签到人数+1
event_obj.limits += 1
event_obj.save()
七:数据库设计
一个web项目,最核心的设计就是数据库结构的设计,因为一切都是围绕数据开 始。
1.项目中,我们采用 httprunner4 (简称 HR4 )作为 ,因此我们可以按 照 Yaml/JSON 的 ,来设计数据库。此次用例的设计用jsong格式,格式如下:
【注意】case和config是1对1 ;case和step是一对多;step和request是1对1
{ #4 case对象
"config":{ #3 config对象
"name": "案例名称",
"base_url": "http://#url",
"verify": "False",
"export": "[myCookie,courseId]导出变量",
"variables":" #全局变量 优先级大于parameters",
"parameters":" #参数化"
},
"teststeps":[
{ # 2 step对象1
"name": "",
"variables": [],
"extract": [],
"validate": [],
"request": { #1 request对象
"method": "POST",
"url": "/api/mgr/sq_mgr/",
"headers": { },
"cookies": { },
"body": {}
}
},
// # 2.step2对象2
。。。。。。
]
}
2.数据库模型图
(1)基础的


(2)完整项目
3.子类继承抽象类
用法:不想每个模型都定义审计字段
(1)__str__方法会被继承,可以把模型中的 str 方 法,也定义到基类中。
(2)Meta类继承
- 如果子类定义了 Meta 类,此时默认不继承基类的 Meta 类
- 如果子类没有定义 Meta 类,此时默认继承基类的 Meta 类
- 如果子类定义了 Meta 类,此时可以‘显示的’继承基类的 Meta 类
【注意】基类的有些属性不会被继承:abstract=True和db_table ;其他属性会被继承,但是如果定义了相同的属性,则子类优先
4.json字段操作
mysql8.0以上可以定义json字段,该字段可以像操作字典一样操作数据库 - 保存字典,列表,字符串
- 整体修改json字符串;局部修改某个字典的某一个key的值
- 整体删除;局部删除某个key,例如 obj.字段.pop(XXXkey’)
- 查询所有;查询某个字段 ,如果该字段是json形式,则 字段_key=XXX
八: RESTful API规范
RESTful 是目前最流行的 API设计规范 ,用于 Web 数据接口的设计。
- 动词+宾语原则,动词指的是 HTTP 请求方法,宾语类似/articles,
同一个宾语,动作不同,实现的功能也不同。如:
GET /projects 列出所有项目
POST /projects 新建一个项目
GET /projects/ID 获取指定的项目
PUT /projects/ID 更新一个项目
DELETE /projects/ID 删除一个项目
- 宾语必须是名词,不能是动词,/getAllCars/createNewCar/deleteAllCar都是错误的
- 避免多级url,不利于扩展,更好的做法是,除了第一级(有实质性意义),其他级别都用查询字符串表达,例如:GET /api代表后端接口/sqtp项目/cases/12?categories=2
- 返回规范: JSON 格式服务器回应的 HTTP 头的 Content-Type 属性要设为application/json 。客户端请求时,也要明确告诉服务器,可以接受 JSON 格式,即请求的 HTTP 头的ACCEPT 属性也要设成 application/json
- 宾语一般都用复数,这没有统一的规定
- 状态码,这里不遵守规则,自己进行定义
状态码:
成功情况下,状态码为200
失败情况下,状态码为200
异常情况下,状态码为400、404等
前端不能根据 状态码 进行判断,切记切记!
返回值code约定:
成功情况下, code 值为200
失败情况下, code 值为400
异常情况下, 值为400
如果未登录,则状态码为401
因此,前端可以根据 code的值 ,来进行判断:
如果 code 为401时,则自动跳转至登录界面
如果 code 不为200时,提示错误具体原因
如果 code 为200时,提示操作成功等字样
九:DRF框架入门
Django REST framework(以下简称 DRF 或 REST 框架)是一个开源的 Django 扩
展,提供了便捷的 REST API 开发框架
- 安装:
pip install djangorestframework
- 配置:项目名/settings.py,放在App名上面 rest_framework
- 运行原理:

- 组件Serializer
序列化( Serializer )是DRF的核心概念,提供了数据的验证和渲染功能,其工作
方式类似于 Django Form 。它的作用是实现序列化和反序列化。Django 在没有采用 DRF 之前, model 是直接与 views 交互的,如果采用了 DRF ,那么 model 将直接和 serializer 交互。
序列化:将一个数据结构类型(模型类对象)转换为其他格式(字典、列表、JSON、XML),我们把这个过程叫序列化。数据从数据库到网页页面,需要经过序列化处理
序列化
QuerySet列表或模型对象 -------------》python列表/python字典–》json字节串–》json字符串
反序列化 :将其他格式(字典、列表、JSON、XML等)转换为模型类对象,我们把
这个过程称之为反序列化。数据从网页页面到数据库,需要经过反序列化处理
python列表/python字典----------》模型类象-----》.is_valid()------》.save()
反序列化 合法检查 保存到数据库
- 序列化实例化规则
XXXSerializer(obj) : 表示序列化---对象
XXXSerializer(QuerySet,many=True) : 表示序列化---列表
XXXSerializer(data=xxxDict): 表示反序列化---新增时
XXXSerializer(data=xxxDict,instance=xxxObj): 表示反序列化---修改
修改也可以这样表示:
aaa =XXXSerializer(data=xxxDict)
aaa.instabce = xxxObj
- 实例化器常用的属性和方法:
data 属性:序列化后的数据。
is_valid() 方法:对数据进行校验(新增/修改之前, 必须调用 的)返回 True 或 False,
它会对传入的数据和序列化器字段进行比对校验。如果校验不通过则抛异常;如果校验通过,则触发钩子函数 validate() 方法。
errors 属性:校验不通过后,错误原因。
save() 方法:去调用 create() 方法或 update() 方法…
实例化序列化器的时候,当 instance 属性不为 None 时,调用 update() 方法。否则调用 create() 方法。
自定义方法的调用:序列化器的实例对象,都可以调用自定义方法。
十:序列化器和视图的真正使用
序列化器最终的作用是为视图提供转化后的数据
1.字段解析
#ModelSerializer :1.根据模型 自动生成 序列化器的字段,并设置了一些选项
#2.默认简单实现的 create() 和 update() 方法
class RequestSerializer(serializers.ModelSerializer):
class Meta:
model = Request
# fields = ['step', 'method', 'url', 'params', 'body'] #指定模型中哪些字段【给】序列化器
fields = '__all__' #表示模型中的字段,都【给】序列化器
# exclude = ['id'] # 排除某些字段
# read_only_fields = ['id'] # 只读字段
- fields 属性,它的取值有两种方式
第一种:字符串‘all’ 表示模型中的字段,都【给】序列化器
第二种:列表,用来指定模型中哪些字段【给】序列化器 - exclude属性,列表,排除 exclude 指定的模型中字段,其他字段都给序列号器,它不能和fields同时使用
- read_only_fields 字段:顾名思义,它是只读字段,值是一个列表。可以和 field s 、 exclude 一起使用
- 字段覆盖:如果 模型中 有A字段,我们又在 Serializer序列化器 中定义了A字段,那么自定义 的字段会 覆盖模型中的字段。这一点很好理解。但是要注意的是,定义的字段必须包含 在fields列表中
【注意】序列化器中有个required字段,是否必填,检验用的,校验的代码我们看不到,和模型中的有些定义规则有关系:
当模型中字段有默认值的情况下(default,auto_now,auto_now_add),序列化器中对应的字段是非必填的,即required=False ;
当模型中有字段指定了null=True ,序列化器中对应的字段是非必填的,即required=False ;
当模型中有字段指定了null=False且没有缺省值,序列化器中对应的字段是必填的,即required=True;
- read_only:只读 模型数据到序列化器
- write_only: 只写 序列化器数据到模型
xx = serializers.JSONField() #默认双向,即可以读 又可以写
xx = serializers.JSONField( read_only = True) #只读 模-》序
xx = serializers.JSONField( write_only= True) #只写 序-》模
例如:
id只读: 不需要从前端传到后端,因为id是后端自增的,数据库能读到外面,外面不能写入数据库
url:只写 ,数据库读取不出来,页面上不会展示
方法字段与实例属性
xxx :为字段名称,可以是对 原有某字段 的覆盖,或者一个 自定义字段
xx函数 :为自定义函数,它的返回值即为 该字段显示的内容
class xxxSerializer(serializers.ModelSerializer):
#方法字段:默认是 只读的 、 只读的
xxx=serializers.SerializerMethodField(method_name='xx函数')
def xx函数(self,instance):
...
return xxxx
默认情况下,在视图集调用某序列化器类,进行 实例化时 。无法将视图集中的 r equest 对象,传给序列化器实例内部,供其他方法使用。此时,我们可以通过给序 列化器定义 实例属性 ,来解决。
支持对序列化器:
目前,我们都清楚,视图集中自动实现的五个 API ,都用的是同一个序列化器。而序 列化器会影响到序列化数据和新增、修改时的数据校验。有些场合(比如: RoleViewSet 中),我们可能希望:查询相关的 API 用序列化器A;新增 API 用序列化器B;修改 API 用 序列化器C。步骤如下:
(1)视图集基类中,新增2个变量
(2)视图集基类中,重写 get_serializer_class 方法
(3)视图集中指定
2.视图
新增和查询所有 一个接口
查看某条数据/删除/修改 一个接口
A. 函数视图(1%)
B. 函数视图+装饰器(10%)
C. 类视图(1%)定义2个类
D. 通用类视图 (1%)
E. 视图集 87% (写3行代码,就能够实现【某张表】的增删改查查)
下面针对视图集作出详细解释
# 新增、列出所有数据 + 查看详细/删除/修改 5个接口
#修改删除 ,需要加 斜杠,例如requests/5/
class RequestE(viewsets.ModelViewSet):
queryset = Request.objects.all()
serializer_class = RequestSerializer
【注意】为了解决视图集的 问题,我们可以对视图集的 进行重写
应用中url配置:
# 配合视图集使用
router=DefaultRouter()
# 参数1=请求的路径,参数2=视图集类名
router.register('requests',views.RequestE)
urlpatterns = [
# # 视图集,需要配合DefaultRouter使用
path('',include(router.urls)),
]
DRF 视图集,默认提供了(增删改查查) 五个API 。如果默认的 API 不满足需 求,需要添加 额外的API 怎么处理呢?
比如,测试用例模块,需要添加 执行测试用例API ;菜单模块需要添加 获取用户菜 等。
DRF 提供了 rest_framework.decorators.action装饰器 ,可以为视图集中的 自 定义函数 生成路由信息。
class CaseViewSet(viewsets.ModelViewSet)
@action(methods =['GET'], detail =False, url_path='web_router')
def caoqq(self,request):
print('登录用户:',request.user)
十一: 统一API接口返回规范
前言:视图集五个接口返回的是默认JSON格式,不完全符合我们的需求,也不利于前端 的渲染,也不符合 RESTFull 规范,我们应该制定 API接口响应规范 。响应规范包括 对象数组 、 单个对象 、 返回异常 、 未登录情况 。
#规范1:对象数组
#在调用列出全部 API 接口时,后端返回的数据为对象数组
{
"code": 200,
"msg": "xxx",
"result": {
"data": [],
"total": 20,
"page": 1,
"limit": 10
}
}
#规范2:单个对象
#在调用新增、修改、查看详细 API 时
{
"code": 200,
"msg": "",
"result": {}
}
#规范3:返回异常
{
"code": 400,
"msg": "xxx",
"result": null
}
#规范4:未登录
{
"code": 401,
"msg": "身份认证信息未提供。",
"result": null
}
定义响应类:
ResponseOk类 :继承 DRF 的 Response类 ,用于返回单个对象
ResponseList类 :继承 DRF 的 Response类 ,用于返回对象列表
ResponseError类 :继承 DRF 的 Response类 ,用于返回所有异常信息(含未登录异 常),举例:
# 1.返回单个对象
class ResponseOk(Response):
def __init__(self, data=None, msg='success',status=None,
template_name=None, headers=None,
exception=False, content_type=None):
std_data={
'msg': msg,
'code': 200,
'result': data
}
super().__init__(std_data,status,template_name,headers,exception,content_type)
十二:REST异常处理机制
如果想返回异常信息,需要了解下 REST 异常处理机制。 REST 默认情况可以处理的异常有:
- 在 REST framework 内部产生的 APIException 的子类异常
- 原生 Django 的 Http404 异常
- 原生 Django 的 PermissionDenied 异常
提取异信息据具体步骤为:
(1)自定义异常处理函数
(2)配置异常处理函数:在项目/settings.py
REST_FRAMEWORK = {
# 替换成自定义异常处理
'EXCEPTION_HANDLER':'utils.exception.my_exception_handler',
}
十三: 集成Swagger在线接口文档
安装:pip install -U drf-yasg # 安装最新版的drf-yasg
注册:在项目/settings.py。 静态配置文件下 ‘drf_yasg’
路由配置:项目/urls下
from django.contrib import admin
from django.urls import path, include
from drf_yasg.views import get_schema_view
from drf_yasg import openapi
from rest_framework import permissions
# 1.设置文档的摘要
schema_view = get_schema_view(
openapi.Info(
title="autotp API",
default_version='v1',
description="autotp接口文档",
terms_of_service="https://www.caoqq.net",
contact=openapi.Contact(email="caoqq@sqtest.org"),
license=openapi.License(name="xxx License"),
),
public=True,
permission_classes=(permissions.AllowAny,),
)
urlpatterns = [
path("admin/", admin.site.urls),
path("api/",include('autotp.urls')),
# 3.互动模式访问路径
path('swagger/', schema_view.with_ui('swagger', cache_timeout=0, ),
name='schema-swagger-ui'),
# 4.文档模式访问路径
path('redoc/', schema_view.with_ui('redoc', cache_timeout=0),
name='schema-redoc'),
]
十三:JWT实现用户登录
开发思路:开发一个功能,我们首先应该分析功能 所需的模型 ,模型定义完成后,再去写序列器 、 视图集 、 路由 等代码。
1.定义用户模型
Django自带的有用户表 ( auth_user ),但是字段不满足需求,考虑 继承 它的模型。
继承:就是继承它的 抽象模型 ,在抽象模型的基础上,定义自己的字段
2.定义好用户模型后,我们需要告诉 Django ,把用户模型切换为自己应用下的用户 模型( system.User ),在 settings.py 模块中,添加如下设置(末尾处):
AUTH_USER_MODEL = 'system.User'
3.迁移数据库时如果报错,,则参考如下解决方式:
- 删除 migrations 目录( autotp 和 apps/system 下的)
- 删除数据库并重新创建新数据库
- 再执行迁移就可以了
python manage.py makemigrations autotp
python manage.py makemigrations system
python manage.py migrate
- 为什么使用JWT
不需要使用数据库,无需为不同的服务器重新生成令牌
(是 JSON Web Token 的简称)包含三个主要部分,即 Header 、 Payload 和Signature。 - 安装
pip install djangorestframework-simplejwt
- 在 settings.py 模块中配置认证方案
十四:DRF 身份/权限组合认证
1.身份认证(途径认证)
根据用户的 登录方式 进行认证。常用的有:Session 认证, Token 认证, JWT Token 认证
2.权限认证
用户登录、用户注册、找回密码、获取验证码等:允许所有用户
其他API:通过认证的用户
- AllowAny :允许所有用户(包括登录的、未登录的)
- IsAuthenticated :通过认证的用户(登录的任何用户)
- IsAdminUser :仅管理员用户
- IsAuthenticatedOrReadOnly :通过认证的用户可以完全操作,未登录的可以访问GET请求
3.认证失败会有两种可能的返回值:
401 Unauthorized 未认证
403 Permission Denied 权限被禁止
【注意】身份和权限认证要结合一起用,身份是根据权限来的,没有权限认证,就没必要查身份认证,任何人都可以围观, 身份是根据哪种途径买门票,正规渠道,让进,黄牛 不让进
4.配置
全局身份/权限认证,顾名思义,给项目添加 全局身份/权限认证 后, 所有API 都将 采用全局的认证策略。利用这一特点,我们可以把认证方式 占比多的 (本系统为:通过 认证的用户),设置为 全局认证策略 。在 settings.py 文件中,找到 REST_FRAMEWORK 项,添加全局身份/权限认 证
5.过滤/搜索/排序
- 过滤 :又叫 分类查询 、 条件查询 。指对指定字段,进行查询操作(精准匹配、模糊 匹配、范围查询等),这个 DRF框架 实现不了,只能依赖第三方插件( django-filt)
安装:pip install django-filter
注册:
【注意】默认的过滤器类 仅提供 精确查询操作。若需要实现按 范围查询 、 模糊查询 等功 能,则必须使用 自定义 过滤器类。 - 搜索 :前端可根据 关键字 搜索(从一个或多个字段中)。 DRF框架 提供了
- 排序 :前端可根据 查询字符串(ordering) 来控制数据的排序。 DRF框架 提供了
在视图集中使用:
# 过滤、搜索、排序的后端
filter_backends = [DjangoFilterBackend, SearchFilter, OrderingFilter]
filterset_fields = [] # 指定过滤指定
search_fields = [] # 指定搜索范围,会暴露一个search参数,可以用来搜索
ordering_fields = [] # 指定排序字段,会暴露一个ordering参数,可以用来排序
测试-过滤:
http://127.0.0.1:8100/api/requests/?method=POST&url=/demo
测试-搜索:
http://xxx:8000/api/requests/?search=P # 搜索 method或url中包含“P”字的
http://xxx:8000/api/books/?search=d # 搜索 title或author中包含“d”字的
测试-排序
http://xxx:8100/api/requests/?ordering=method # 按method升序排序
http://xxx:8100/api/requests/?ordering=-method # 按method降序排序
http://xxx:8100/api/requests/?ordering=-method,url # 按method降序再按url
升序
十五:数据初始化
项目开始时, 并不是 所有表都是 空的 。有些表是 需要有初始化数据 的。如: 部
门表 、 菜单表 、 角色表 、 用户表 等。
数据初始化实现方式很多,如:
- 编写sql 脚本,把要插入的 数据写在sql脚本 中。
- 编写 python 类,通过 python 类 调用数据库 进行操作
- 编写 python 类,通过 python 类 调用序列化器 进行操作 (常见)
Django 还提供了 django.setup() 函数,我们可以在模块中进
入 Django 环境。
十六:验证码功能
- 安装captcha库:pip install django-simple-captcha
- 注册app
- 数据库迁移
python manage.py makemigrations
python manage.py migrate - 参数配置
- 编写试图
- 编写路由
十七:跨域处理
跨域是指:浏览器不能执行其他网站的脚本。这是浏览器的同源策略造成的
(Access-Control-Allow-Origin访问控制允许来源),是浏览器的安全限制。所谓同
源,是指 域名 、 协议 、 端口 均相同。否则都需要做跨域处理。
例如:前后端这三项有不同
在 后端项目 中处理(推荐)
django-cors-headers 是一个处理跨域请求的Django应用,通过它可以为响应
添加跨域资源共享。
- 安装:
pip install django-cors-headers - 在 settings.py 的 MIDDLEWARE 的最前面添加:
'corsheaders.middleware.CorsMiddleware' - 在 settings.py 中(位置随意),添加:
CORS_ORIGIN_ALLOW_ALL = True ## 1.如果为True则讲不使用白名单,并接受所有来源的请求,默认False
# 2.白名单
# CORS_ORIGIN_WHITELIST=[
# "http://localhost:5173",
# "http://121.121.121.12:9090",
# ]
十八:用例树API
API功能为:根据传入的 项目ID ,获取测试用例列表(含步骤),并转换为树形 结构。
十九:生成用例文件
一个测试用例对应一个 JSON文件,实现把数据库数据序列化为字典,再把字典转换成JSON字节串后,再写入到文件中。
二十:总结
1.视图集
1.1:封装视图集的目的
- 统一设置响应消息返回格式(最主要的)
- 统一设置过滤、搜索、排序后端
- 统一添加数据权限、菜单权限
- 方便新增、修改时,指定不同的序列化器
1.2.五种类型的视图
- 函数视图
- 函数视图+@api_view装饰器
- 类视图-继承APIView
- 通用类视图-继承generics.*
- 视图集-继承ModelViewSet
1.3. 给视图集添加其他api的方法
DRF提供了action装饰器,用于给视图集中的函数添加路由
2.模型文章来源:https://www.toymoban.com/news/detail-487565.html
2.1封装模型的目的文章来源地址https://www.toymoban.com/news/detail-487565.html
- 统一定义审计字段,
- 减少冗余(最主要的) 统一定义ID主键为字符类型,默认值为32位的uuid
2.2模型的三种关联关系 - 一对一:关联字段定义在任意一方。一般定义在 后出现 的一方。数据库表现为: 字段名 _id
- 一对多:关联字段定义在 多的一方 。数据库表现为: 字段名_id
- 多对多:关联字段定义在任意一方。一般定义在 后出现 的一方。数据库表现为:中间表
6.3模型字段选项 - verbose_name
- max_length
- choices
- related_name
- blank
- default
- null
- auto_now_add/auto_now 等
当模型中字段选项存在:default、auto_now_add、auto_now、 null=True 之一时,序列 化中该字段会被 自动 指定为 非必填 字段
3.序列化器
3.1封装序列化器目的 - 统一给序列化器,添加实例属性: request
- 统一处理:创建者/修改者/所属部门问题(最主要的)
3.2常用序列化器字段 - 大部分字段和模型字段一致
- SerializerMethodField:方法字段,只读,通常用于返回下拉列表汉字等
- PrimaryKeyRelatedField:主键关键验证字段
- SlugRelatedField:关联目标字段
3.3序列化器常用选项 - read_only:只读
- write_only:只写
- required:值为False表示必填
- max_length:最大长度
- validators:验证器
- source:模型字段名,不指定时默认定义的字段名和模型的字段名一致 等等
3.4序列化器验证顺序
当使用序列化器进行 反序列化 实现新增/修改功能时,首先会调用序列化默认的验证方 法,再调用validate_xxxfield()函数,最后调用validate()函数。
3.5 什么时候需要重写create() 或update()方法
当前端提交的 JSON数据 ,是对两个或两个以上模型进行操作时,需要重写 create() 或 update() 方法。
如:
测试用例新增/修改时,涉及到Case模型和Config模型。因此需要重写 create()与 update() 方法。
3.6什么时候需要单独定义新增/修改序列化器
有时候,业务逻辑比较复杂,查询/新增/修改操作时,要求的字段不一致。比如:修 改Step和新增Step,有一定的差别。新增时,会传入 belong_case_id ,修改时不需要。
到了这里,关于Python之Django的基本使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!