简介
在使用 Stable Diffusion 的时候,可以选择别人训练好的 Lora,那么如何训练自己的 Lora,本篇文章介绍了介绍了如何训练Lora,如何从训练的模型中选择好的模型,如何在 Stable Diffusion 中使用。
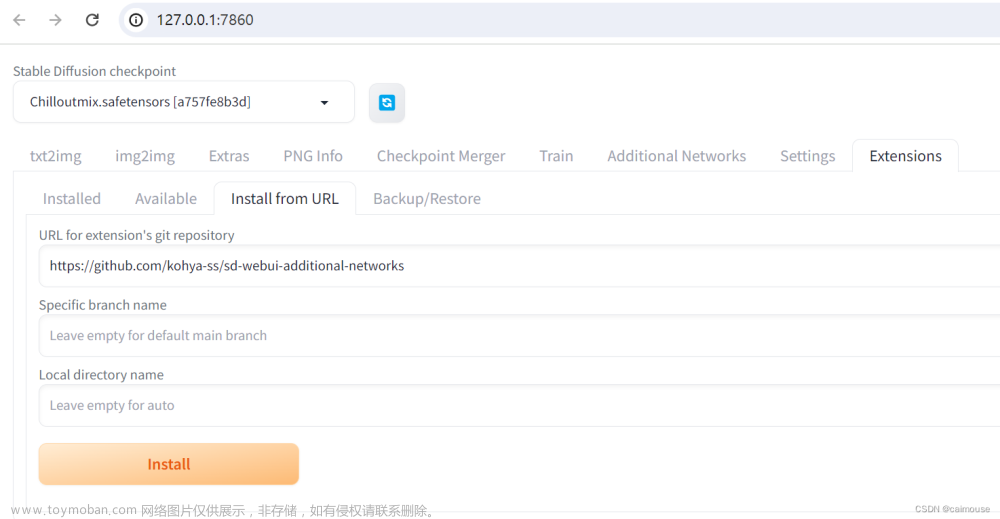
闲话不多说,直接实际操作吧,干货满满,记得关注哦,以免找不到了。首先我们来获取代码
Lora训练代码
github
git clone --recurse-submodules https://github.com/Akegarasu/lora-scripts
如果发现子包没下载,可以再更新子包
git submodule update --init --recursive
用conda创建环境
创建Python 3.10.8的环境
conda create -n lora_train python=3.10.8
Windows 安装
运行 install.ps1
将自动安装必要的包。

准备训练数据
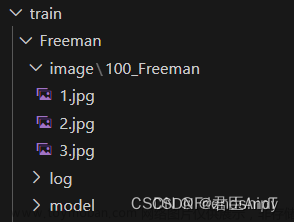
把图片准备好,我做了20张图片,把图片目录放到如图
图片大小如果是长图可以用,512x768,512x640,要是64的倍数
正方行的图就可以用512x512
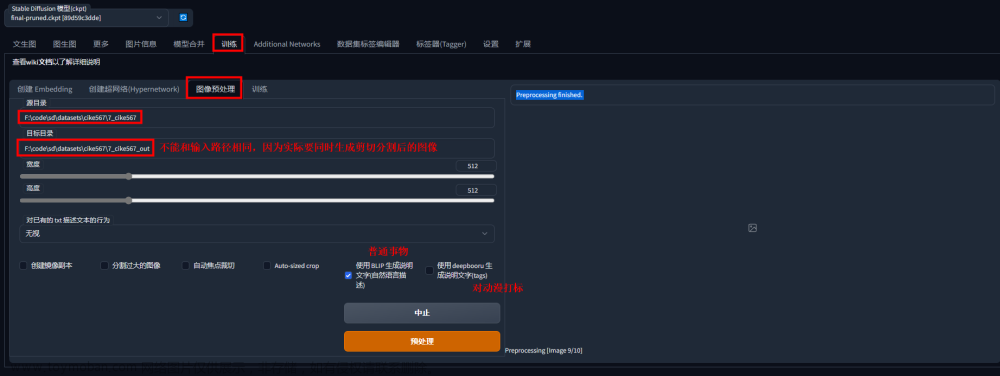
勾选上裁切,以及生成信息
素材生成结果
全部剪切为512x768,并生成了tag信息存在了txt文件下

新建文件夹train,把图片拷贝到该文件夹下
并起一个文件夹名字为20_train,这里的20是有必要的,是每轮20步训练
 文章来源:https://www.toymoban.com/news/detail-487627.html
文章来源:https://www.toymoban.com/news/detail-487627.html
训练数据
更多内容查看文章文章来源地址https://www.toymoban.com/news/detail-487627.html
到了这里,关于Stable Diffusion 指定模型人物,Lora 训练全流程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!