仅仅是小编总结的三点而已,可能不是很全面,如果之后小编了解到新的知识点,可能还会增加的哈!
1. 最简单的爬虫代码
也就是各位最常使用的,直接利用requests模块访问当前网站链接,利用相关解析模块从而获取得到自己想要的数据,如下(利用python爬虫爬取自己csdn个人主页的简介数据):
# -*- coding: utf-8 -*-
import requests
from lxml import etree
url = 'https://blog.csdn.net/qq_45404396'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.199.400 QQBrowser/11.8.5300.400'
}
rsp = requests.get(url=url,headers=headers)
html = etree.HTML(rsp.text)
info = html.xpath('//p[@class="introduction-fold default"]/text()')[0]
print(info)
运行结果:
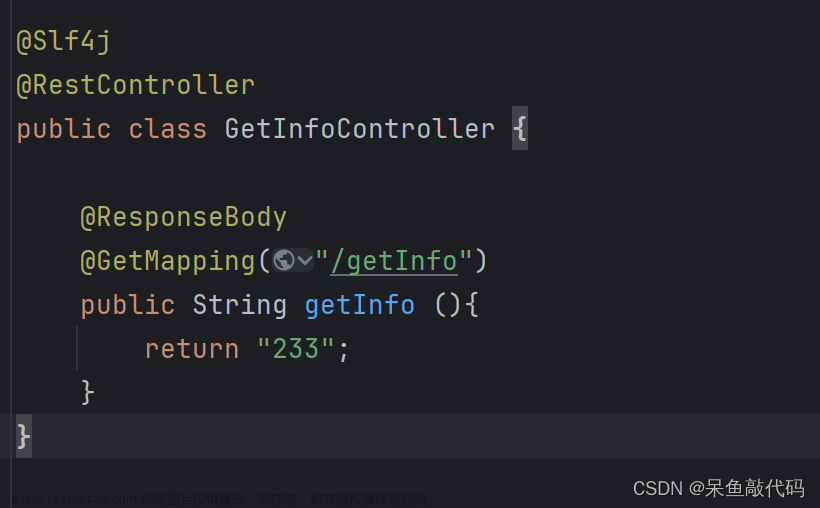
下面展示它的后端实现,只是举个例子哈!利用SpringBoot+thymeleaf模拟哈!java代码和前端界面代码如下:
package com.example.demo.controller;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import java.util.HashMap;
@Controller
public class TestController {
@GetMapping("/test1")
public String test1(Model model){
HashMap<String,Object> map = new HashMap<>();
map.put("name","liuze");
map.put("age",22);
model.addAttribute("data",map);
return "test1";
}
}
这里没有定义一个相关的实体类了,直接使用hashmap
<!DOCTYPE html>
<html lang="en" xmlns:th="https://www.thymeleaf.org/">
<head>
<meta charset="UTF-8">
<title>test1</title>
</head>
<body>
<p th:text="${data.name}">
</p>
<p th:text="${data.age}"></p>
</body>
</html>
界面效果如下:

这两个数据你直接访问这个界面是可以获取得到的(如果部署到公网上去的话!),你可以直接去查看这个界面的源代码或者来到开发者工具下点击网络->全部下,找到当前界面的链接,点击,然后点击响应,如下:
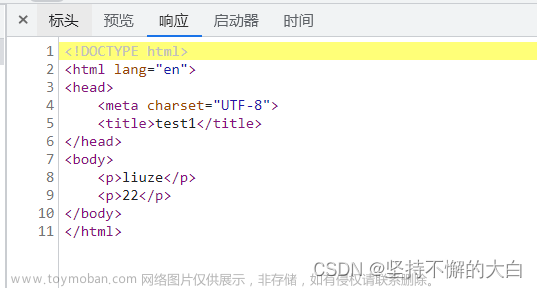

通常可以通过上述这种方式判断你直接访问当前网页链接是否可以获取得到你想要的那些数据。
2. 需要到script标签去找数据
其实,也就是你想要的那个数据在一个script标签内,也就是说如果你在第1中情况下你没有找到你想要数据,这时候你可以去找找某个script标签下是否有你想要的数据。比如小编我想要获取我的csdn个人主页的各个勋章的名称,可以发现,在某个script标签下有你想要的数据,如下:
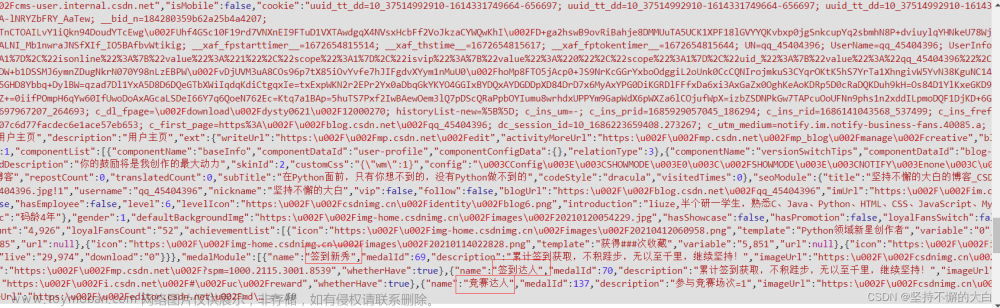
它的这个勋章实现效果我想应该是这样的,后端使用和方法1相同,只不过没有把相关数据写入到对应标签内,而是先把数据写到一个script标签内,然后利用编写js脚本加以展示。python代码抓取如下:
# -*- coding: utf-8 -*-
import requests
from lxml import etree
import json
url = 'https://blog.csdn.net/qq_45404396'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.199.400 QQBrowser/11.8.5300.400'
}
rsp = requests.get(url=url,headers=headers)
html = etree.HTML(rsp.text)
info = html.xpath('//script/text()')[0]
index = info.find('=') + 1
_dict = json.loads(info[index:-1].strip())
_list = _dict['pageData']['data']['baseInfo']['medalModule']
count = 0
for e in _list:
print(e['name'], end=' ')
if count and count % 8 == 0:
print('\n')
count += 1
运行结果:

这种后端实现和上述一致,看看前端代码:
<!DOCTYPE html>
<html lang="en" xmlns:th="https://www.thymeleaf.org/">
<head>
<meta charset="UTF-8">
<title>test1</title>
</head>
<body>
<p class="p1"></p>
<p class="p2"></p>
<script th:inline="javascript">
var data = [[${data}]];
document.querySelector('.p1').innerText = data.name;
document.querySelector('.p2').innerText = data.age;
</script>
</body>
</html>
运行结果:
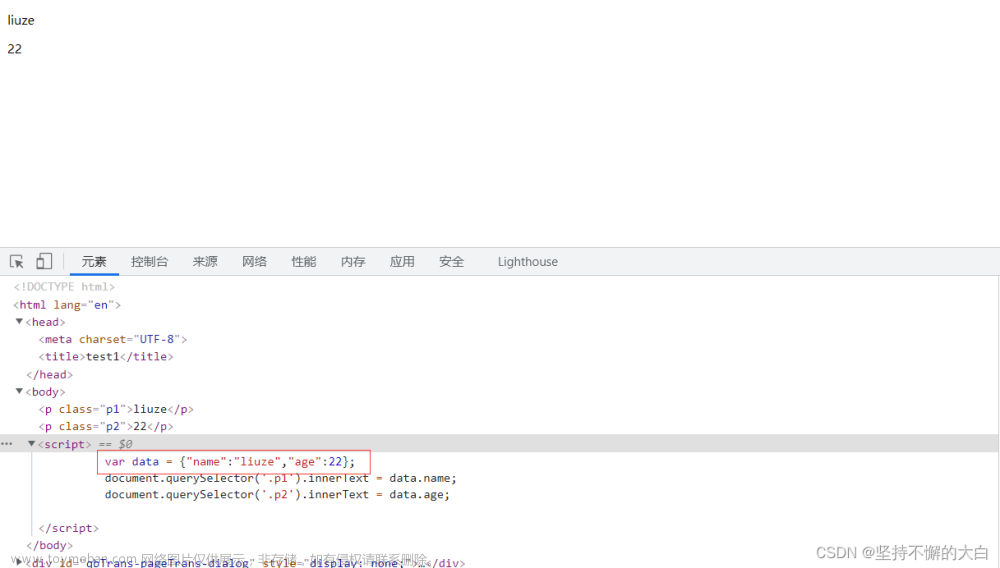
3. 找ajax请求接口
如果通过上述两种方式,你还没有找到你想抓取的数据线索,你可以去看看网络->XHR(或JS)下有没有ajax链接接口了。比如我想抓取我的个人主页下的一些博客名称,这需要去找ajax链接接口了。
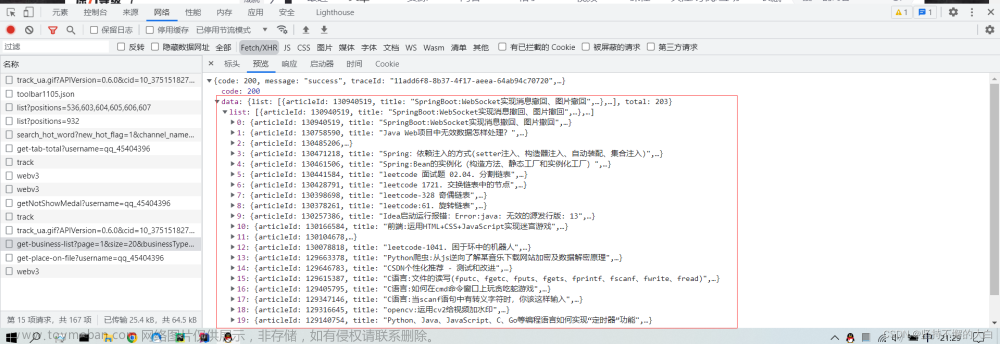
代码实现:
# -*- coding: utf-8 -*-
import requests
import json
url = 'https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=qq_45404396'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.199.400 QQBrowser/11.8.5300.400'
}
rsp = requests.get(url=url,headers=headers)
_dict = json.loads(rsp.text)
_list = _dict['data']['list']
for e in _list:
print(e['title'])
运行结果:
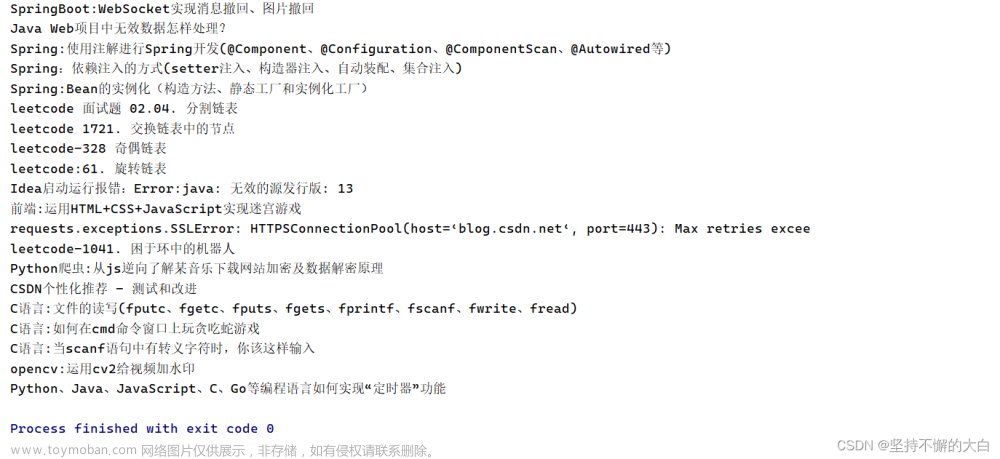
这种后端实现如下:
package com.example.demo.controller;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import java.util.HashMap;
import java.util.Map;
@Controller
public class TestController {
@ResponseBody
@GetMapping("/test2")
public Map<String,Object> test1(Model model){
Map<String,Object> map = new HashMap<>();
map.put("name","liuze");
map.put("age",22);
return map;
}
@GetMapping("/test1")
public String test2(Model model){
return "test1";
}
}
前端代码如下:
<!DOCTYPE html>
<html lang="en" xmlns:th="https://www.thymeleaf.org/">
<head>
<meta charset="UTF-8">
<title>test1</title>
</head>
<body>
<p class="p1"></p>
<p class="p2"></p>
<script th:inline="javascript">
fetch('/test2',{
method:"get",
}).then(res=>{
return res.json();
}).then((res)=>{
document.querySelector('.p1').innerText = res.name;
document.querySelector('.p2').innerText = res.age;
});
</script>
</body>
</html>
运行结果:
之所以后面两种情况,直接访问当前页面链接你访问不到相关数据,我想和页面加载顺序是有一定关系的,当然,这个点我也不是很清楚,希望上述所讲能帮助到大家哈!
4. 总结
下述为AI对于为什么爬虫爬取不到数据的分析:
有很多原因可能导致你的爬虫爬取不到数据,以下是一些常见的原因:
-
网站防爬虫机制:有些网站会设置反爬虫机制,如验证码、IP限制等。如果你的爬虫被识别为恶意行为,就会被禁止访问。
-
网络问题:如果你的网络连接不稳定,可能会导致爬虫访问失败或超时。
-
使用的爬虫框架或库问题:如果你使用的框架或库存在bug或者配置不正确,可能会导致爬取失败。
-
页面结构变化:有些网站的页面结构可能会不断变化,如果你的爬虫不及时更新,可能导致爬取失败。文章来源:https://www.toymoban.com/news/detail-487693.html
-
数据提取规则错误:爬虫需要根据网页的结构和规则提取数据,如果你的规则设置不正确,可能会导致爬取不到需要的数据。文章来源地址https://www.toymoban.com/news/detail-487693.html
到了这里,关于Python爬虫:从后端分析为什么你爬虫爬取不到数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!